python爬虫的数据库连接问题【推荐】
1.需要导的包
import pymysql
2.# mysql连接信息(字典形式)
db_config ={
'host': '127.0.0.1',#连接的主机id(107.0.0.1是本机id)
'port': 3306,
'user': '****',
'password': '****',
'db': 'test',#(数据库名)
'charset': 'utf8'
}
3.# 获得数据库连接
connection = pymysql.connect(**db_config)
connection()具体的基础知识详见连接
https://www.jb51.net/article/142550.htm
4.具体连接(以简书为例)
try:
# 获得数据库游标(游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。)
with connection.cursor() as cursor:
sql = 'insert into simplebook(title, url) values(%s, %s)'
for u in urls:
# 执行sql语句
cursor.execute(sql, (u.string, r'http://www.jianshu.com'+u.attrs['href']))
# 事务提交
connection.commit()
finally:
# 关闭数据库连接
connection.close()
5.连接数据库成功,并得到数据
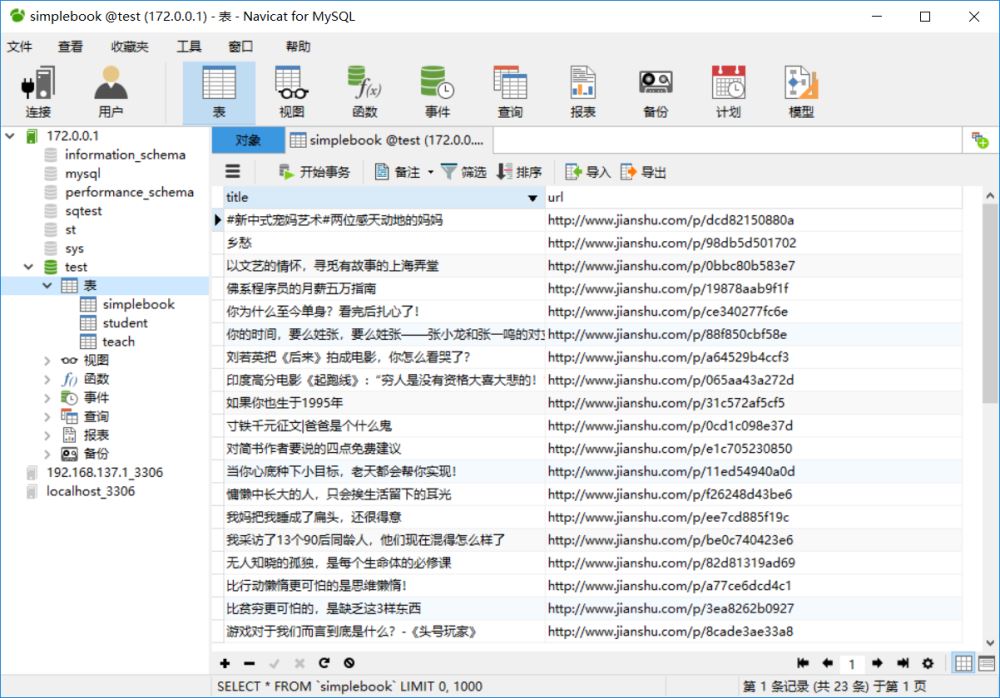
总结
以上所述是小编给大家介绍的python爬虫的数据库连接问题,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能.分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站python3安装与配置相关文章. 首先需要安装requests和lxml和json三个模块 需要手动创建d.json文件 代码 import requests from lxml import etree
-
Python3爬虫学习之MySQL数据库存储爬取的信息详解
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息.分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用. 这里,数据库选择MySQL,采用pymysql 这个第三方库来处理python和mysql数据库的存取,python连接mysql数据库的配置信息 db_
-
Python3爬虫学习之应对网站反爬虫机制的方法分析
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法.分享给大家供大家参考,具体如下: 如何应对网站的反爬虫机制 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略. 例如打开搜狐首页,先来看一下Chrome的头信息(F12打开开发者模式)如下: 如图,访问头信息中显示了浏览器以及系统的信息(headers所含信息众多,具体可自行查询) Python中urllib中的request模块提供了模拟浏览器访问的功能,代码如下: from
-
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
Python3实现爬虫爬取赶集网列表功能【基于request和BeautifulSoup模块】
本文实例讲述了Python3实现爬虫爬取赶集网列表功能.分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站前面关于python3安装与配置相关文章. 首先需要安装request和BeautifulSoup两个模块 request是Python的HTTP网络请求模块,使用Requests可以轻而易举的完成浏览器可有的任何操作 pip insta
-
Python3爬虫学习之爬虫利器Beautiful Soup用法分析
本文实例讲述了Python3爬虫学习之爬虫利器Beautiful Soup用法.分享给大家供大家参考,具体如下: 爬虫利器Beautiful Soup 前面一篇说到通过urllib.request模块可以将网页当作本地文件来读取,那么获得网页的html代码后,自然就是要将我们所需要的部分从杂乱的html代码中分离出来.既然要做数据的查找和提取,当然我们首先想到的应该是正则表达式的方式,而正则表达式书写的复杂我想大家都有体会,而且Python中的正则表达式和其他语言中的并没有太大区别,也就不赘述了
-
Python3爬虫学习入门教程
本文实例讲述了Python3爬虫相关入门知识.分享给大家供大家参考,具体如下: 在网上看到大多数爬虫教程都是Python2的,但Python3才是未来的趋势,许多初学者看了Python2的教程学Python3的话很难适应过来,毕竟Python2.x和Python3.x还是有很多区别的,一个系统的学习方法和路线非常重要,因此我在联系了一段时间之后,想写一下自己的学习过程,分享一下自己的学习经验,顺便也锻炼一下自己. 一.入门篇 这里是Python3的官方技术文档,在这里需要着重说一下,语言的技术文
