Java数据结构之图的基础概念和数据模型详解
目录
- 图的实际应用
- 图的定义及分类
- 图的相关术语
- 图的存储结构
- 邻接矩阵
- 邻接表
- 图的实现
- 图的API设计
- 代码实现
图的实际应用
在现实生活中,有许多应用场景会包含很多点以及点点之间的连接,而这些应用场景我们都可以用即将要学习的图这种数据结构去解决。
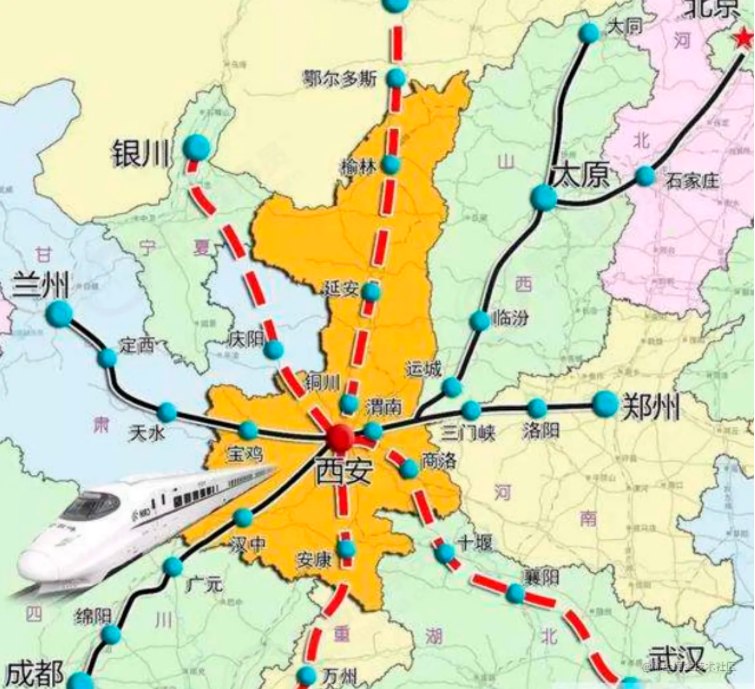
地图:
我们生活中经常使用的地图,基本上是由城市以及连接城市的道路组成,如果我们把城市看做是一个一个的点,把道路看做是一条一条的连接,那么地图就是我们将要学习的图这种数据结构。
图的定义及分类
定义: 图是由一组顶点和一组能够将两个顶点相连的边组成的。
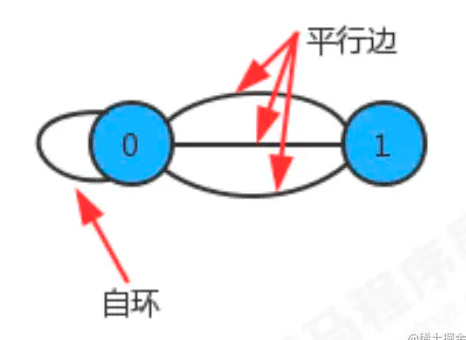
特殊的图:
- 自环:即一条连接一个顶点和其自身的边;
- 平行边:连接同一对顶点的两条边;
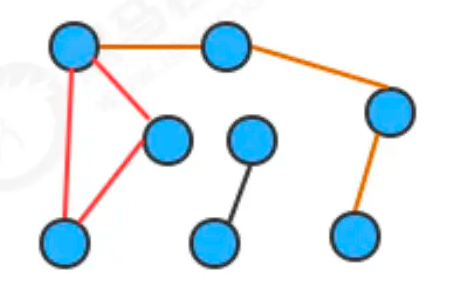
图的分类:
按照连接两个顶点的边的不同,可以把图分为以下两种:
无向图:边仅仅连接两个顶点,没有其他含义;
有向图:边不仅连接两个顶点,并且具有方向;
图的相关术语
相邻顶点:
当两个顶点通过一条边相连时,我们称这两个顶点是相邻的,并且称这条边依附于这两个顶点。
度:
某个顶点的度就是依附于该顶点的边的个数
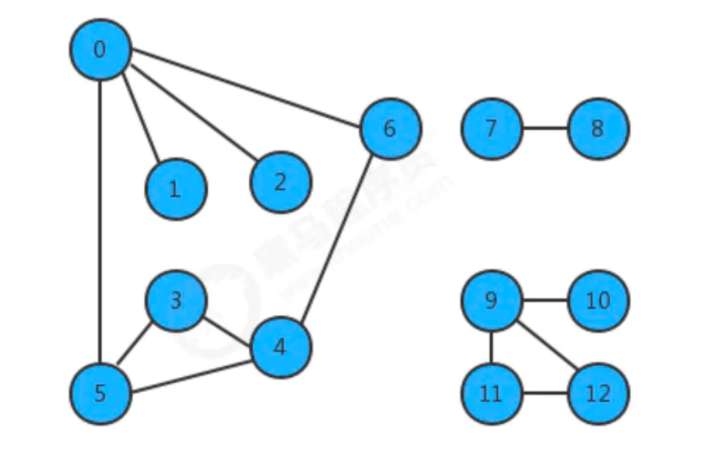
子图:
是一幅图的所有边的子集(包含这些边依附的顶点)组成的图;
路径:
是由边顺序连接的一系列的顶点组成
环:
是一条至少含有一条边且终点和起点相同的路径
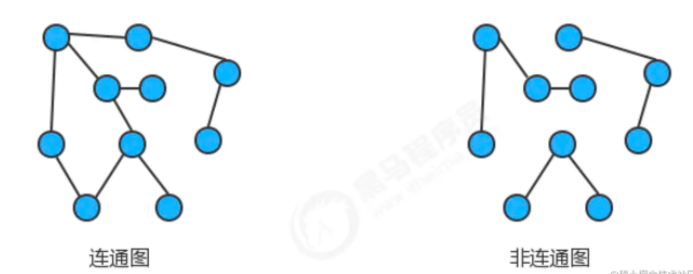
连通图:
如果图中任意一个顶点都存在一条路径到达另外一个顶点,那么这幅图就称之为连通图
连通子图:
一个非连通图由若干连通的部分组成,每一个连通的部分都可以称为该图的连通子图
图的存储结构
要表示一幅图,只需要表示清楚以下两部分内容即可:
- 图中所有的顶点;
- 所有连接顶点的边;
常见的图的存储结构有两种:邻接矩阵和邻接表。
邻接矩阵
- 使用一个V*V的二维数组int[V][V] adj,把索引的值看做是顶点;
