Activiti工作流学习笔记之自动生成28张数据库表的底层原理解析
网上关于工作流引擎Activiti生成表的机制大多仅限于四种策略模式,但其底层是如何实现的,相关文章还是比较少,因此,觉得撸一撸其生成表机制的底层原理。
我接触工作流引擎Activiti已有两年之久,但一直都只限于熟悉其各类API的使用,对底层的实现,则存在较大的盲区。
Activiti这个开源框架在设计上,其实存在不少值得学习和思考的地方,例如,框架用到以命令模式、责任链模式、模板模式等优秀的设计模式来进行框架的设计。
故而,是值得好好研究下Activiti这个框架的底层实现。
我在工作当中现阶段用的比较多是Activiti6.0版本,本文就以这个版本来展开分析。
在使用Activiti工作流引擎过程中,让我比较好奇的一个地方,是框架自带一套数据库表结构,在首次启动时,若设计了相应的建表策略时,将会自动生成28张表,而这些表都是以ACT_开头。
那么问题来了,您是否与我一样,曾好奇过这些表都是怎么自动生成的呢?
下面,就开始一点点深入研究——
在工作流Springboot+Activiti6.0集成框架,网上最常见的引擎启动配置教程一般长这样:
@Configuration
public class SpringBootActivitiConfig {
@Bean
public ProcessEngine processEngine(){
ProcessEngineConfiguration pro=ProcessEngineConfiguration.createStandaloneProcessEngineConfiguration();
pro.setJdbcDriver("com.mysql.jdbc.Driver");
pro.setJdbcUrl("xxxx");
pro.setJdbcUsername("xxxx");
pro.setJdbcPassword("xxx");
//避免发布的图片和xml中文出现乱码
pro.setActivityFontName("宋体");
pro.setLabelFontName("宋体");
pro.setAnnotationFontName("宋体");
//数据库更更新策略
pro.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
return pro.buildProcessEngine();
}
@Bean
public RepositoryService repositoryService(){
return processEngine().getRepositoryService();
}
@Bean
public RuntimeService runtimeService(){
return processEngine().getRuntimeService();
}
@Bean
public TaskService taskService(){
return processEngine().getTaskService();
}
......
}
其中,方法pro.setDatabaseSchemaUpdate()可对工作流引擎自带的28张表进行不同策略的更新。
Activiti6.0版本总共有四种数据库表更新策略。
查看这三种策略的静态常量标识,分别如下:
public abstract class ProcessEngineConfiguration {
public static final String DB_SCHEMA_UPDATE_FALSE = "false";
public static final String DB_SCHEMA_UPDATE_CREATE_DROP = "create-drop";
public static final String DB_SCHEMA_UPDATE_TRUE = "true";
......
}
public abstract class ProcessEngineConfigurationImpl extends ProcessEngineConfiguration {
public static final String DB_SCHEMA_UPDATE_DROP_CREATE = "drop-create";
......
}
- flase:默认值,引擎启动时,自动检查数据库里是否已有表,或者表版本是否匹配,如果无表或者表版本不对,则抛出异常。(常用在生产环境);
- true:若表不存在,自动更新;若存在,而表有改动,则自动更新表,若表存在以及表无更新,则该策略不会做任何操作。(一般用在开发环境);
- create_drop:启动时自动建表,关闭时就删除表,有一种临时表的感觉。(需手动关闭,才会起作用);
- drop-create:启动时删除旧表,再重新建表。(无需手动关闭就能起作用);
整个启动更新数据库的过程都是围绕这四种策略,接下来就以这四种策略为主题,撸一下自动更新据库表的底层原理,这一步骤是在引擎启动时所执行的buildProcessEngine()方法里实现。
从该buildProcessEngine方法名上便可以看出,这是一个初始化工作流引擎框架的方法。

从这里开始,一步一步debug去分析源码实现。
一.初始化工作流的buildProcessEngine()方法——
processEngineConfiguration.buildProcessEngine()是一个抽象方法,主要功能是初始化引擎,获取到工作流的核心API接口:ProcessEngine。通过该API,可获取到引擎所有的service服务。
进入processEngine接口,可以看到,其涵盖了Activiti的所有服务接口:
public interface ProcessEngine {
public static String VERSION = "6.0.0.4";
String getName();
void close();
//流程运行服务类,用于获取流程执行相关信息
RepositoryService getRepositoryService();
//流程运行服务类,用于获取流程执行相关信息
RuntimeService getRuntimeService();
//内置表单,用于工作流自带内置表单的设置
FormService getFormService();
//任务服务类,用户获取任务信息
TaskService getTaskService();
//获取正在运行或已经完成的流程实例历史信息
HistoryService getHistoryService();
