如何利用Python获取文本中的电话号码实例代码
目录
- 前言
- 打开文本
- 正则表达式遍历电话
- 最后拼接输出
- 完整的代码↓
- 使用方法
- 补充:使用Python提取电话号码和E-mail地址
- 结语
前言
此编制利用Python的简单编程,实现获取txt文本里的电话号码。
这里小编使用了Python3.8.6,os、re库
打开文本
#事先新建文本readphone.txt,将要提取的文章内容复制到readphone.txt里。
下方为Python打开文本
TXTtemp = open("readphone.txt","r+")
txtbuffer=TXTtemp.read()
正则表达式遍历电话
利用正则表达式提取11位数字的电话号码。
patter="(?:^|[^\d])(1\d{10})(?:$|[^\d])"
phone_list=re.compile(patter).findall(txtbuffer)
最后拼接输出
输出会新建一个文档getphone.txt来存放提取到的电话(在文件夹里没有getphone.txt的时候),多次使用会自动换行填写。
with open('getphone.txt','a') as file0:
print('%s' %a,'%s' %t,'%s' %s,file=file0)
完整的代码↓
复制粘贴可直接用,这里多了datetime是为了加入时间区分是什么时候获取电话的。
import os,re,datetime
TXTtemp = open("readphone.txt","r+")
txtbuffer=TXTtemp.read()
patter="(?:^|[^\d])(1\d{10})(?:$|[^\d])"
phone_list=re.compile(patter).findall(txtbuffer)
t = 'Phone is : '
s = phone_list
a = datetime.datetime.now().date()
with open('getphone.txt','a') as file0:
print('%s' %a,'%s' %t,'%s' %s,file=file0)
close(TXTtemp)
效果图↓↓↓
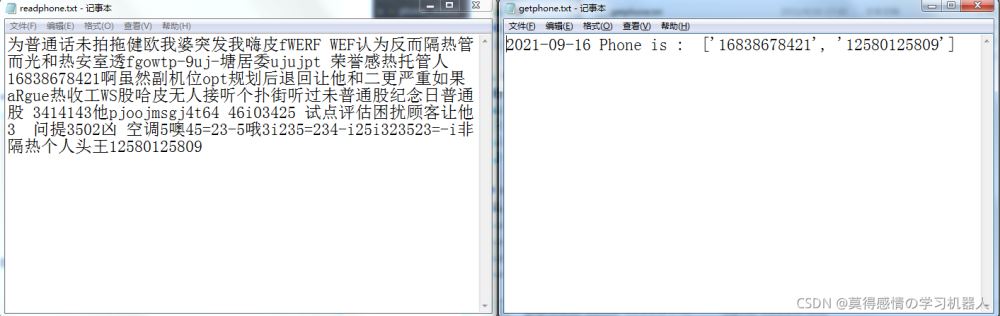
使用方法
获取文章中的电话号码(11位数)
(1)将文章粘贴到readphone.txt保存
(2)双击运行程序.py
(3)打开getphone.txt提取到的电话在里面
补充:使用Python提取电话号码和E-mail地址
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @File : PhoneAndEmail.py 项目:电话号码与Email地址提取程序
# @Software: PyCharm
"""
运行程序,从剪贴板获取文本,找出文本所有的Email地址和电话号码,然后将其粘贴到剪贴板
"""
import pyperclip, re
phoneRegex = re.compile(r'''(
(\d{3}|\(\d{3}\))? # 可选的区号
(\s|-|\.)? # 中间的分隔符
(\d{3}) # 开始的3个数字
(\s|-|\.)? # 中间的分隔符
(\d{4}) # 后面的4个数字
(\s*(ext|x|ext.)\s*(\d{2,5}))? # 可选的分机号
)''', re.VERBOSE)
emailRegex = re.compile(r'''(
[a-zA-Z0-9._%+-]+ # 用户名
@
[a-zA-Z0-9.-]+ # 域名
(\.[a-zA-Z]{2,4})
)''', re.VERBOSE)
text = pyperclip.paste()
matches = []
for groups in phoneRegex.findall(text) :
phoneNum = '-'.join([groups[1], groups[3], groups[5]])
if groups[8] != '' :
phoneNum += ' x' + groups[8]
matches.append(phoneNum)
for groups in emailRegex.findall(text) :
matches.append(groups[0])
if len(matches) > 0 :
pyperclip.copy('\n'.join(matches))
print('Copied to clipboard')
print('\n'.join(matches))
else :
print('No phone numbers or email addresses found.')