- 如果顶点v和顶点w相连,我们只需要将adj[v][w]和adj[w][v]的值设置为1,否则设置为0即可。
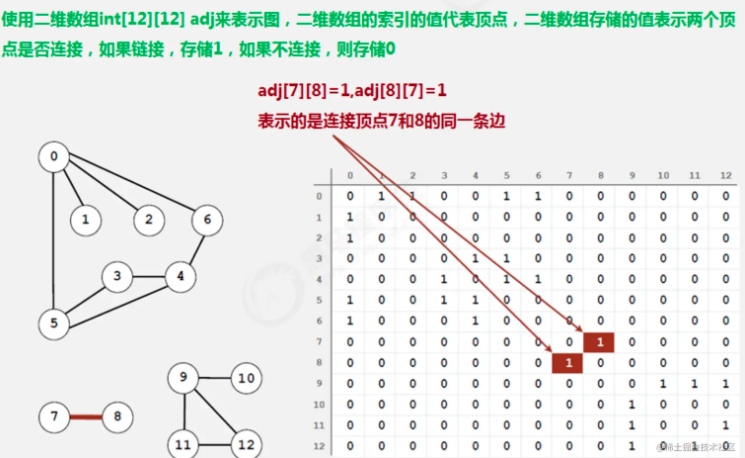
很明显,邻接矩阵这种存储方式的空间复杂度是V^2的,如果我们处理的问题规模比较大的话,内存空间极有可能不够用。
邻接表
1.使用一个大小为V的数组 Queue[V] adj,把索引看做是顶点;
2.每个索引处adj[v]存储了一个队列,该队列中存储的是所有与该顶点相邻的其他顶点。
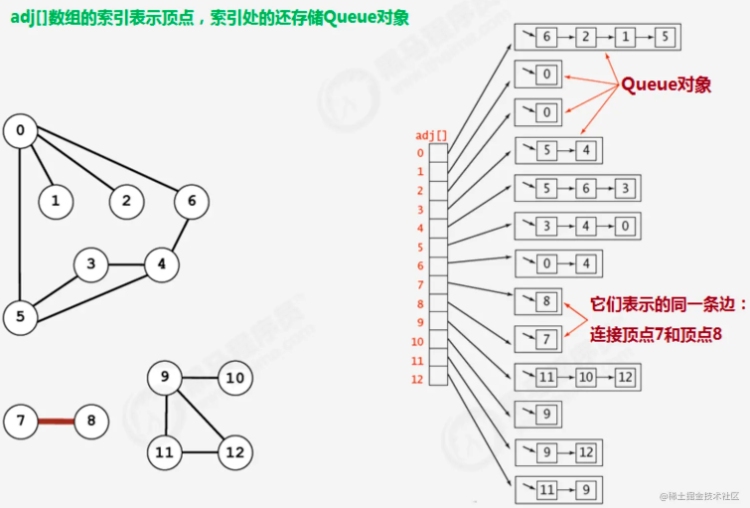
很明显,邻接表的空间并不是是线性级别的,所以后面我们一直采用邻接表这种存储形式来表示图。
图的实现
下面通过代码实现一个无向图。
图的API设计
| 类名 | Graph |
|---|---|
| 成员变量 | 1.private final int V: 记录顶点数量2.private int E: 记录边数量3.private Queue[] adj: 邻接表 |
| 构造方法 | Graph(int V):创建一个包含V个顶点但不包含边的图 |
| 成员方法 | 1.public int V():获取图中顶点的数量2.public int E():获取图中边的数量3.public void addEdge(int v,int w):向图中添加一条边 v-w4.public Queue adj(int v):获取和顶点v相邻的所有顶点 |
代码实现
/**
* 无向图的表示
*
* @author alvin
* @date 2022/10/30
* @since 1.0
**/
public class Graph {
//顶点数目
private final int V;
//边的数目
private int E;
//邻接表,队列的形式
private Queue<Integer>[] adj;
public Graph(int V) {
// 初始化顶点数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
//初始化邻接表中的空队列
for (int i = 0; i < adj.length; i++) {
adj[i] = new ArrayDeque<>();
}
}