//创建、更新、删除、查询群组和用户
IdentityService getIdentityService();
//流程引擎的管理与维护
ManagementService getManagementService();
//提供对流程定义和部署存储库的访问的服务。
DynamicBpmnService getDynamicBpmnService();
//获取配置类
ProcessEngineConfiguration getProcessEngineConfiguration();
//提供对内置表单存储库的访问的服务。
FormRepositoryService getFormEngineRepositoryService();
org.activiti.form.api.FormService getFormEngineFormService();
}
buildProcessEngine()有三个子类方法的重写,默认是用ProcessEngineConfigurationImpl类继承重写buildProcessEngine初始化方法,如下图所示:

该buildProcessEngine重写方法如下:
@Override
public ProcessEngine buildProcessEngine() {
//初始化的方法
init();
//创建ProcessEngine
ProcessEngineImpl processEngine = new ProcessEngineImpl(this);
// Activiti 5引擎的触发装置
if (isActiviti5CompatibilityEnabled && activiti5CompatibilityHandler != null) {
Context.setProcessEngineConfiguration(processEngine.getProcessEngineConfiguration());
activiti5CompatibilityHandler.getRawProcessEngine();
}
postProcessEngineInitialisation();
return processEngine;
}
init()方法里面包含各类需要初始化的方法,涉及到很多东西,这里先暂不一一展开分析,主要先分析与数据库连接初始化相关的逻辑。Activiti6.0底层是通过mybatis来操作数据库的,下面主要涉及到mybatis的连接池与SqlSessionFactory 的创建。
1.initDataSource():实现动态配置数据库DataSource源
protected boolean usingRelationalDatabase = true;
if (usingRelationalDatabase) {
initDataSource();
}
该数据库连接模式初始化的意义如何理解,这就需要回到最初引擎配置分析,其中里面有这样一部分代码:
pro.setJdbcDriver("com.mysql.jdbc.Driver");
pro.setJdbcUrl("xxxx");
pro.setJdbcUsername("xxxx");
pro.setJdbcPassword("xxx");
这部分设置的东西,都是数据库相关的参数,它将传到initDataSource方法里,通过mybatis默认的连接池PooledDataSource进行设置,可以说,这个方法主要是用来创建mybatis连接数据库的连接池,从而生成数据源连接。
public void initDataSource() {
//判断数据源dataSource是否存在
if (dataSource == null) {
/
//判断是否使用JNDI方式连接数据源
if (dataSourceJndiName != null) {
try {
dataSource = (DataSource) new InitialContext().lookup(dataSourceJndiName);
} catch (Exception e) {
......
}
//使用非JNDI方式且数据库地址不为空,走下面的设置
} else if (jdbcUrl != null) {
//jdbc驱动为空或者jdbc连接账户为空
if ((jdbcDriver == null) || (jdbcUsername == null)) {
......
}
//创建mybatis默认连接池PooledDataSource对象,这里传进来的,就是上面pro.setJdbcDriver("com.mysql.jdbc.Driver")配置的参数,
//debug到这里,就可以清晰明白,配置类里设置的JdbcDriver、JdbcUrl、JdbcUsername、JdbcPassword等,就是为了用来创建连接池需要用到的;
PooledDataSource pooledDataSource = new PooledDataSource(ReflectUtil.getClassLoader(), jdbcDriver, jdbcUrl, jdbcUsername, jdbcPassword);
if (jdbcMaxActiveConnections > 0) {
//设置最大活跃连接数
pooledDataSource.setPoolMaximumActiveConnections(jdbcMaxActiveConnections);
}
if (jdbcMaxIdleConnections > 0) {
// 设置最大空闲连接数
pooledDataSource.setPoolMaximumIdleConnections(jdbcMaxIdleConnections);
}
if (jdbcMaxCheckoutTime > 0) {
// 最大checkout 时长
pooledDataSource.setPoolMaximumCheckoutTime(jdbcMaxCheckoutTime);
}
if (jdbcMaxWaitTime > 0) {
// 在无法获取连接时,等待的时间
pooledDataSource.setPoolTimeToWait(jdbcMaxWaitTime);
}
if (jdbcPingEnabled == true) {
//是否允许发送测试SQL语句
pooledDataSource.setPoolPingEnabled(true);
......
dataSource = pooledDataSource;
}
......
