详解opencv Python特征检测及K-最近邻匹配
鉴于即将启程旅行,先上传篇简单的图像检索介绍,与各位一起学习opencv的同学共勉
一.特征检测
图片的特征主要分为角点,斑点,边,脊向等,都是常用特征检测算法所检测到的图像特征·
1.Harris角点检测
先将图片转换为灰度模式,再使用以下函数检测图片的角点特征:
dst=cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]])
重点关注第三个参数,这里使用了Sobel算子,简单来说,其取为3-31间的奇数,定义了角点检测的敏感性,不同图片需要进行调试。
k 是 Harris 角点检测方程中的自由参数,取值参数为[0,04,0.06].
2.DoG角点检测及SIFT特征变换
Harris角点检测在面对图像尺度性发生改变时极其容易丢失图像细节,造成检测失误。因此在检测图像特征时,常常我们需要一些拥有尺度不变性的特征检测算法。
DoG角点检测即将两幅图像在不同参数下的高斯滤波结果相减,得到DoG图。步骤:用两个不同的5x5高斯核对图像进行卷积,然后再相减的操作。重复三次得到三个差分图A,B,C。计算出的A,B,C三个DOG图中求图B中是极值的点。图B的点在当前由A,B,C共27个点组成的block中是否为极大值或者极小值。若满足此条件则认为是角点。
SIFT对象会使用DoG检测关键点,并对每个关键点周围的区域计算特征向量。事实上他仅做检测和计算,其返回值是关键点信息(关键点)和描述符。
#下列代码即先创建一个SIFT对象,然后计算灰度图像 sift = cv2.xfeatures2d.SIFT_create() keypoints, descriptor = sift.detectAndCompute(gray, None) #sift对象会使用DoG检测关键点,对关键点周围的区域计算向量特征,检测并计算
需要注意的是,返回的是关键点和描述符
关键点是点的列表
描述符是检测到的特征的局部区域图像列表
介绍一下关键点的属性:pt: 点的x y坐标 size: 表示特征的直径 angle: 特征方向 response: 关键点的强度 octave: 特征所在金字塔层级,算法进行迭代的时候, 作为参数的图像尺寸和相邻像素会发生变化octave属性表示检测到关键点所在的层级 ID: 检测到关键点的ID
SIFT特征不只具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。
3.SURF提取和检测特征
SURF是SIFT的加速版算法,采用快速Hessian算法检测关键点
借用下度娘的说法:SURF算法原理:
1.构建Hessian矩阵构造高斯金字塔尺度空间
2.利用非极大值抑制初步确定特征点
3精确定位极值点
4选取特征点的主方向
5构造surf特征点描述算子
具体应用看代码
import cv2
import numpy as np
img = cv2.imread('/home/yc/Pictures/jianbin.jpg')
#参数为hessian矩阵的阈值
surf = cv2.xfeatures2d.SURF_create(4000)
#设置是否要检测方向
surf.setUpright(True)
#输出设置值
print(surf.getUpright())
#找到关键点和描述符
key_query,desc_query = surf.detectAndCompute(img,None)
img=cv2.drawKeypoints(img,key_query,img)
#输出描述符的个数
print(surf.descriptorSize())
cv2.namedWindow("jianbin",cv2.WINDOW_NORMAL)
cv2.imshow('jianbin',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这是检测效果,图中已标志出特征点,不要问我为什么选这种鬼畜样图,可能是因为情怀(滑稽)
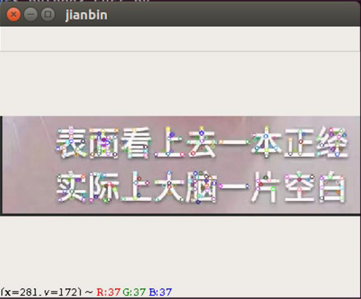
样图
需要注意的是,需要安装之前版本的opencv-contrib库才可以使用,surf及sift均受专利保护
4.orb特征提取
ORB算法使用FAST算法寻找关键点,然后使用Harris角点检测找到这些点当中的最好的N个点,采用BRIEF描述子的特性。ORB算法处于起步阶段,速度优于前两种算法,也吸收了其优点,同时他是开源的。
# 创建ORB特征检测器和描述符 orb = cv2.ORB_create() kp = orb.detect(img,None) # 对图像检测特征和描述符 kp, des = orb.compute(img, kp) #注意kp是一个包含若干点的列表,des对应每个点的描述符 是一个列表, 每一项都是检测>到的特征的局部图像
二、特征匹配
1.BF暴力匹配
暴力匹配的算法难以进行优化,是一种描述符匹配方法,将每个对应的描述符的特征进行比较,每次比较给出一个距离值,最好的结果贼被认为是一个匹配。
