CFC4N小试php正则表达式
朋友甲:要求根据一串字符串,反转成PHP数组,其给出的字符串为php的print_r打印出来的。我们在暂不考虑此方法是否能确保数据的准确性,以及其他意外等情况,仅根据要求写正则。
其字符串为
代码如下:
Array
(
[tt] => Array
(
[table] => qqttcode
[hitcode] => 1
)
[ww] => Array
(
[table] => qqwwcode
[hitcode] =>
)
[pp] => Array
(
[table] => qqppcode
[hitcode] => Array
(
[table] => qqppcode
[hitcode] =>
)
)
)
$strRge1 = '/(\[([^]]+)]\s?=>\s?)?Array[\s\S]+?\(([^()]|(?R))*\)/i';
$arrReturn = array();
if (preg_match_all($strRge1,$str,$tt1))
{
$arrReturn = getarray($tt1[0][0]);
}
$arrReturn2 = array();
foreach ($arrReturn as $k => $v)
{
$arrReturn2[$k] = $v[$k];
}
print_r($arrReturn2);
function getarray ($strContents)
{
$arrTemp = array();
$strRge = '/\[([^]]+)]\s?=>\s?Array[\s\S]+?\(([^()]|(?R))*\)/i';
$strReg2 = '/\[([^]]+?)]\s?=>\s?([\d\w]+)?/';
if (preg_match_all($strRge,$strContents,$strTemp))
{
$num = count($strTemp[1]);
if ($num > '1')
{
for ($i=0; $i<$num; $i++)
{
if (preg_match_all($strRge,$strTemp[0][$i],$arrTTT))
{
$arrTemp[$strTemp[1][$i]] = array();
$arrTemp[$strTemp[1][$i]] = getarray($strTemp[0][$i]);
}
else
{
$arrTemp[$strTemp[1][$i]] = $strTemp[0][$i];
}
}
}
else
{
$arrTemp[$strTemp[1][0]] = array();
$arrTemp2 = array();
if (preg_match_all($strReg2, $strTemp[0][0],$straa))
{
$num = count($straa[0]);
for ($i=0; $i<$num-1; $i++)
{
$arrTemp2[$straa[1][$i+1]] = $straa[2][$i+1];
}
}
$arrTemp[$strTemp[1][0]] = $arrTemp2;
}
}
return $arrTemp;
}
结果是可以用的。但是发现其只能用于固定的三层嵌套,假如N层的话,无法用这个函数了,后来,我又改造一下那个正则,改为
代码如下:
$strRge1 = '/\[(([^]]+)]\s?=>\s?Array[\s]+?\(([^()])+|(?R))\)+/i';
但是,并不能解决问题。。各位看官,您认为,我的误区在哪里呢?
附 第一个正则截图 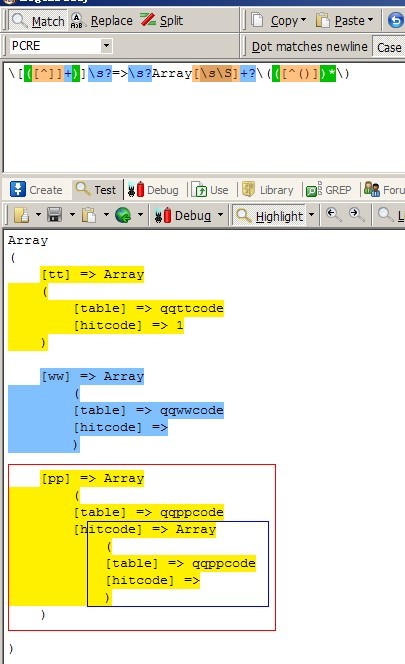
更改后正则匹配截图 
朋友乙:要求批量给html字符串中a标签中不包含title属性的标签添加title,而且,其title内容为<a href…>到</a>之间的文本。。
CFC4N给出答案为:
代码如下:
$str = '<a >ssss</a><a href="ss" >ssss</a><a title="ss" >ssss</a><a href="">ssss</a><a title="ss">ssss</a><a title="ss">ssss</a><a title="ssf">ssss</a>';
$str = preg_replace('%<a((?:(?!title="[^"]+?")[\s\S])+?)>(?:(?<!</a>)[\s\S])+?</a>%im','<a title="\\2" \\1>\\2</a>',$str);
print_r($str);
$str = '<a >ssss</a><a href="ss" >ssss</a><a title="ss" >ssss</a><a href="">ssss</a><a title="ss">ssss</a><a title="ss">ssss</a><a title="ssf">ssss</a>';
$str = preg_replace('%<a((?:(?!title="[^"]+?")[\s\S])+?)>(?:(?<!</a>)[\s\S])+?</a>%im','<a title="\\2" \\1>\\2</a>',$str);
print_r($str);
各位看官,您认为,CFC4N写的正则表达式里,哪些还可以优化呢?这个效率是不是不高??