}
//设置数据库类型
if (databaseType == null) {
initDatabaseType();
}
}
initDatabaseType()作用是设置工作流引擎的数据库类型。在工作流引擎里,自带的28张表,其实有区分不同的数据库,而不同数据库其建表语句存在一定差异。
进入到 initDatabaseType()方法看看其是如何设置数据库类型的——
public void initDatabaseType() {
Connection connection = null;
try {
connection = this.dataSource.getConnection();
DatabaseMetaData databaseMetaData = connection.getMetaData();
String databaseProductName = databaseMetaData.getDatabaseProductName();
this.databaseType = databaseTypeMappings.getProperty(databaseProductName);
......
} catch (SQLException var12) {
......
} finally {
......
}
}
进入到databaseMetaData.getDatabaseProductName()方法里,可以看到这是一个接口定义的方法:
String getDatabaseProductName() throws SQLException;
这个方法在java.sql包中的DatabaseMetData接口里被定义,其作用是搜索并获取数据库的名称。这里配置使用的是mysql驱动,那么就会被mysql驱动中的jdbc中的DatabaseMetaData实现,如下代码所示:
package com.mysql.cj.jdbc; public class DatabaseMetaData implements java.sql.DatabaseMetaData
在该实现类里,其重写的方法中,将会返回mysql驱动对应的类型字符串:
@Override
public String getDatabaseProductName() throws SQLException {
return "MySQL";
}
故而,就会返回“MySql”字符串,并赋值给字符串变量databaseProductName,再将databaseProductName当做参数传给
databaseTypeMappings.getProperty(databaseProductName),最终会得到一个 this.databaseType =“MySQL”,也就是意味着,设置了数据库类型databaseType的值为mysql。注意,这一步很重要,因为将在后面生成表过程中,会判断该databaseType的值究竟是代表什么数据库类型。
String databaseProductName = databaseMetaData.getDatabaseProductName(); this.databaseType = databaseTypeMappings.getProperty(databaseProductName);
该方法对SqlSessionFactory进行 初始化创建:SqlSessionFactory是mybatis的核心类,简单的讲,创建这个类,接下来就可以进行增删改查与事务操作了。
protected boolean usingRelationalDatabase = true;
if (usingRelationalDatabase) {
initSqlSessionFactory();
}
init()主要都是初始化引擎环境的相关操作,里面涉及到很多东西,但在本篇文中主要了解到这里面会创建线程池以及mybatis相关的初始创建即可。
二、开始进行processEngine 的创建
ProcessEngineImpl processEngine = new ProcessEngineImpl(this);
这部分代码,就是创建Activiti的各服务类了:
public ProcessEngineImpl(ProcessEngineConfigurationImpl processEngineConfiguration) {
this.processEngineConfiguration = processEngineConfiguration;
this.name = processEngineConfiguration.getProcessEngineName();
this.repositoryService = processEngineConfiguration.getRepositoryService();
this.runtimeService = processEngineConfiguration.getRuntimeService();
this.historicDataService = processEngineConfiguration.getHistoryService();
this.identityService = processEngineConfiguration.getIdentityService();
this.taskService = processEngineConfiguration.getTaskService();
this.formService = processEngineConfiguration.getFormService();
this.managementService = processEngineConfiguration.getManagementService();
this.dynamicBpmnService = processEngineConfiguration.getDynamicBpmnService();
this.asyncExecutor = processEngineConfiguration.getAsyncExecutor();
this.commandExecutor = processEngineConfiguration.getCommandExecutor();
this.sessionFactories = processEngineConfiguration.getSessionFactories();
this.transactionContextFactory = processEngineConfiguration.getTransactionContextFactory();
this.formEngineRepositoryService = processEngineConfiguration.getFormEngineRepositoryService();
this.formEngineFormService = processEngineConfiguration.getFormEngineFormService();
if (processEngineConfiguration.isUsingRelationalDatabase() && processEngineConfiguration.getDatabaseSchemaUpdate() != null) {
commandExecutor.execute(processEngineConfiguration.getSchemaCommandConfig(), new SchemaOperationsProcessEngineBuild());
}
......
