Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载
scrapy框架
sublime text3
一。搭建python(Windows版本)
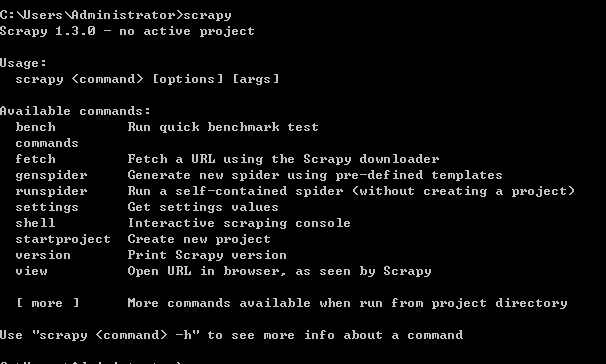
1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功

2.集成Scrapy框架----输入命令行:pip install Scrapy

安装成功界面如下:
失败的情况很多,举例一种:
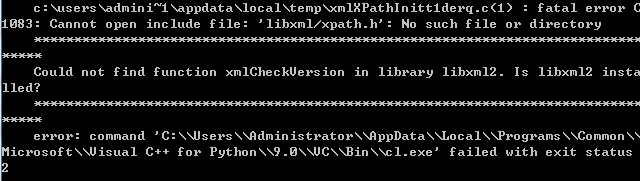
解决方案:
其余错误可百度搜索。
二。开始编程。
1.爬取无反爬虫措施的静态网站。例如百度贴吧,豆瓣读书。
例如-《桌面吧》的一个帖子https://tieba.baidu.com/p/2460150866?red_tag=3569129009
python代码如下:
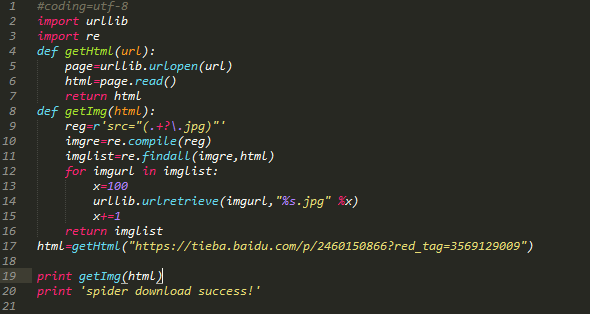
代码注释:引入了两个模块urllib,re。定义两个函数,第一个函数是获取整个目标网页数据,第二个函数是在目标网页中获取目标图片,遍历网页,并且给获取的图片按照0开始排序。
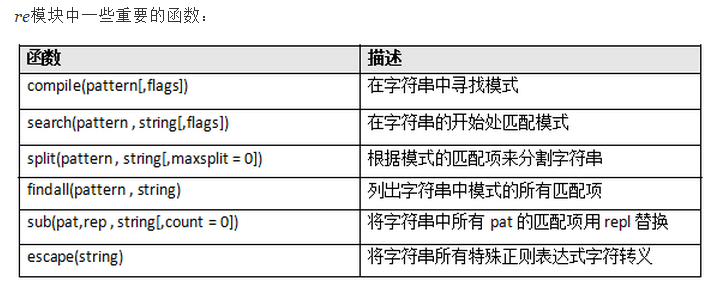
注:re模块知识点:
爬取图片效果图:
图片保存路径默认在建立的.py同目录文件下。
2.爬取有反爬虫措施的百度图片。如百度图片等。
例如关键字搜索“表情包”https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps=111111
图片采用滚动式加载,先爬取最优先的30张。
代码如下:
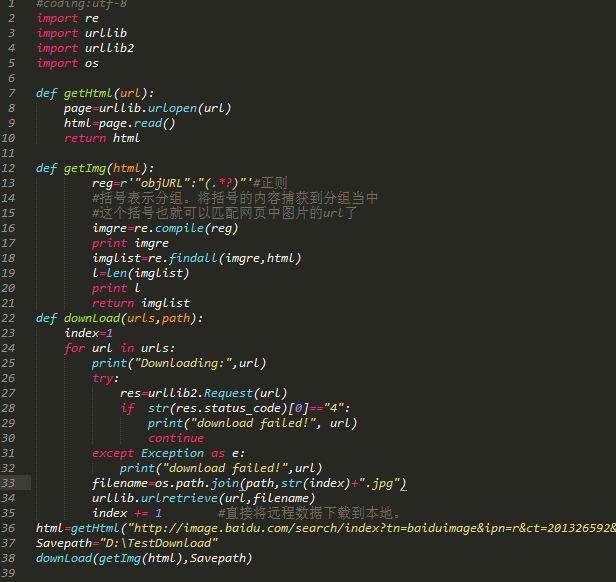
代码注释:导入4个模块,os模块用于指定保存路径。前两个函数同上。第三个函数使用了if语句,并tryException异常。
爬取过程如下:
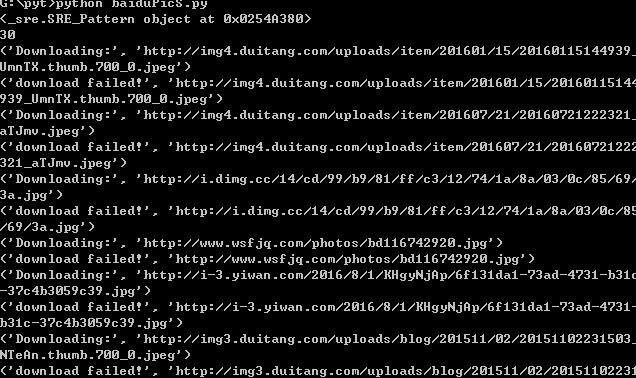
爬取结果:

