Python使用execjs执行包含中文参数的JavaScript
抓取到了一段包含数据的JavaScript代码:
import re
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
}
res = requests.get(
"https://www.kuaikanmanhua.com/web/comic/100868/",
headers=headers
)
script = re.findall(
"<script>window.__NUXT__=([^<]+);</script>", res.text)[0].replace('\\u002F', "/")
script
结果:

这段代码直接在游览器执行可以得到对应的JSON数据,那么我们如何使用python执行这段代码获取JS数据呢?答案是使用execjs。
安装:
pip install PyExecJS
但是如果此时在安装过Nodejs的windows上直接执行代码:
import execjs execjs.eval(script)
会报出如下错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa4 in position 447: illegal multibyte sequence
此时我们需要重新指定execjs的环境为JScript:
import os os.environ["EXECJS_RUNTIME"] = "JScript"
再次执行可以顺利得到结果。
如果我们确实需要使用本地nodejs的环境执行JavaScript则需要修改修改execjs的源码:
import os os.environ["EXECJS_RUNTIME"] = "Node" print(execjs.get().name)
Node.js (V8)
找到execjs安装目录下的_external_runtime.py文件:
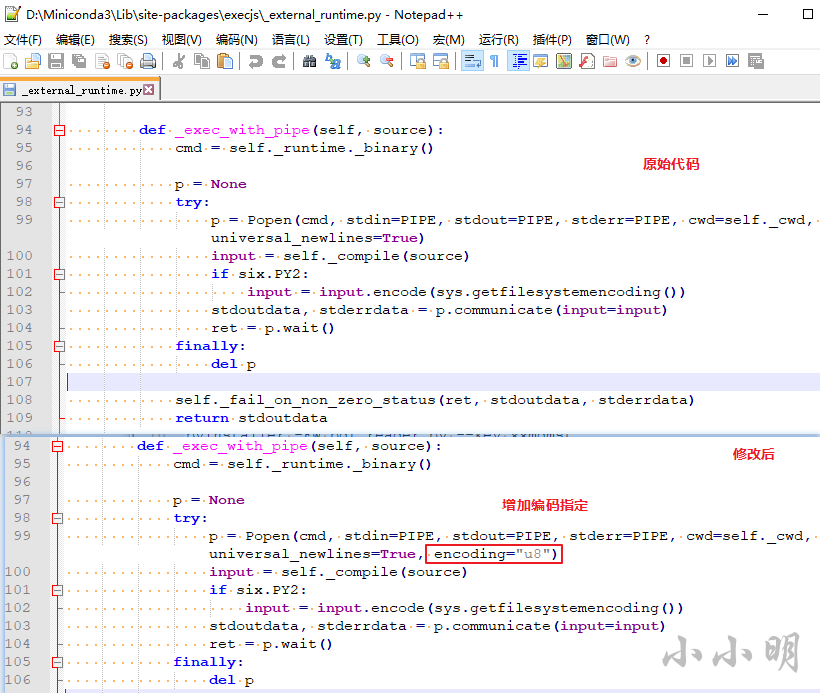
重启程序再次执行即可得到结果:

execjs的调用函数或读取变量示例:
import execjs
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
v = add(3, 4);
""")
print(ctx.call("add", 1, 2), ctx.eval("v"))
3 7
Lib\site-packages\execjs\runtime_names.py文件可以看到execjs所支持的JavaScript环境:
PyV8 = "PyV8" Node = "Node" JavaScriptCore = "JavaScriptCore" SpiderMonkey = "SpiderMonkey" JScript = "JScript" PhantomJS = "PhantomJS" SlimerJS = "SlimerJS" Nashorn = "Nashorn"
总结
到此这篇关于Python使用execjs执行包含中文参数JavaScript的文章就介绍到这了,更多相关execjs执行包含中文参数js内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用pyexecjs代码案例解析
针对现在大部分的网站都是使用js加密,js加载的,并不能直接抓取出来,这时候就不得不适用一些三方类库来执行js语句 execjs,一个比较好用且容易上手的类库(支持py2,与py3),支持 JS runtime. 官网:https://pypi.org/project/PyExecJS/ # pip install pyexecjs # 一node.js为引擎 # 检测运行环境 import execjs print(execjs.get().name) 最简单的代码案例 使用eval执行js代
-
Python利用PyExecJS库执行JS函数的案例分析
在Web渗透流程的暴力登录场景和爬虫抓取场景中,经常会遇到一些登录表单用DES之类的加密方式来加密参数,也就是说,你不搞定这些前端加密,你的编写的脚本是不可能Login成功的.针对这个问题,现在有三种解决方式: ①看懂前端的加密流程,然后用脚本编写这些方法(或者找开源的源码),模拟这个加密的流程.缺点是:不懂JS的话,看懂的成本就比较高了: ②selenium + Chrome Headless.缺点是:因为是模拟点击,所以效率相对①.③低一些: ③使用语言调用JS引擎来执行JS函数.缺点是
-
Python基于execjs运行js过程解析
execjs 使用 有了selenium+Chrome Headless 加载页面为什么还要用execjs来运行js? selenium+Chrome Headless 必然是爬虫的一大利器,可是缺点依然存在, 性能问题不可忽视. 但这构不成舍弃它而不用的理由.我认为舍弃包括Chrome Headless.PhantomJS在内的无头浏览器的原因主要有以下几点: 1. 页面结构改变.弹窗(一些网站的页面结构经常无规则改变), 影响代码的健壮性. 2. 无头浏览器的应用场景主要是一些模拟登陆账号密
-
python爬虫 execjs安装配置及使用
模块安装 参考官方文档安装 pip install PyExecJS 配置 该模块需要JS运行时环境 以下JS runtime经过官方测试认可,建议采用 PyV8:一个调用Google V8引擎的Python模块 Node.js 本文采用该运行时 PhantomJS Nashorn 以下JS runtime也支持但未经过官方测试 Apple JavaScriptCore - Included with Mac OS X JScript :windows自带JS解释器,IE浏览器 SlimerJS
-