}
注意,这里面有一段代码,整个引擎更新数据库的相应策略是具体实现,就在这里面:
if (processEngineConfiguration.isUsingRelationalDatabase() && processEngineConfiguration.getDatabaseSchemaUpdate() != null) {
commandExecutor.execute(processEngineConfiguration.getSchemaCommandConfig(), new SchemaOperationsProcessEngineBuild());
}
- processEngineConfiguration.isUsingRelationalDatabase()默认是true,即代表需要对数据库模式做设置,例如前面初始化的dataSource数据源,创建SqlSessionFactory等,这些都算是对数据库模式进行设置;若为false,则不会进行模式设置与验证,需要额外手动操作,这就意味着,引擎不能验证模式是否正确。
- processEngineConfiguration.getDatabaseSchemaUpdate()是用户对数据库更新策略的设置,如,前面配置类里设置了pro.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE),若设置四种模式当中的任何一种,就意味着,需要对引擎的数据库进行相应策略操作。
综上,if()判断为true,就意味着,将执行括号里的代码,这块功能就是根据策略去对数据库进行相应的增删改查操作。
commandExecutor.execute()是一个典型的命令模式,先暂时不深入分析,直接点开new SchemaOperationsProcessEngineBuild()方法。
public final class SchemaOperationsProcessEngineBuild implements Command<Object> {
public Object execute(CommandContext commandContext) {
DbSqlSession dbSqlSession = commandContext.getDbSqlSession();
if (dbSqlSession != null) {
dbSqlSession.performSchemaOperationsProcessEngineBuild();
}
return null;
}
}
进入到dbSqlSession.performSchemaOperationsProcessEngineBuild()方法中,接下来,将会看到,在这个方法当中,将根据不同的if判断,执行不同的方法——而这里的不同判断,正是基于四种数据库更新策略来展开的,换句话说,这个performSchemaOperationsProcessEngineBuild方法,才是真正去判断不同策略,从而根据不同策略来对数据库进行对应操作:
public void performSchemaOperationsProcessEngineBuild() {
String databaseSchemaUpdate = Context.getProcessEngineConfiguration().getDatabaseSchemaUpdate();
log.debug("Executing performSchemaOperationsProcessEngineBuild with setting " + databaseSchemaUpdate);
//drop-create模式
if ("drop-create".equals(databaseSchemaUpdate)) {
try {
this.dbSchemaDrop();
} catch (RuntimeException var3) {
}
}
if (!"create-drop".equals(databaseSchemaUpdate) && !"drop-create".equals(databaseSchemaUpdate) && !"create".equals(databaseSchemaUpdate)) {
//false模式
if ("false".equals(databaseSchemaUpdate)) {
this.dbSchemaCheckVersion();
} else if ("true".equals(databaseSchemaUpdate)) {
//true模式
this.dbSchemaUpdate();
}
} else {
//create_drop模式
this.dbSchemaCreate();
}
}
这里主要以true模式来讲解,其他基本都类似的实现。
public String dbSchemaUpdate() {
String feedback = null;
//判断是否需要更新,默认是false
boolean isUpgradeNeeded = false;
int matchingVersionIndex = -1;
//判断是否需要更新或者创建引擎核心engine表,若isEngineTablePresent()为true,表示需要更新,若为false,则需要新创建
if (isEngineTablePresent()) {
......
} else {
//创建表方法,稍后会详细分析
dbSchemaCreateEngine();
}
//判断是否需要创建或更新历史相关表
if (this.isHistoryTablePresent()) {
if (isUpgradeNeeded) {
this.dbSchemaUpgrade("history", matchingVersionIndex);
}
} else if (this.dbSqlSessionFactory.isDbHistoryUsed()) {
this.dbSchemaCreateHistory();
}
//判断是否需要更新群组和用户
if (this.isIdentityTablePresent()) {
if (isUpgradeNeeded) {
this.dbSchemaUpgrade("identity", matchingVersionIndex);
}
} else if (this.dbSqlSessionFactory.isDbIdentityUsed()) {
this.dbSchemaCreateIdentity();
}
return feedback;
}
这里以判断是否需要创建engine表为例,分析下isEngineTablePresent()里面是如何做判断的。其他如历史表、用户表,其判断是否需要创建的逻辑,是类型的。
点击isEngineTablePresent()进去——
public boolean isEngineTablePresent() {
return isTablePresent("ACT_RU_EXECUTION");
}
进入到isTablePresent("ACT_RU_EXECUTION")方法里,其中有一句最主要的代码:
tables = databaseMetaData.getTables(catalog, schema, tableName, JDBC_METADATA_TABLE_TYPES); return tables.next();
这两行代码大概意思是,通过"ACT_RU_EXECUTION"表名去数据库中查询该ACT_RU_EXECUTION表是否存在,若不存在,返回false,说明还没有创建;若存在,返回true。
返回到该方法上层,当isEngineTablePresent()返回值是false时,说明还没有创建Activiti表,故而,将执行 dbSchemaCreateEngine()方法来创建28表张工作流表。
if (isEngineTablePresent()) {
......
