python实现从pdf文件中提取文本,并自动翻译的方法
针对Python 3.5.2 测试
首先安装两个包:
$ pip install googletrans
$ pip install pdfminer3k
googletrans会提供一个命令translate,这个命令会调用google translate api执行自动翻译:
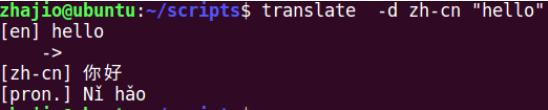


pdfminer3k会提供一个工具脚本pdf2txt.py:
$ pdf2txt.py xxx.pdf
从stackoverflow搜索到可以去除页眉和页脚的命令(强烈推荐):
使用Ubuntu提供的pdftotext工具:
$ pdftotext -y 50 -H 650 -W 1000 -nopgbrk sva.pdf $ pdftotext -f 147 -l 166 -y 50 -H 650 -W 1000 -nopgbrk sva.pdf
谷歌翻译并不能识别段落或者整句,如果一个整句中出现换行符,会发现翻译就不完整了,以网页版谷歌翻译测试:
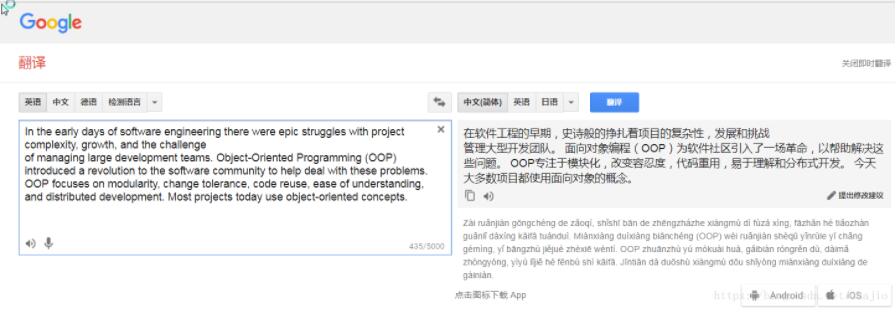
因此需要将pdf转换好的文本文件进行拼接,借用linux args 命令,实现此功能,将整个文件的换行符全部去掉。
但是问题又出现了,整个文件变成一行,我们的段落结构都消失了,那么我们需要手动添加delimiter,设置为一个特殊字符@。
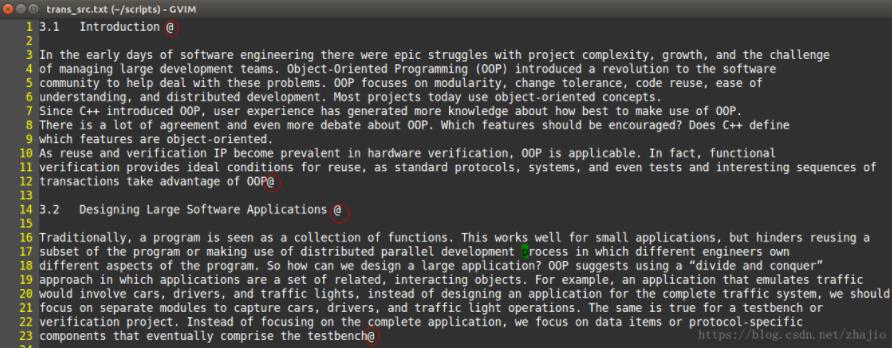
执行如下命令:
cat trans_src.txt |xargs |xargs -0 -d '@' -i{} translate -d zh-cn {} |tee trans_dst.txt
cat sva_src_1to2.txt |xargs |xargs -0 -d '&' -i{} translate -d zh-cn {} |xargs -d'\n' -n4 | awk -F'zh-cn' '{print $2}' | awk -F'[][]' '{print $2}' | tee sva_dst_1to2.txt
将翻译后的文本重定向到一个文件,然后对文件进行简单的后处理,就可以了。
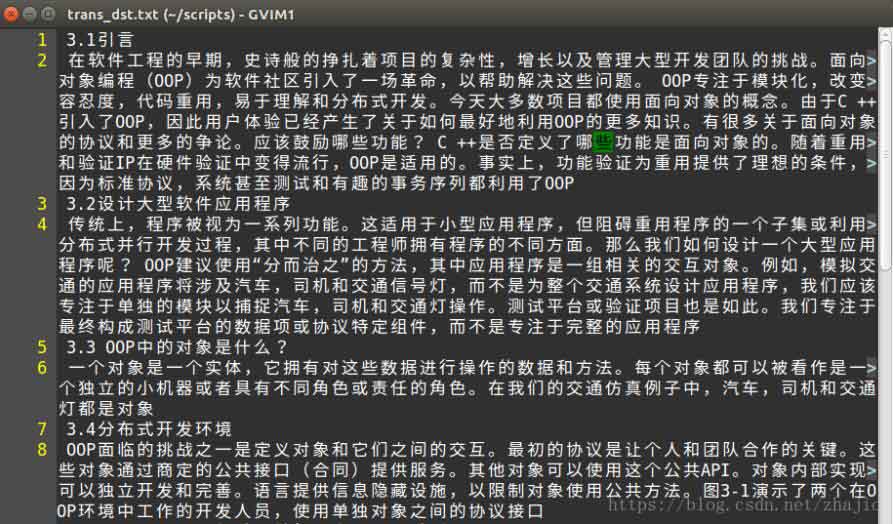
以上这篇python实现从pdf文件中提取文本,并自动翻译的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
python基于pdfminer库提取pdf文字代码实例
安装pdfminer 库 windows 下安装pdfminer3k pip install pdfminer3k Liunx 下安装pdfminer pip install pdfminer 代码 from pdfminer.pdfparser import PDFParser, PDFDocument from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LAParams, LTTextBox
-
Python提取PDF内容的方法(文本、图像、线条等)
1.安装PDFminer3k 使用pip 命令安装 pip install pdfminer3k 2.编写测试 你可以在这里获得官方参考:PDFMiner 如果你不喜欢看英文的官方文档,这里的翻译也许对你有帮助:中文PDFMiner文档 下面的程序,我拓展了官方给出的例子,你可以通过这个例子统计出来你的pdf文件一共包含哪些内容,比如文本框,曲线,图片等 #!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'yooongchun' imp
-
python实现从pdf文件中提取文本,并自动翻译的方法
针对Python 3.5.2 测试 首先安装两个包: $ pip install googletrans $ pip install pdfminer3k googletrans会提供一个命令translate,这个命令会调用google translate api执行自动翻译: pdfminer3k会提供一个工具脚本pdf2txt.py: $ pdf2txt.py xxx.pdf 从stackoverflow搜索到可以去除页眉和页脚的命令(强烈推荐): 使用Ubuntu提供的pdftotext
-
windows下Python实现将pdf文件转化为png格式图片的方法