public void addEdge(int v, int w) {
//把w添加到v的链表中,这样顶点v就多了一个相邻点w
adj[v].add(w);
//把v添加到w的链表中,这样顶点w就多了一个相邻点v
adj[w].add(v);
//边的数目自增1
E++;
}
//获取顶点数目
public int V() {
return V;
}
//获取边的数目
public int E(){
return E;
}
//获取和顶点v相邻的所有顶点
public Queue<Integer> adj(int v) {
return adj[v];
}
}
数组adj的索引表示顶点。
到此这篇关于Java数据结构之图的基础概念和数据模型详解的文章就介绍到这了,更多相关Java数据结构 图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java数据结构之图(动力节点Java学院整理)
1,摘要: 本文章主要讲解学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph).从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组:一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表.下图是图的邻接表表示. 从图中可以看出,图的实现需要能够表示顶点表,能够表示边表.邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点.这样,就可以用邻接表来实现边的表示了.如顶点V0的邻接表如下: 与
-
Java数据结构之图的原理与实现
目录 1 图的定义和相关概念 2 图的存储结构 2.1 邻接矩阵 2.2 邻接表 3 图的遍历 3.1 深度优先遍历 3.2 广度优先遍历 4 图的实现 4.1 无向图的邻接表实现 4.2 有向图的邻接表实现 4.3 无向图的邻接矩阵实现 4.4 有向图的邻接矩阵实现 5 总结 首先介绍了图的入门概念,然后介绍了图的邻接矩阵和邻接表两种存储结构.以及深度优先遍历和广度优先遍历的两种遍历方式,最后提供了Java代码的实现. 图,算作一种比较复杂的数据结构,因此建议有一定数据结构基础的人再来学习!