结语
到此这篇关于如何利用Python获取文本中电话号码的文章就介绍到这了,更多相关Python获取文本中电话号码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何利用Python获取文本中的电话号码实例代码
目录 前言 打开文本 正则表达式遍历电话 最后拼接输出 完整的代码↓ 使用方法 补充:使用Python提取电话号码和E-mail地址 结语 前言 此编制利用Python的简单编程,实现获取txt文本里的电话号码. 这里小编使用了Python3.8.6,os.re库 打开文本 #事先新建文本readphone.txt,将要提取的文章内容复制到readphone.txt里. 下方为Python打开文本 TXTtemp = open("readphone.txt","r+"
-
利用Python将文本中的中英文分离方法
在进行文本分析.提取关键词时,新闻评论等文本通常是中英文及其他语言的混杂,若不加处理直接分析,结果往往差强人意. 下面对中英文文本进行分离做一下总结: 1.超短文本,ASCII识别. s = "China's Legend Holdings will split its several business arms to go public on stock markets, the group's president Zhu Linan said on Tuesday.该集团总裁朱利安周二表示,
-
python动态文本进度条的实例代码
如何实现动态单行刷新,答案是--覆盖 但是怎么实现覆盖呢 关键在于不换行而且能回退到开始位置 那么就要用到 \r 这个东西就是让光标回退到当前行初始位置 记得不能让换行 上码 #文本进度条.py import time scale = 50 print("执行开始".center(scale, "-"))//居中对齐 start = time.perf_counter()//获取起始时间 for i in range(scale+1): a = i*'*' b =
-
浅析JS获取url中的参数实例代码
js获取url中的参数代码如下所示,代码简单易懂,附有注释,写的不好还请见谅! function UrlSearch() { var name, value; var str = location.href; //取得整个地址栏 var num = str.indexOf("?") str = str.substr(num + 1); //取得所有参数 stringvar.substr(start [, length ] var arr = str.split("&&
-
PHP无限循环获取MySQL中的数据实例代码
最近公司有个需求需要从MySQL获取数据,然后在页面上无线循环的翻页展示.主要就是一直点击一个按钮,然后数据从最开始循环到末尾,如果末尾的数据不够了,那么从数据的最开始取几条补充上来. 其实,这个功能可以通过JQ实现,也可以通过PHP + MYSQL实现,只不过JQ比较方便而且效率更高罢了. 每次显示10条数据. public function get_data($limit){ $sql="select * from ((select id,name from `mytable` limit
-
利用python获取某年中每个月的第一天和最后一天
搜索关键字: python get every first day of month 参考解答: 方法一: >>> import calendar >>> calendar.monthrange(2002,1) (1, 31) >>> calendar.monthrange(2008,2) (4, 29) >>> calendar.monthrange(2100,2) (0, 28) >>> calendar.mon
-
java利用htmlparser获取html中想要的代码具体实现
这两天需要做一些东西,需要抓取别人网页中的一些信息.最后用htmlparser来解析html. 直接从代码中看吧: 首先需要注意导入包为:import org.htmlparser下面的包 复制代码 代码如下: List<Mp3> mp3List = new ArrayList<Mp3>(); try{ Parser parser = new Parser(htmlStr);//初始化Parser,这里要注意导入包为org.htmlparser.
-
利用Python获取操作系统信息实例
前言 每一位运维人员都应该对自己所管理的机器配置很清楚,因为这对我们快速处理问题很有帮助,比如随着业务增长,突然某些机器负载上涨的厉害,这时候要排查原因,除了从应用程序.架构上分析外,当前硬件性能的分析应该是必不可少的一环,今天我们将不用第三方模块,用python自带模块和系统提供的运行信息来获取我们需要的信息,这个脚本除了硬件外,还抓取了当前系统进程数和网卡流量功能,所以这个版本实现的功能基本对应了之前psutil实现的内容,多的不说了,直接贴代码: #!/usr/bin/env python
-
利用Python获取赶集网招聘信息前篇
如何获取一个网站的相关信息,获取赶集网的招聘信息,本文为大家介绍利用python获取赶集网招聘信息的关键代码,供大家参考,具体内容如下 import re import urllib import urllib.request #获取赶集网数据 def begin(url): #要伪装成的浏览器(我这个是用的chrome) headers = ('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,
-
python获取网页中所有图片并筛选指定分辨率的方法
压测时,图片太少,想着下载网页中的图片,然后过滤指定分辨率,但网页中指定分辨率的图片太少了(见下) 后使用格式工厂转换图片 import urllib.request # 导入urllib模块 import re # 导入re模块 import os from PIL import Image htmlurl = 'http://www.win4000.com/wallpaper_detail_134824_3.html' downloadpath = 'C:\\Users\\yaowanjun