Python实现数据清洗的示例详解
目录
- 前言
- 去掉信息不全的用户
- 描述
- 答案
- 修补缺失的用户数据
- 描述
- 答案
- 解决牛客网用户重复的数据
- 描述
- 答案
- 统一最后刷题日期的格式
- 描述
- 答案
- 将用户的json文件转换为表格形式
- 描述
- 答案
前言
Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题
去掉信息不全的用户
描述
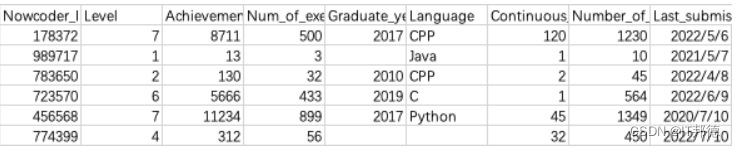
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
- Nowcoder_ID:用户ID
- Level:等级
- Achievement_value:成就值
- Num_of_exercise:刷题量
- Graduate_year:毕业年份
- Language:常用语言
- Continuous_check_in_days:最近连续签到天数
- Number_of_submissions:提交代码次数
- Last_submission_time:最后一次提交题目日期
运营同学正在做用户调研,为了保证调研的可靠性,想要去掉那些信息不全的用户,即去掉有缺失数据的行,请你帮助他去掉后输出全部数据。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
直接输出清洗后的全部数据。

答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder[Nowcoder.isna() == False])

修补缺失的用户数据
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
- Nowcoder_ID:用户ID
- Level:等级
- Achievement_value:成就值
- Num_of_exercise:刷题量
- Graduate_year:毕业年份
- Language:常用语言
- Continuous_check_in_days:最近连续签到天数
- Number_of_submissions:提交代码次数
- Last_submission_time:最后一次提交题目日期
运营同学拿到了这份用户文件,但是由于系统BUG,出现了部分缺失的值,请你使用当前的最大年份填充缺失的毕业年份(“Graduate_year”),用Python填充缺失的常用语言(“Language”),用成就值的均值(四舍五入保留整数)填充缺失的成就值(“Achievement_value”)。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出修改后的全部数据,不用处理输出时年份与成就值的小数点问题。

答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
Nowcoder["Graduate_year"].fillna(Nowcoder["Graduate_year"].max())
Nowcoder["Language"].fillna("Python")
Nowcoder["Achievement_value"].fillna(Nowcoder["Achievement_value"].mean().round(0))
print(Nowcoder)
解决牛客网用户重复的数据
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
- Nowcoder_ID:用户ID
- Level:等级
- Achievement_value:成就值
- Num_of_exercise:刷题量
- Graduate_year:毕业年份
- Language:常用语言
- Continuous_check_in_days:最近连续签到天数
- Number_of_submissions:提交代码次数
- Last_submission_time:最后一次提交题目日期
牛牛拿到这份文件的时候一脸懵逼,因为系统错误将很多相同用户的数据输出了多条,导致文件中有很多重复的行,请先检查每一行是否重复,然后输出删除重复行后的全部数据。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。

输出描述
先输出每一行是否重复,再输出去重后的文件全部数据
答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 1000)
pd.set_option('display.max_rows', None)
print(Nowcoder.duplicated())
print(Nowcoder.drop_duplicates(0))

统一最后刷题日期的格式
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
- Nowcoder_ID:用户ID
- Level:等级
- Achievement_value:成就值
- Num_of_exercise:刷题量
- Graduate_year:毕业年份
- Language:常用语言
- Continuous_check_in_days:最近连续签到天数
- Number_of_submissions:提交代码次数
- Last_submission_time:最后一次提交题目日期
运营同学发现最后一次提交题目日期这一列有各种各样的日期格式,这对于他分析用户十分不友好,你能够帮他输出用户ID、等级以及统一后的日期吗?(日期格式统一为yyyy-mm-dd)
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。

输出描述
输出用户ID、等级与最后提交日期三列,包括行号。

答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
Nowcoder['Last_submission_time'] = pd.to_datetime(Nowcoder["Last_submission_time"],format="%Y-%m-%d")
print(Nowcoder[['Nowcoder_ID','Level','Last_submission_time']])

将用户的json文件转换为表格形式
描述
现有一个Nowcoder.json文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
- Nowcoder_ID:用户ID
- Level:等级
- Achievement_value:成就值
- Graduate_year:毕业年份
- Language:常用语言
如果你读入了这个json文件,能将其转换为pandas的DataFrame格式吗?
输入描述:
数据集直接从当前目录下的Nowcoder.json文件中读取。