-
Java数据结构中图的进阶详解
目录 有向图 有向图API设计 有向图的实现 拓扑排序 拓扑排序图解 检测有向图中的环 检测有向环的API设计 检测有向环实现 代码 基于深度优先的顶点排序 顶点排序API设计 顶点排序实现 代码: 有向图 有向图的定义及相关术语 定义∶ 有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着 一对有序的顶点. 出度∶ 由某个顶点指出的边的个数称为该顶点的出度. 入度: 指向某个顶点的边的个数称为该顶点的入度. 有向路径︰ 由一系列顶点组成,对于其中的每个顶点都存在一
-
Java数据结构之图的基础概念和数据模型详解
目录 图的实际应用 图的定义及分类 图的相关术语 图的存储结构 邻接矩阵 邻接表 图的实现 图的API设计 代码实现 图的实际应用 在现实生活中,有许多应用场景会包含很多点以及点点之间的连接,而这些应用场景我们都可以用即将要学习的图这种数据结构去解决. 地图: 我们生活中经常使用的地图,基本上是由城市以及连接城市的道路组成,如果我们把城市看做是一个一个的点,把道路看做是一条一条的连接,那么地图就是我们将要学习的图这种数据结构. 图的定义及分类 定义: 图是由一组顶点和一组能够将两个顶点相连的边组
-
Java锁擦除与锁粗化概念和使用详解
目录 一.什么是锁擦除 二.锁擦除的演示 三.什么是锁粗化 四.锁粗化的演示 一.什么是锁擦除 锁擦除是指虚拟机即时编译器(JIT)在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行擦除.锁擦除的主要判定依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行. 二.锁擦除的演示 public class LockErasureDemo { publi
-
Python装饰器基础概念与用法详解
本文实例讲述了Python装饰器基础概念与用法.分享给大家供大家参考,具体如下: 装饰器基础 前面快速介绍了装饰器的语法,在这里,我们将深入装饰器内部工作机制,更详细更系统地介绍装饰器的内容,并学习自己编写新的装饰器的更多高级语法. 什么是装饰器 装饰是为函数和类指定管理代码的一种方式.Python装饰器以两种形式呈现: [1]函数装饰器在函数定义的时候进行名称重绑定,提供一个逻辑层来管理函数和方法或随后对它们的调用. [2]类装饰器在类定义的时候进行名称重绑定,提供一个逻辑层来管理类,或管理随
-
java数据结构与算法之桶排序实现方法详解
本文实例讲述了java数据结构与算法之桶排序实现方法.分享给大家供大家参考,具体如下: 基本思想: 假定输入是由一个随机过程产生的[0, M)区间上均匀分布的实数.将区间[0, M)划分为n个大小相等的子区间(桶),将n个输入元素分配到这些桶中,对桶中元素进行排序,然后依次连接桶输入0 ≤A[1..n] <M辅助数组B[0..n-1]是一指针数组,指向桶(链表).将n个记录分布到各个桶中去.如果有多于一个记录分到同一个桶中,需要进行桶内排序.最后依次把各个桶中的记录列出来记得到有序序列. [桶-
-
Java中一些基础概念的使用详解
类的初始化顺序 在Java中,类里面可能包含:静态变量,静态初始化块,成员变量,初始化块,构造函数.在类之间可能存在着继承关系,那么当我们实例化一个对象时,上述各部分的加载顺序是怎样的? 首先来看代码: 复制代码 代码如下: class Parent { public static StaticVarible staticVarible= new StaticVarible("父类-静态变量1"); public StaticVarible instVaribl
-
java数据结构和算法中哈希表知识点详解
树的结构说得差不多了,现在我们来说说一种数据结构叫做哈希表(hash table),哈希表有是干什么用的呢?我们知道树的操作的时间复杂度通常为O(logN),那有没有更快的数据结构?当然有,那就是哈希表: 1.哈希表简介 哈希表(hash table)是一种数据结构,提供很快速的插入和查找操作(有的时候甚至删除操作也是),时间复杂度为O(1),对比时间复杂度就可以知道哈希表比树的效率快得多,并且哈希表的实现也相对容易,然而没有任何一种数据结构是完美的,哈希表也是:哈希表最大的缺陷就是基于数组,因
-
Java数据结构之图的两种搜索算法详解
目录 前言 深度优先搜索算法 API设计 代码实现 广度优先搜素算法 API设计 代码实现 案例应用 前言 在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求. 有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法. 学习本文前请先阅读这篇文章 [数据结构与算法]图的基础概念和数据模型. 深度优先搜索算法 所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,
-
Java数据结构之图的路径查找算法详解
目录 前言 算法详解 实现 API设计 代码实现 前言 在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地 城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市.这类问题翻译成专业问题就是: 从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径. 例如在上图上查找顶点0到顶点4的路径用红色标识出来,那么我们可以把该路径表示为 0-2-3-4. 如果对图的前置知识不了解,请查看系列文章: [数据结构与算法]图的基础概念和数据