详解python中index()、find()方法
python中index()、find()方法,具体内容如下:
index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。影响后面程序执行
index()方法语法:str.index(str, beg=0, end=len(string))
- str -- 指定检索的字符串
- beg -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
str1='python is on the way'] str2='on' #空格,等其他操作符对其索引位置也有影响 #在str1中检测字符串中是否含有子字符串str2 str1.index(str2,beg=0,end=len(str1)) #如果包含子字符串 返回检测到的索引值 print(str1.index(str2)) #从索引1开始检测,检测长度为3 print(str1.index(str2,1,3))
如果包含子字符串返回开始的索引值,否则抛出异常。
user_name = ['xiaolei','xiaoman','lixia']
pass_word = ['123','456','789']
username = input('username:').strip()
password = input('password:').strip()
if username in user_name and password == pass_word[user_name.index(username)]:
print(f"登录成功,欢迎您:{username}")
else:
print("错误!")
若输入:username == xiaolei
user_name.index(username) == 0
所以:password == pass_word[0] == 123
Python find()方法,不能用于列表list
str.find(str, beg=0, end=len(string))
- str -- 指定检索的字符串
- beg -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。不影响后面程序执行
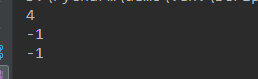
str1='python is on the way' str2='on' str3='nice' print(str1.index(str2)) #不在字符串str1中 print(str1.find(str3)) #从索引1开始检测,检测长度为3 print(str1.find(str2,1,3))
运行结果:
知识点补充:Python将DataFrame的某一列作为index
下面代码实现了将df中的column列作为index
df.set_index(["Column"], inplace=True)
总结
以上所述是小编给大家介绍的python中index()、find()方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
赞 (0)