} else {
//创建表方法
dbSchemaCreateEngine();
}
进入到dbSchemaCreateEngine()方法——里面调用了executeMandatorySchemaResource方法,传入"create"与 "engine",代表着创建引擎表的意思。
protected void dbSchemaCreateEngine() {
this.executeMandatorySchemaResource("create", "engine");
}
继续进入到executeMandatorySchemaResource里面——
public void executeMandatorySchemaResource(String operation, String component) {
this.executeSchemaResource(operation, component, this.getResourceForDbOperation(operation, operation, component), false);
}
跳转到这里时,有一个地方需要注意一下,即调用的this.getResourceForDbOperation(operation, operation, component)方法,这方法的作用,是为了获取sql文件所存放的相对路径,而这些sql,就是构建工作流28张表的数据库sql。因此,我们先去executeSchemaResource()方法里看下——
public String getResourceForDbOperation(String directory, String operation, String component) {
String databaseType = this.dbSqlSessionFactory.getDatabaseType();
return "org/activiti/db/" + directory + "/activiti." + databaseType + "." + operation + "." + component + ".sql";
}
这里的directory即前边传进来的"create",databaseType的值就是前面获取到的“mysql”,而component则是"engine",因此,这字符串拼接起来,就是:"org/activiti/db/create/activiti.mysql.create.engine.sql"。
根据这个路径,我们去Activiti源码里查看,可以看到在org/activiti/db/路径底下,总共有5个文件目录。根据其名字,可以猜测出,create目录下存放的,是生成表的sql语句;drop目录下,存放的是删除表是sql语句;mapping目录下,是mybatis映射xml文件;properties是各类数据库类型在分页情况下的特殊处理;upgrade目录下,则是更新数据库表的sql语句。