输出描述:
输出转换为DataFrame的全部数据,包括行号。

答案
import pandas as pd
import json
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
with open('Nowcoder.json', 'r') as f:
data = json.loads(f.read())
df = pd.DataFrame.from_dict(data)
print(df)

以上就是Python实现数据清洗的示例详解的详细内容,更多关于Python数据清洗的资料请关注我们其它相关文章!
相关推荐
-

利用Python进行数据清洗的操作指南
目录 缺失值 异常值 数据不一致 无效数据 重复数据 数据泄漏问题 你一定听说过这句著名的数据科学名言: 在数据科学项目中, 80% 的时间是在做数据处理. 如果你没有听过,那么请记住:数据清洗是数据科学工作流程的基础. 机器学习模型会根据你提供的数据执行,混乱的数据会导致性能下降甚至错误的结果,而干净的数据是良好模型性能的先决条件. 当然干净的数据并不意味着一直都有好的性能,模型的正确选择(剩余 20%)也很重要,但是没有干净的数据,即使是再强大的模型也无法达到预期的水平. 在本文中将列出数据
-
python数据清洗中的时间格式化实现
目录 1.字符串转时间 2.时间转字符串 3.时间戳相互转换 4.python中时间日期格式化符号: 1.字符串转时间 from datetime import datetime t = '2020年11月11日15:04:41' time = datetime.strptime(t,'%Y年%m月%d日%H:%M:%S') print(time) # 结果:2020-11-11 15:04:41 t1 = '2020-11-11 15:04:41' time1 = datetime.strpt
-
python3常用的数据清洗方法(小结)
首先载入各种包: import pandas as pd import numpy as np from collections import Counter from sklearn import preprocessing from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 p
-
如何用python清洗文件中的数据
目录 使用filter 清洗数据同时记录订单号并排序 简单版 直接打开日志文件,往另外一个文件中按照要过滤的要求进行过滤 import io; with open('a.txt', 'w') as f: for line in open('c:/201509.txt'): if line.find('更改项目')>0 and line.find('500')>0: f.write(line+"\n"); print("输出完成"); 注意.find返回的
-
Python 八个数据清洗实例代码详解
如果你经历过数据清洗的过程,你就会明白我的意思.而这正是撰写这篇文章的目的——让读者更轻松地进行数据清洗工作. 事实上,我在不久前意识到,在进行数据清洗时,有一些数据具有相似的模式.也正是从那时起,我开始整理并编译了一些数据清洗代码,我认为这些代码也适用于其它的常见场景. 由于这些常见的场景涉及到不同类型的数据集,因此本文更加侧重于展示和解释这些代码可以用于完成哪些工作,以便读者更加方便地使用它们. 数据清洗小工具箱 在下面的代码片段中,数据清洗代码被封装在了一些函数中,代码的目的十分直观.你可
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常
-
8段用于数据清洗Python代码(小结)
最近,大数据工程师Kin Lim Lee在Medium上发表了一篇文章,介绍了8个用于数据清洗的Python代码. 数据清洗,是进行数据分析和使用数据训练模型的必经之路,也是最耗费数据科学家/程序员精力的地方. 这些用于数据清洗的代码有两个优点:一是由函数编写而成,不用改参数就可以直接使用.二是非常简单,加上注释最长的也不过11行.在介绍每一段代码时,Lee都给出了用途,也在代码中也给出注释.大家可以把这篇文章收藏起来,当做工具箱使用. 涵盖8大场景的数据清洗代码 这些数据清洗代码,一共涵盖8个
-
Python实现数据清洗的示例详解
目录 前言 去掉信息不全的用户 描述 答案 修补缺失的用户数据 描述 答案 解决牛客网用户重复的数据 描述 答案 统一最后刷题日期的格式 描述 答案 将用户的json文件转换为表格形式 描述 答案 前言 Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题 去掉信息不全的用户 描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID Level:等级 Achievement_value
-
对python周期性定时器的示例详解