朋友丙:要求过滤非本域名,或者非本子域名的其他域名的UBB标签链接,一旦包含,直接替换成其中间的文本,比如例子字符串如下
代码如下:
[url=http://www.sadas.cn]baidu[/url]
[url=www.ggasdwe.com]百度[/url]
[url=http://www.qq.com/index.php]QQ[/url]
[url=http://www.miyifun.com/index.html]其他
[/url]
[url=pc.qq.com/index.php]PC QQ[/url]
其中,字符串中不确定有几个换行等其他字符,而且,不确定url的UBB标签中的网址中是否包含http://,不确定二级域名或者三级域名
$str = '[url=http://www.sadas.cn]baidu[/url]
[url=www.ggasdwe.com]百度[/url]
[url=http://www.qq.com/index.php]QQ[/url]
[url=http://www.miyifun.com/index.html]其他
[/url]
[url=pc.qq.com/index.php]PC QQ[/url]';
print_r(preg_replace('%\[url=(http://)?(?:(?!qq\.com)[^\]])*\][\r|\r\n]*([\s\S]+?)[\r|\r\n]*\[/url\]%i','\\2',$str));
各位看官,您认为这里哪里是多余的?还可以进行哪些正则的优化来提高效率?如果没看懂,那您的疑问在哪里?
朋友丁:要求读取squid的配置文件中,起作用的行,也就是没有#开头进行注释的行。
其中,squid的配置文件内字符串见附件中
squid的配置文件内容
CFC4N给出正则代码如下
代码如下:
preg_match_all('/^(?!#).+?$/m', file_get_contents('squid.conf'), $regs);
print_r($regs[0]);
运行截图 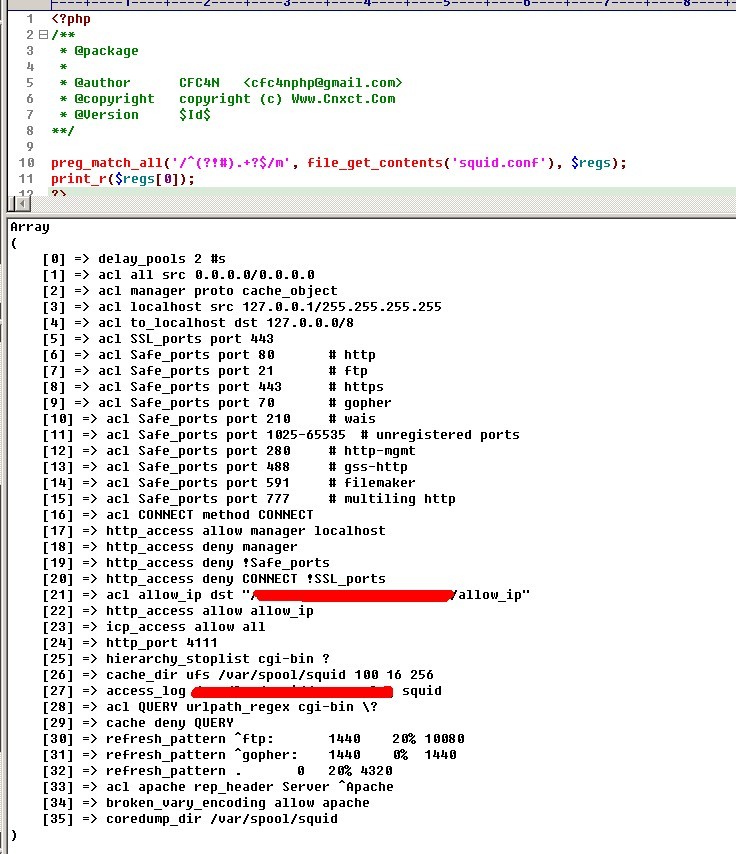
看官们,您认为,这个正则还有哪些没注意到的点?能否正确无误的匹配到朋友丁所需要的内容?您有疑问吗?