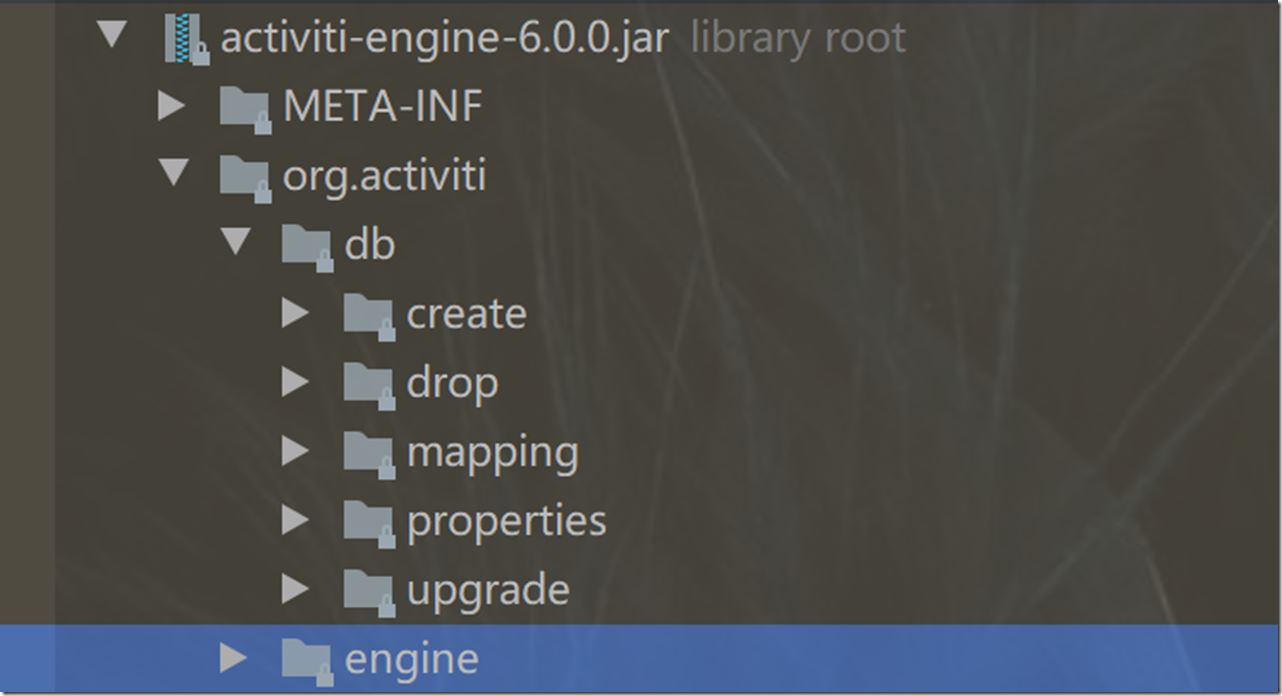
展开其中的create目录,可以进一步发现,里面根据名字区分了不同数据库类型对应的执行sql文件,其中,有db2、h2、hsql、mssql、mysql、mysql55、oracle、postgres这八种类型,反过来看,同时说明了Activiti工作流引擎支持使用这八种数据库。通常使用比较多的是mysql。根据刚刚的路径org/activiti/db/create/activiti.mysql.create.engine.sql,可以在下面截图中,找到该对应路径下的engine.sql文件——
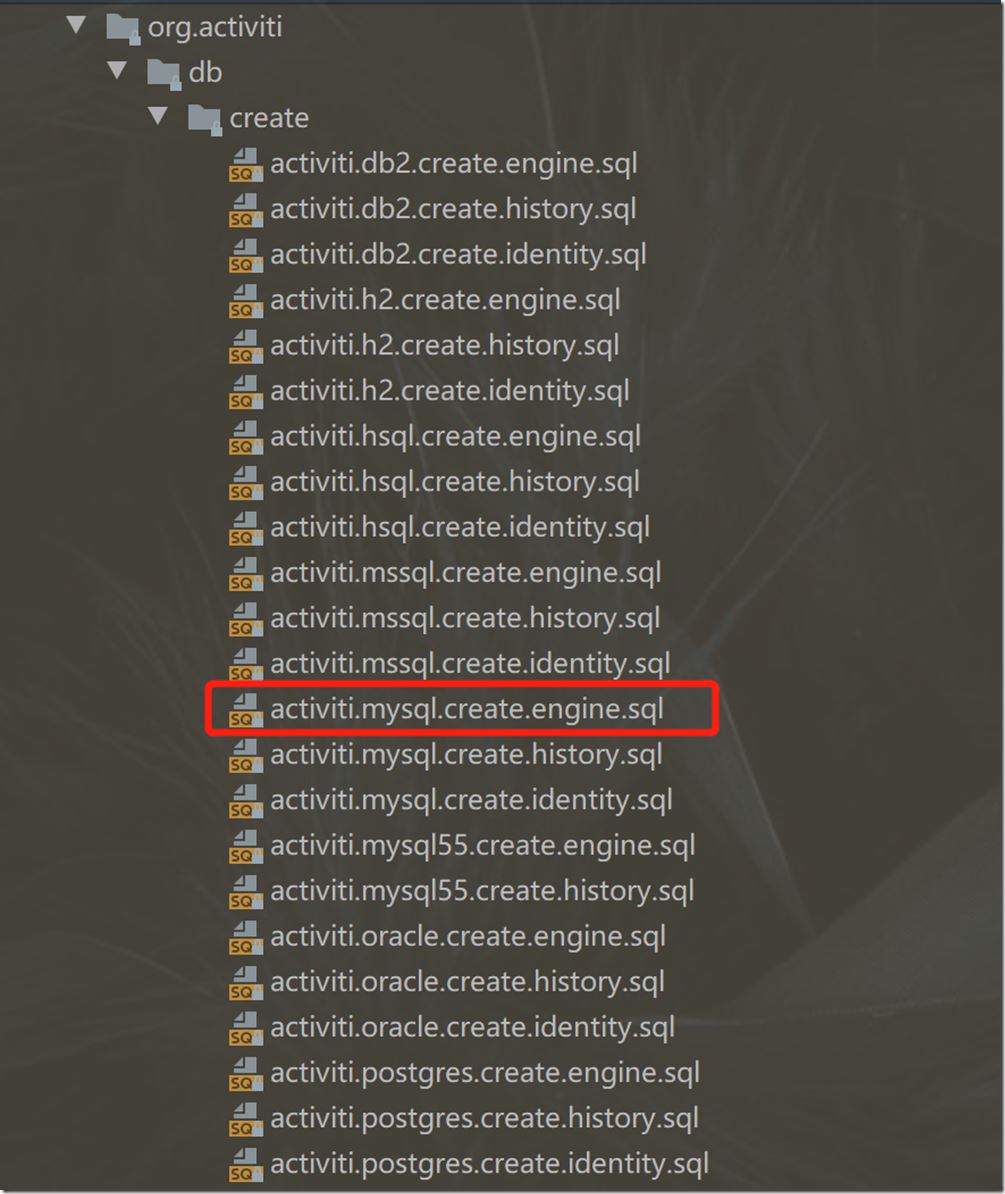
点击进去看,会发现,这不就是我们常见的mysql建表语句吗!没错,工作流Activiti就是在源码里内置了一套sql文件,若要创建数据库表,就直接去到对应数据库文件目录下,获取到相应的建表文件,执行sql语句建表。这跟平常用sql语句构建表结构没太大区别,区别只在于执行过程的方式而已,但两者结果都是一样的。
到这里,我们根据其拼接的sql存放路径,找到了create表结构的sql文件,那么让我们回到原来代码执行的方法里:
public void executeMandatorySchemaResource(String operation, String component) {
this.executeSchemaResource(operation, component, this.getResourceForDbOperation(operation, operation, component), false);
}
这里通过this.getResourceForDbOperation(operation, operation, component), false)拿到 了mysql文件路径,接下来,将同其他几个参数,一块传入到this.executeSchemaResource()方法里,具体如下:
public void executeSchemaResource(String operation, String component, String resourceName, boolean isOptional) {
InputStream inputStream = null;
try {
//根据resourceName路径字符串,获取到对应engine.sql文件的输入流inputStream,即读取engine.sql文件
inputStream = ReflectUtil.getResourceAsStream(resourceName);
if (inputStream == null) {
......