一.用thread实现定时器 py_timer.py文件 #!/usr/bin/python #coding:utf-8 import threading import os import sys class _Timer(threading.Thread): def __init__(self, interval, function, args=[], kwargs={}): threading.Thread.__init__(self) self.interval = interval se
-
python assert的用处示例详解
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单.在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助.本文主要是讲assert断言的基础知识. python assert断言的作用 python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假.可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为
-
python音频处理的示例详解
准备工作: 首先,我们需要 import 几个工具包,一个是 python 标准库中的 wave 模块,用于音频处理操作,另外两个是 numpy 和 matplot,提供数据处理函数. 一:读取本地音频数据 处理音频第一步是需要从让计算机"听到"声音,这里我们使用 python 标准库中自带的 wave模块进行音频参数的获取. (1) 导入 wave 模块 (2) 使用 wave 中的函数 open 打开音频文件,wave.open(file,mode)函数带有两个参数, 第一个 fi
-
Python模块glob函数示例详解教程
目录 本文大纲 支持4个常用的通配符 1)glob()函数 2)iglob()函数 3)escape()函数 总结 本文大纲 glob模块也是Python标准库中一个重要的模块,主要用来查找符合特定规则的目录和文件,并将搜索的到的结果返回到一个列表中.使用这个模块最主要的原因就是,该模块支持几个特殊的正则通配符,用起来贼方便,这个将会在下方为大家进行详细讲解. 支持4个常用的通配符 使用glob模块能够快速查找我们想要的目录和文件,就是由于它支持*.**.? .[ ]这三个通配符,那么它们到底是
-
python opencv图像处理基本操作示例详解
目录 1.图像基本操作 ①读取图像 ②显示图像 ③视频读取 ④图像截取 ⑤颜色通道提取及还原 ⑥边界填充 ⑦数值计算 ⑧图像融合 2.阈值与平滑处理 ①设定阈值并对图像处理 ②图像平滑-均值滤波 ③图像平滑-方框滤波 ④图像平滑-高斯滤波 ⑤图像平滑-中值滤波 3.图像的形态学处理 ①腐蚀操作 ②膨胀操作 ③开运算和闭运算 4.图像梯度处理 ①梯度运算 ②礼帽与黑帽 ③图像的梯度处理 5.边缘检测 ①Canny边缘检测 1.图像基本操作 ①读取图像 ②显示图像 该函数中,name是显示窗口的名字
-
Python深度学习线性代数示例详解
目录 标量 向量 长度.维度和形状 矩阵 张量 张量算法的基本性质 降维 点积 矩阵-矩阵乘法 范数 标量 标量由普通小写字母表示(例如,x.y和z).我们用 R \mathbb{R} R表示所有(连续)实数标量的空间. 标量由只有一个元素的张量表示.下面代码,我们实例化了两个标量,并使用它们执行一些熟悉的算数运算,即加法.乘法.除法和指数. import torch x = torch.tensor([3.0]) y = torch.tensor([2.0]) x + y, x * y, x
-
Python OpenCV形态学运算示例详解
目录 1. 腐蚀 & 膨胀 1.1什么是腐蚀&膨胀 1.2 腐蚀方法 cv2.erode() 1.3 膨胀方法 cv2.dilate() 2. 开运算 & 闭运算 2.1 简述 2.2 开运算 2.3 闭运算 3. morphologyEx()方法 3.1 morphologyEx()方法 介绍 3.2 梯度运算 3.3 顶帽运算 3.4 黑帽运算 1. 腐蚀 & 膨胀 1.1什么是腐蚀&膨胀 腐蚀&膨胀是图像形态学中的两种核心操作 腐蚀可以描述为是让图像沿
-
Python 异步之生成器示例详解
目录 正文 1. 什么是异步生成器 1.1. Generators 1.2. Asynchronous Generators 2. 如何使用异步生成器 2.1. 定义 2.2. 创建 2.3. 一步 2.4. 遍历 3. 异步生成器示例 正文 生成器是 Python 的基本组成部分.生成器是一个至少有一个“yield”表达式的函数.它们是可以暂停和恢复的函数,就像协程一样. 实际上,Python 协程是 Python 生成器的扩展.Asyncio 允许我们开发异步生成器.我们可以通过定义一个使用
-
Python中Json使用示例详解
目录 Python Json使用 1.dict 转成 json (json.dumps(dict)) 2.json 转 dict (json.loads(jsonstr)) 3. 类对象转 json (dict属性/提供default=方法) 3.1 错误使用 3.2 使用类对象 dict 属性 3.3 提供一个 convert2json 方法 4.json 转 类对象 (json.loads(jsonstr,object_hook=..)) 5. dict/对象 转为 json文件 (json