PS:以上正则,均为PCRE引擎。。其中,PHP代码的正则递归(迭代)部分,仅限于支持递归正则的引擎代码适用。。
感谢rex老大指点关于(?!)零宽断言非匹配的特性后接匹配规则可能无效的问题。
相关推荐
-

CFC4N小试php正则表达式
朋友甲:要求根据一串字符串,反转成PHP数组,其给出的字符串为php的print_r打印出来的.我们在暂不考虑此方法是否能确保数据的准确性,以及其他意外等情况,仅根据要求写正则. 其字符串为 复制代码 代码如下: Array ( [tt] => Array ( [table] => qqttcode [hitcode] => 1 ) [ww] => Array ( [table] => qqwwcode [hitcode] => ) [pp] => Array (
-
小议正则表达式效率 贪婪、非贪婪与回溯
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧. 某同学想过滤之间的内容,那是这么写正则以及程序的. 复制代码 代码如下: $str = preg_replace('%<script>.+?</script>%i','',$str);//非贪婪 看起来,好像没什么问题,其实则不然.若 复制代码 代码如下: $str = '<script<script>alert(docume
-
PHP中正则表达式对UNICODE字符码的匹配方法
网友ainiaa的问题是 PHP代码如下 复制代码 代码如下: $words = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSRUVWXYZ!@#$%^&*()_+-=[]\\,./{}|<>?'\"你好啊我们"; $otherStr=preg_replace("/[chr(128)-chr(256)]+/is"," ",$words); echo
-
coolcode转SyntaxHighlighter与Mysql正则表达式实现分析
最近,我抽空改成SyntaxHighlighter.由于coolcode插件的开头标签是 <coolcode> 或者[coolcode]这样的,而SyntaxHighlighter是 [code lang="php"] 这样的(或者其他).遂只能想办法把老的格式转化成新的格式.当然,肯定用到正则表达式了. 原来的代码高亮开头标识为 <coolcode lang="php" download="123.php" linenum=&
-
PHP正则表达式的效率 回溯与固化分组
先来看下问题. 字符串 复制代码 代码如下: $str = '<script>123456</script>'; 正则表达式为 复制代码 代码如下: $strRegex1 = '%<script>.+<\/script>%'; $strRegex2 = '%<script>.+?<\/script>%'; $strRegex3 = '%<script>(?:(?!<\/script>).)+<\/scri
-
PHP 正则表达式效率 贪婪、非贪婪与回溯分析(推荐)
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧. 某同学想过滤之间的内容,那是这么写正则以及程序的. $str = preg_replace('%<script>.+?</script>%i','',$str);//非贪婪 看起来,好像没什么问题,其实则不然.若 $str = '<script<script>alert(document.cookie)</script&
-
强大的Perl正则表达式实例详解
一.介绍 正则表达式各语言都有自己的规范,但是基本都差不多,都是由元字符的组合来进行匹配:由于Nmap内嵌的服务与版本探测是使用的Perl正则规范,因此此篇博客记录一下Perl正则的相关内容,方便后期查阅. 二.Perl正则例子 下面的例子可能有不足之处,有些来源于博客,没有验证: 1. 匹配IP地址:\d+\.\d+\.\d+\.\d+ \d:匹配一个数字字符,\d+:匹配一次或多次数字字符. \.:使用转义字符匹配'.'. 2. 匹配邮箱类似于123456@qq.com: /^[a-zA-Z
-
史上最全的PHP正则表达式(手机号需要加上177-***)
首先看下正则表达式思维导图: 一.校验数字的表达式 1 数字: ^[0-9]*$ 2 n位的数字: ^\d{n}$ 3 至少n位的数字: ^\d{n,}$ 4 m-n位的数字: ^\d{m,n}$ 5 零和非零开头的数字: ^(0|[1-9][0-9]*)$ 6 非零开头的最多带两位小数的数字: ^([1-9][0-9]*)+(.[0-9]{1,2})?$ 7 带1-2位小数的正数或负数: ^(\-)?\d+(\.\d{1,2})?$ 8 正数.负数.和小数: ^(\-|\+)?\d+(\.\
-
JavaScript中正则表达式的概念与应用
今天和大家分享一些关于正则表达式的知识和在javascript中的应用.正则表达式简单却又不简单,比如以前我的老师给我们讲的时候就说这个东西入门的话二三十分钟就精通了,一旦没有入门那就可几天都补不回来.于是当初就很认真的学习并研究了它.没想到正则表达式不仅代码简洁,而且在实际的操作中为前端工程师们省事了不少.总所周知,用户在浏览页面的时候,唯一和数据打交道的就是表单了,关于表单的验证,其实有很多中方法,接下来,我就会给大家分享两种,一种是普通繁琐的方法,一种是正则表达式,看看它到底能够给表单带来
-
Javascript中正则表达式的使用及基本语法
前面的话 正则表达式在人们的印象中可能是一堆无法理解的字符,但就是这些符号却实现了字符串的高效操作.通常的情况是,问题本身并不复杂,但没有正则表达式就成了大问题.javascript中的正则表达式作为相当重要的知识,本文将介绍正则表达式的基础语法 定义 正则表达式(Regular Expression)是一门简单语言的语法规范,是强大.便捷.高效的文本处理工具,它应用在一些方法中,对字符串中的信息实现查找.替换和提取操作 javascript中的正则表达式用RegExp对象表示,有两种写法:一种