本文实例讲述了windows下Python实现将pdf文件转化为png格式图片的方法.分享给大家供大家参考,具体如下: 最近工作中需要把pdf文件转化为图片,想用Python来实现,于是在网上找啊找啊找啊找,找了半天,倒是找到一些代码. 1.第一个找到的代码,我试了一下好像是反了,只能实现把图片转为pdf,而不能把pdf转为图片... 参考链接:https://zhidao.baidu.com/question/745221795058982452.html 代码如下: #!/usr/bin/e
-
Python实现截取PDF文件中的几页代码实例
截取PDF文件中的几页有很多做法. 1. 把文件用Google的Chrome浏览器打开,打印其中几页,另存为PDF.简单. 2. 安装Adobe的Acrobat,里面会有更全的功能.然而,收费. 3. 用Python的PyPDF2包.(Python 3,亲测有效) 下面是Python代码实例: pip install PyPDF2 from PyPDF2 import PdfFileWriter, PdfFileReader # 开始页 start_page = 0 # 截止页 end_page
-
Python使用get_text()方法从大段html中提取文本的实例
如下所示: <textarea rows="" cols="" name="id"><DIV style="TEXT-INDENT: 18pt; mso-char-indent-count: 2.0000" class=MsoNormal><SPAN style="FONT-FAMILY: 宋体; FONT-SIZE: 9pt; mso-spacerun: 'yes'; mso-font
-

Python中搜索和替换文件中的文本的实现(四种)
在本文中,我将给大家演示如何在 python 中使用四种方法替换文件中的文本. 方法一:不使用任何外部模块搜索和替换文本 让我们看看如何在文本文件中搜索和替换文本.首先,我们创建一个文本文件,我们要在其中搜索和替换文本.将此文件设为 Haiyong.txt,内容如下: 要替换文件中的文本,我们将使用 open() 函数以只读方式打开文件.然后我们将 t=read 并使用 read() 和 replace() 函数替换文本文件中的内容. 语法: open(file, mode='r') 参数: f
-
教你使用Python从文件中提取IP地址
目录 算法 : 代码 输出 : 代码: 输出 : 补充:python提取一段字符串中的ip地址 总结 让我们看看如何使用 Python 从文件中提取 IP 地址. 算法 : 为正则表达式导入 re 模块. 使用 open() 函数打开文件. 读取文件中的所有行并将它们存储在列表中. 声明 IP 地址的模式.正则表达式模式是: r'(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})' 对于列表中的每个元素,使用 search() 函数搜索模式,将 IP 地址存储在列表中. 显
-
Java 读取PDF中的文本和图片的方法
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Java(免费版) Jar文件获取导入: 方法1:通过官网下载jar文件包.下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入java程序.导入后如下图: 方法2: 可通过maven仓库安装导入. Java代码示例 import com.spire.pdf.*; import java
-
Python爬虫之m3u8文件里提取小视频的正确姿势
前言 在网上爬取的小视频(.ts格式)打不开怎么搞?使用IDM下载有时候还会出现数据受法律保护,IDM无法下载该内容,如何解决?这篇博客就来聊聊如何正确提取m3u8文件里的.ts视频,并合成完整的.mp4格式视频. 1. HLS协议与m3u8文件 HLS,即 H T T P L i v e S t r e a m i n g HTTP\ Live\ Streaming HTTP Live Streaming的缩写,是由苹果公司提出基于HTTP的流媒体网络传输协议.是苹果公司Qui
-
Python实现从log日志中提取ip的方法【正则提取】
本文实例讲述了Python实现从log日志中提取ip的方法.分享给大家供大家参考,具体如下: log日志内容如下(myjob.log): 124.90.53.68 - - [05/Feb/2018 11:37:07] "GET /favicon.ico HTTP/1.1" 404 - 61.148.245.145 - - [05/Feb/2018 12:37:44] "GET / HTTP/1.1" 200 - 61.148.245.145 - - [05/Feb/