注:编写python代码注重对齐,and不能混用Tab和空格,易报错。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-
Python使用Scrapy爬取妹子图
Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片.和大家分享一下. 核心爬虫代码 # -*- coding: utf-8 -*- from scrapy.selector import Selector import scrapy from scrapy.contrib.loader import ItemLoader, Identity from fun.items import MeizituItem class MeizituSpider(sc
-

python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
Python实现爬取需要登录的网站完整示例
本文实例讲述了Python爬取需要登录的网站实现方法.分享给大家供大家参考,具体如下: import requests from lxml import html # 创建 session 对象.这个对象会保存所有的登录会话请求. session_requests = requests.session() # 提取在登录时所使用的 csrf 标记 login_url = "https://bitbucket.org/account/signin/?next=/" result = se
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 "如何正确地吐槽" 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了. 工具 1.Python 2.7 2.BeautifulSoup 分析网页 我们先来看看知乎上该网页的情况 网址:,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了. 再来看一下我们要爬取的内容: 我们要爬取两个内容:问题和回答,回答仅限于显示
-
python实现爬取千万淘宝商品的方法
本文实例讲述了python实现爬取千万淘宝商品的方法.分享给大家供大家参考.具体实现方法如下: import time import leveldb from urllib.parse import quote_plus import re import json import itertools import sys import requests from queue import Queue from threading import Thread URL_BASE = 'http://s
-
使用Python中的cookielib模拟登录网站
前面简单提到了 Python 模拟登录的程序,但是没写清楚,这里再补上一个带注释的 Python 模拟登录的示例程序.简单说一下流程:先用cookielib获取cookie,再用获取到的cookie,进入需要登录的网站. # -*- coding: utf-8 -*- # !/usr/bin/python import urllib2 import urllib import cookielib import re auth_url = 'http://www.nowamagic.net/' h
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
Python 爬虫爬取指定博客的所有文章
自上一篇文章 Z Story : Using Django with GAE Python 后台抓取多个网站的页面全文 后,大体的进度如下: 1.增加了Cron: 用来告诉程序每隔30分钟 让一个task 醒来, 跑到指定的那几个博客上去爬取最新的更新 2.用google 的 Datastore 来存贮每次爬虫爬下来的内容..只存贮新的内容.. 就像上次说的那样,这样以来 性能有了大幅度的提高: 原来的每次请求后, 爬虫才被唤醒 所以要花大约17秒的时间才能从后台输出到前台而现在只需要2秒不到
-
Python爬取Coursera课程资源的详细过程
有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作.Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等,离线下来后会非常便于学习.很明显,我们不会去一个文件一个文件的下载,只有傻子才那么干,程序员都是聪明人! 那我们聪明人准备怎么办呢?当然是写一个脚本来批量下载了.首先我们需要分析一下手工下载的流程:登录自己的Coursera账户(有的课程需要我们登录并选课后才能看到相应的资源),在课程资源页面里,找到相应的文件