# 暴力匹配BFMatcher,遍历描述符,确定描述符是否匹配,然后计算匹配距离并排序 # BFMatcher函数参数: # normType:NORM_L1, NORM_L2, NORM_HAMMING, NORM_HAMMING2。 # NORM_L1和NORM_L2是SIFT和SURF描述符的优先选择,NORM_HAMMING和NORM_HAMMING2是用于ORB算法 bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True) matches = bf.match(des1,des2) matches = sorted(matches, key = lambda x:x.distance) # matches是DMatch对象,具有以下属性: # DMatch.distance - 描述符之间的距离。 越低越好。 # DMatch.trainIdx - 训练描述符中描述符的索引 # DMatch.queryIdx - 查询描述符中描述符的索引 # DMatch.imgIdx - 训练图像的索引。
2.K-最近邻匹配
KNN算法可能是最简单的机器学习算法,即给定一个已训练的数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,则判定该输入实例同属此类。
概念比较冗长,大致可以理解为如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,我个人简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
这里我们直接调用opencv库中的KNN函数,使用较简单。该KNN匹配利用BF匹配后的数据进行匹配。
完整代码:
# coding:utf-8
import cv2
# 按照灰度图像读入两张图片
img1 = cv2.imread("/home/yc/Pictures/cat.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("/home/yc/Pictures/cat2.jpg", cv2.IMREAD_GRAYSCALE)
# 获取特征提取器对象
orb = cv2.ORB_create()
# 检测关键点和特征描述
keypoint1, desc1 = orb.detectAndCompute(img1, None)
keypoint2, desc2 = orb.detectAndCompute(img2, None)
"""
keypoint 是关键点的列表
desc 检测到的特征的局部图的列表
"""
# 获得knn检测器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.knnMatch(desc1, desc2, k=1)
"""
knn 匹配可以返回k个最佳的匹配项
bf返回所有的匹配项
"""
# 画出匹配结果
img3 = cv2.drawMatchesKnn(img1, keypoint1, img2, keypoint2, matches, img2, flags=2)
cv2.imshow("cat", img3)
cv2.waitKey()
cv2.destroyAllWindows()
也许这里得到的结果与match函数所得到的结果差距不大,但二者主要区别是KnnMatch所返回的是K个匹配值,可以容许我们继续处理,而match返回最佳匹配。
以下为样图
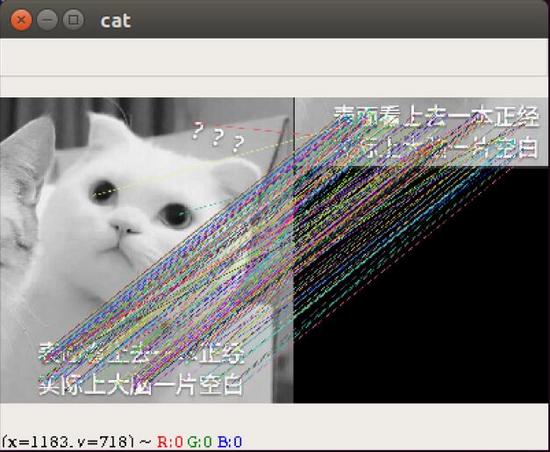
cat
实现简单的图像检索功能时,此类特征匹配算法对硬件的要求较低,效率较高,但是准确度有待考量
与一起学习opencv的同学共勉,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python机器学习实战之最近邻kNN分类器
K近邻法是有监督学习方法,原理很简单,假设我们有一堆分好类的样本数据,分好类表示每个样本都一个对应的已知类标签,当来一个测试样本要我们判断它的类别是, 就分别计算到每个样本的距离,然后选取离测试样本最近的前K个样本的标签累计投票, 得票数最多的那个标签就为测试样本的标签. 源代码详解: #-*- coding:utf-8 -*- #!/usr/bin/python # 测试代码 约会数据分类 import KNN KNN.datingClassTest1() 标签为字符串 KNN.datingC
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并
-
python实现K最近邻算法
KNN核心算法函数,具体内容如下 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : zoujiameng@aliyun.com.cn import math def getMaxLocate(target): # 查找target中最大值的locate maxValue = float("-inFinIty") for i in range(len(target)
-
详解opencv Python特征检测及K-最近邻匹配