} else {
//将得到的输入流inputStream传入该方法
this.executeSchemaResource(operation, component, resourceName, inputStream);
}
} finally {
......
}
}
这一步主要通过输入流InputStream读取engine.sql文件的字节,然后再传入到 this.executeSchemaResource(operation, component, resourceName, inputStream)方法当中,而这个方法,将是Activiti建表过程中的核心所在。
下面删除多余代码,只留核心代码来分析:
private void executeSchemaResource(String operation, String component, String resourceName, InputStream inputStream) {
//sql语句字符串
String sqlStatement = null;
try {
//1、jdbc连接mysql数据库
Connection connection = this.sqlSession.getConnection();
//2、分行读取resourceName="org/activiti/db/create/activiti.mysql.create.engine.sql"目录底下的文件数据
byte[] bytes = IoUtil.readInputStream(inputStream, resourceName);
//3.将engine.sql文件里的数据分行转换成字符串,换行的地方,可以看到字符串用转义符“\n”来代替
String ddlStatements = new String(bytes);
try {
if (this.isMysql()) {
DatabaseMetaData databaseMetaData = connection.getMetaData();
int majorVersion = databaseMetaData.getDatabaseMajorVersion();
int minorVersion = databaseMetaData.getDatabaseMinorVersion();
if (majorVersion <= 5 && minorVersion < 6) {
//若数据库类型是在mysql 5.6版本以下,需要做一些替换,因为低于5.6版本的MySQL是不支持变体时间戳或毫秒级的日期,故而需要在这里对sql语句的字符串做替换。(注意,这里的majorVersion代表主版本,minorVersion代表主版本下的小版本)
ddlStatements = this.updateDdlForMySqlVersionLowerThan56(ddlStatements);
}
}
} catch (Exception var26) {
......
}
//4.以字符流形式读取字符串数据
BufferedReader reader = new BufferedReader(new StringReader(ddlStatements));
//5.根据字符串中的转义符“\n”分行读取
String line = this.readNextTrimmedLine(reader);
//6.循环每一行
for(boolean inOraclePlsqlBlock = false; line != null; line = this.readNextTrimmedLine(reader)) {
if (line.startsWith("# ")) {
......
}
//7.若下一行line还有数据,证明还没有全部读取,仍可执行读取
else if (line.length() > 0) {
if (this.isOracle() && line.startsWith("begin")) {