-
python爬虫的数据库连接问题【推荐】
1.需要导的包 import pymysql 2.# mysql连接信息(字典形式) db_config ={ 'host': '127.0.0.1',#连接的主机id(107.0.0.1是本机id) 'port': 3306, 'user': '****', 'password': '****', 'db': 'test',#(数据库名) 'charset': 'utf8' } 3.# 获得数据库连接 connection = pymysql.connect(**db_config) conn
-
33个Python爬虫项目实战(推荐)
今天为大家整理了32个Python爬虫项目. 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- 豆瓣读书爬虫.可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1
-
Python爬虫自动化获取华图和粉笔网站的错题(推荐)
这篇博客对于考公人或者其他用华图或者粉笔做题的人比较友好,通过输入网址可以自动化获取华图以及粉笔练习的错题. 粉笔网站 我们从做过的题目组中获取错题 打开某一次做题组,我们首先进行抓包看看数据在哪里 我们发现现在数据已经被隐藏,事实上数据在这两个包中: https://tiku.fenbi.com/api/xingce/questions https://tiku.fenbi.com/api/xingce/solutions 一个为题目的一个为解析的.此url要通过传入一个题目组参数才能获取到当
-
Python爬虫定时计划任务的几种常见方法(推荐)
记得以前的Windows任务定时是可以正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起.接下来记录下Python爬虫定时任务的几种解决方法. 1.方法一.while True 首先最容易的是while true死循环挂起,不废话,直接上代码: import os import time import sys from datetime import datetime, timedelta def One_Plan(): # 设置启动周期 Second_update_time = 24
-
python爬虫框架feapde的使用简介
1. 前言 大家好,我是安果! 众所周知,Python 最流行的爬虫框架是 Scrapy,它主要用于爬取网站结构性数据 今天推荐一款更加简单.轻量级,且功能强大的爬虫框架:feapder 项目地址: https://github.com/Boris-code/feapder 2. 介绍及安装 和 Scrapy 类似,feapder 支持轻量级爬虫.分布式爬虫.批次爬虫.爬虫报警机制等功能 内置的 3 种爬虫如下: AirSpider 轻量级爬虫,适合简单场景.数据量少的爬虫 Spider 分布式
-
python爬虫框架feapder的使用简介
目录 1. 前言 2. 介绍及安装 3. 实战一下 3-1 创建爬虫项目 3-2 创建爬虫 AirSpider 3-3 配置数据库.创建数据表.创建映射 Item 3-4 编写爬虫及数据解析 3-5 数据入库 4. 最后 1. 前言 大家好,我是安果! 众所周知,Python 最流行的爬虫框架是 Scrapy,它主要用于爬取网站结构性数据 今天推荐一款更加简单.轻量级,且功能强大的爬虫框架:feapder 项目地址: https://github.com/Boris-code/feap
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
python爬虫实战之最简单的网页爬虫教程
前言 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.最近对python爬虫有了强烈地兴趣,在此分享自己的学习路径,欢迎大家提出建议.我们相互交流,共同进步.话不多说了,来一起看看详细的介绍: 1.开发工具 笔者使用的工具是sublime text3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷.推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你. sublime text3
-
python爬虫(入门教程、视频教程) 原创
python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,我们关于爬虫这个方便整理过很多有价值的教程,小编通过本文章给大家做一个关于python爬虫相关知识的总结,以下就是全部内容: python爬虫的基础概述 1.什么是爬虫 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读