鉴于即将启程旅行,先上传篇简单的图像检索介绍,与各位一起学习opencv的同学共勉 一.特征检测 图片的特征主要分为角点,斑点,边,脊向等,都是常用特征检测算法所检测到的图像特征· 1.Harris角点检测 先将图片转换为灰度模式,再使用以下函数检测图片的角点特征: dst=cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]]) 重点关注第三个参数,这里使用了Sobel算子,简单来说,其取为3-31间的奇数,定义了角点检测的
-

详解在Python中使用OpenCV进行直线检测
目录 1.引言 2.霍夫变换 3.举个栗子 3.1读入图像进行灰度化 3.2执行边缘检测 3.3进行霍夫变换 补充 1. 引言 在图像处理中,直线检测是一种常见的算法,它通常获取n个边缘点的集合,并找到通过这些边缘点的直线.其中用于直线检测,最为流行的检测器是基于霍夫变换的直线检测技术. 2. 霍夫变换 霍夫变换是图像处理中的一种特征提取方法,可以识别图像中的几何形状.它将在参数空间内进行投票来决定其物体形状,通过检测累计结果找到一极大值所对应的解,利用此解即可得到一个符合特定形状的参数. 在使
-
详解使用Python+Pycaret进行异常检测
目录 概述 介绍 为什么是PyCaret 学习目标 PyCaret安装 数据导入 探索性异常检测分析 Swarm图 箱形图 散点图 异常检测 模型创建 隔离森林 局部异常因子 K最近邻 比较模型中的异常 解释和可视化 尾注 概述 1.通过探索性异常检测分析了解异常 2.设置 PyCaret 环境并尝试准备任务的各种数据 3.比较性能并可视化不同的异常检测算法 介绍 异常检测提供了在数据中发现模式.偏差和异常的途径,这些模式.偏差和异常不限于模型的标准行为.异常检测旨在确定数据中的异常情况.这些异
-
详解在Python中使用Torchmoji将文本转换为表情符号
很难找到关于如何使用Python使用DeepMoji的教程.我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji. TorchMoji是DeepMoji的pyTorch实现,可以在这里找到:https://github.com/huggingface/torchMoji 事实上,我还没有找到一个关于如何将文本转换为表情符号的教程.如果你也没找到,那么本文就是一个了. 安装 这些代码并不完全是我的写的,源代码可以在这个链接上找到. pip3 install torch=
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测
-
详解基于python的全局与局部序列比对的实现(DNA)
程序能实现什么 a.完成gap值的自定义输入以及两条需比对序列的输入 b.完成得分矩阵的计算及输出 c.输出序列比对结果 d.使用matplotlib对得分矩阵路径的绘制 一.实现步骤 1.用户输入步骤 a.输入自定义的gap值 b.输入需要比对的碱基序列1(A,T,C,G)换行表示输入完成 b.输入需要比对的碱基序列2(A,T,C,G)换行表示输入完成 输入(示例): 2.代码实现步骤 1.获取到用户输入的gap,s以及t 2.调用构建得分矩阵函数,得到得分矩阵以及方向矩阵 3.将得到的得分矩
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或
-
详解利用python识别图片中的条码(pyzbar)及条码图片矫正和增强
前言 这周和大家分享如何用python识别图像里的条码.用到的库可以是zbar.希望西瓜6辛苦码的代码不要被盗了.(zxing的话,我一直没有装好,等装好之后再写一篇) 具体步骤 前期准备 用opencv去读取图片,用pip进行安装. pip install opencv-python 所用到的图片就是这个 使用pyzbar windows的安装方法是 pip install pyzbar 而mac的话,最好用brew来安装. (有可能直接就好,也有可能很麻烦) 装好之后就是读取图片,识别条码.
-
详解OpenCV中简单的鼠标事件处理
目录 cv2.setMouseCallback函数语法 回调函数 谈及鼠标事件,就是在触发鼠标按钮后程序所做出相应的反应,但是不影响程序的整个线程.这有些像异步处理.鼠标事件响应不会一直等着我们去按而后续程序不执行,这样会造成阻塞,而是在我们不按鼠标的时候程序也会正常进行,按的时候会调用鼠标的事件响应,这个过程就像程序一边正常运行一边等待鼠标响应. 为了将鼠标响应和操作画面进行绑定,我们要创建一个回调函数: cv2.setMouseCallback函数语法 cv2.setMouseCallbac
-
详解OpenCV实现特征提取的方法
目录 前言 1. 颜色 2. 形状 3. 纹理 a. GLCM b. LBP 结论 前言 如何从图像中提取特征?第一次听说“特征提取”一词是在 YouTube 上的机器学习视频教程中,它清楚地解释了我们如何在大型数据集中提取特征. 很简单,数据集的列就是特征.然而,当我遇到计算机视觉主题时,当听说我们将从图像中提取特征时,吃了一惊.是否开始浏览图像的每一列并取出每个像素? 一段时间后,明白了特征提取在计算机视觉中的含义.特征提取是降维过程的一部分,其中,原始数据的初始集被划分并减少到更易于管理