Python使用execjs执行包含中文参数的JavaScript
抓取到了一段包含数据的JavaScript代码: import re import requests headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36", "accept": "text/html,applicat
-
python通过urllib2获取带有中文参数url内容的方法
本文实例讲述了python通过urllib2获取带有中文参数url内容的方法.分享给大家供大家参考.具体如下: 对于中文的参数如果不进行编码的话,python的urllib2直接处理会报错,我们可以先将中文转换成utf-8编码,然后使用urllib2.quote方法对参数进行url编码后传递. content = u'你好 jb51.net' content = content.encode('utf-8') content = urllib2.quote(content) api_url =
-
Python查找文件中包含中文的行方法
前言 近几天在做多语言版本的时候再次发现,区分各种语言真的是一件比较困难的事情,上一次做中文提取工具的就花了不少时间,这次决定用python试一试,结果写起来发现真是方便不少,自己整理了一下方便以后查找使用. 代码 #!/usr/bin/env python3 # -*- coding: utf-8 -*- # find the line of containing chinese in files __author__ = 'AlbertS' import re def start_find_
-
asp.net URL中包含中文参数造成乱码的解决方法
问题: 前段时间,在系统中做了一个类似于友情链接的功能块,一直运行良好,直到有一天加了类似于以下的链接地址:http://www.****.com/user.aspx?id=水天,就出现大问题了: 1.从IE地址栏中直接输入这个地址,访问没错: 2.做一个静态页,其中包括这个超链接,点击访问也没错: 3.就是把这个链接添加到这个功能块中,点击访问那边接收到的是乱码. 一开始,被这个问题也搞得头大,在google了一把后,总算是把问题给搞清楚了,其实只要这个链接地址不经过任何编码传递是不会有问题的
-
在python image 中实现安装中文字体
如果一些应用需要到中文字体(如果pygraphviz,不安装中文字体,中文会显示乱码),就要在image 中安装中文字体. 默认 python image 是不包含中文字体的: mac-temp:relation_graph test$ docker run --rm -it python bash root@36d738e2084c:/# fc-list /usr/share/fonts/truetype/dejavu/DejaVuSerif-Bold.ttf: DejaVu Serif:st
-
python通过getopt模块如何获取执行的命令参数详解
前言 python脚本和shell脚本一样可以获取命令行的参数,根据不同的参数,执行不同的逻辑处理. 通常我们可以通过getopt模块获得不同的执行命令和参数.下面话不多说了,来一起看看详细的介绍吧. 方法如下: 下面我通过新建一个test.py的脚本解释下这个模块的的使用 #!/usr/bin/python # -*- coding: utf-8 -*- import sys import getopt if __name__=='__main__': print sys.argv opts,
-
执行python脚本并传入json数据格式参数方式
目录 执行python脚本并传入json数据格式参数 python解析JSON数据 json模块包含以下两个函数 执行python脚本并传入json数据格式参数 最近在写一个python的数据统计分析脚本,需要根据json的数据格式参数去进行业务逻辑处理,出了一些情况拿出来一起分享讨论.一下代码纯属示例. 脚本类容很简单,接收一下参数,并使用json包进行一个加载解析. 执行脚本,传入一个json对象数组: 脚本接受到的内容: json加载解析出错: 可以看到python脚本接收到参数的时候会将
-
Python使用修饰器执行函数的参数检查功能示例
本文实例讲述了Python使用修饰器执行函数的参数检查功能.分享给大家供大家参考,具体如下: 参数检查:1. 参数的个数:2. 参数的类型:3. 返回值的类型. 考虑如下的函数: import html def make_tagged(text, tag): return '<{0}>{1}</{0}>'.format(tag, html.escape(text)) 显然我们希望传递进来两个参数,且参数类型/返回值类型均为str,再考虑如下的函数: def repeat(what,
-
python自动提取文本中的时间(包含中文日期)
有时在处理不规则数据时需要提取文本包含的时间日期. dateutil.parser模块可以统一日期字符串格式. datefinder模块可以在字符串中提取日期. datefinder模块实现也是用正则,功能很全 但是对中文不友好. 但是这两个模块都不能支持中文及一些特殊的情况:所以我用正则写了段代码可进行中文日期及一些特殊的时间识别 例如: '2012年12月12日','3小时前','在2012/12/13哈哈','时间2012-12-11 12:22:30','日期2012-13-11','测
-
解决Python传递中文参数的问题
今天有个需要需要传递中文参数给URL 但是在GBK环境下的脚本传递GBK的参数老是给我报UNICODE的解码错误.烦的很. 所以我们果断选择用urlencode来处理中文, 由于国内外网站编码不同,国内是GBK的,国外是UTF8的. >>> import sys >>> sys.stdin.encoding 'GBK' 表示我们的环境是GBK的 >>> import urllib >>> urllib.quote('编码坑爹') '%