.......
}
/**
8.在没有拼接够一个完整建表语句时,!line.endsWith(";")会为true,即一直循环进行拼接,当遇到";"就跳出该if语句
**/
else if ((!line.endsWith(";") || inOraclePlsqlBlock) && (!line.startsWith("/") || !inOraclePlsqlBlock)) {
sqlStatement = this.addSqlStatementPiece(sqlStatement, line);
} else {
/**
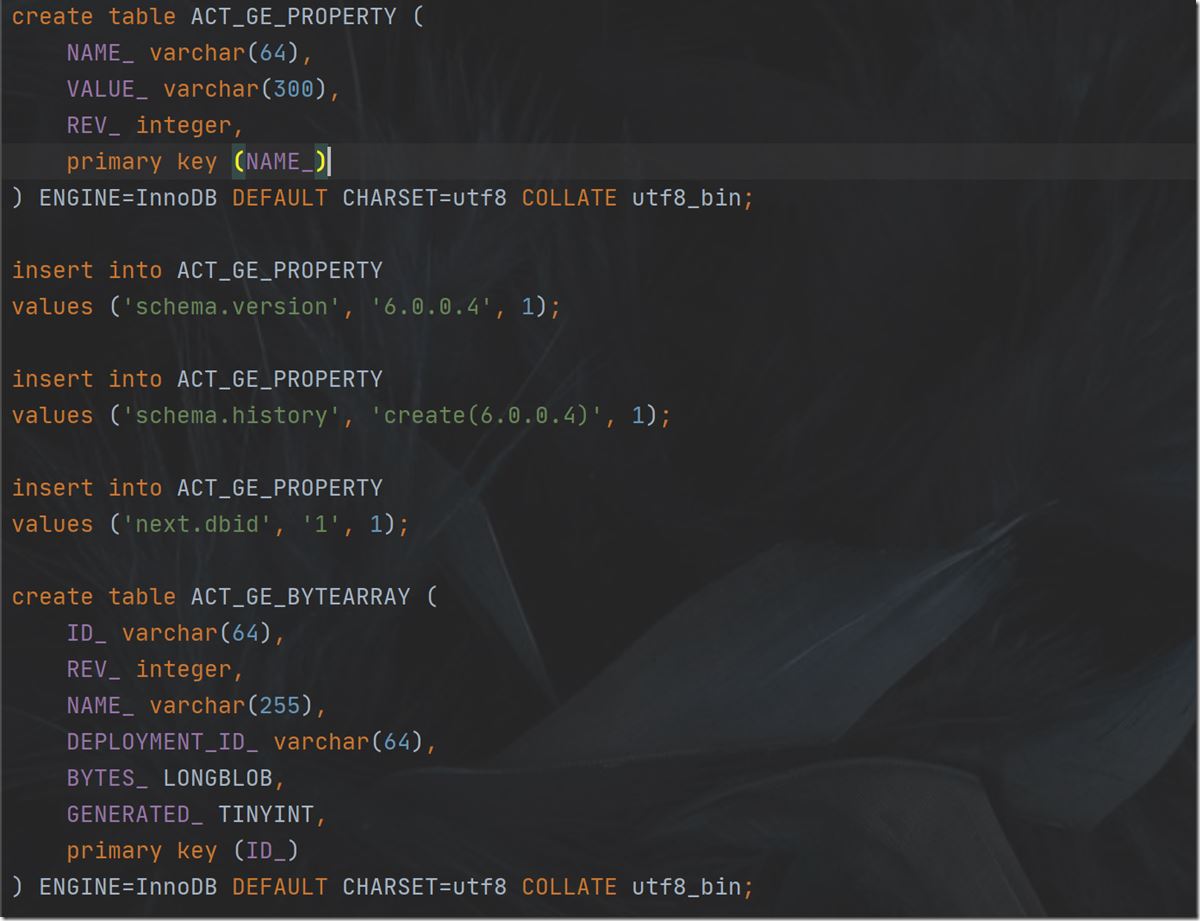
9.循环拼接中若遇到符号";",就意味着,已经拼接形成一个完整的sql建表语句,例如
create table ACT_GE_PROPERTY (
NAME_ varchar(64),
VALUE_ varchar(300),
REV_ integer,
primary key (NAME_)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE utf8_bin
这样,就可以先通过代码来将该建表语句执行到数据库中,实现如下:
**/
if (inOraclePlsqlBlock) {
inOraclePlsqlBlock = false;
} else {
sqlStatement = this.addSqlStatementPiece(sqlStatement, line.substring(0, line.length() - 1));
}
//10.将建表语句字符串包装成Statement对象
Statement jdbcStatement = connection.createStatement();
try {
//11.最后,执行建表语句到数据库中
jdbcStatement.execute(sqlStatement);
jdbcStatement.close();
} catch (Exception var27) {
......
} finally {
//12.到这一步,意味着上一条sql建表语句已经执行结束,若没有出现错误话,这时已经证明第一个数据库表结构已经创建完成,可以开始拼接下一条建表语句,
sqlStatement = null;
}
}
}
}
......
} catch (Exception var29) {
......
}
}
以上步骤可以归纳下:
- jdbc连接mysql数据库;
- 分行读取resourceName="org/activiti/db/create/activiti.mysql.create.engine.sql"目录底下的sql文件数据;
- 将整个engine.sql文件数据分行转换成字符串ddlStatements,有换行的地方,用转义符“\n”来代替;
- 以BufferedReader字符流形式读取字符串ddlStatements数据;
- 循环字符流里的每一行,拼接成sqlStatement字符串,若读取到该行结尾有“;”符号,意味着已经拼接成一个完整的create建表语句,这时,跳出该次拼接,直接包装成成Statement对象;值得注意一点是,Statement 是 Java 执行数据库操作的一个重要接口,用于在已经建立数据库连接的基础上,向数据库发送要执行的SQL语句。Statement对象是用于执行不带参数的简单SQL语句,例如本次的create建表语句。
- 最后,执行jdbcStatement.execute(sqlStatement),将create建表语句执行进数据库中;
- 生成对应的数据库表;
根据debug过程截图,可以更为直观地看到,这里获取到的ddlStatements字符串,涵盖了sql文件里的所有sql语句,同时,每一个完整的creat建表语句,都是以";"结尾的:
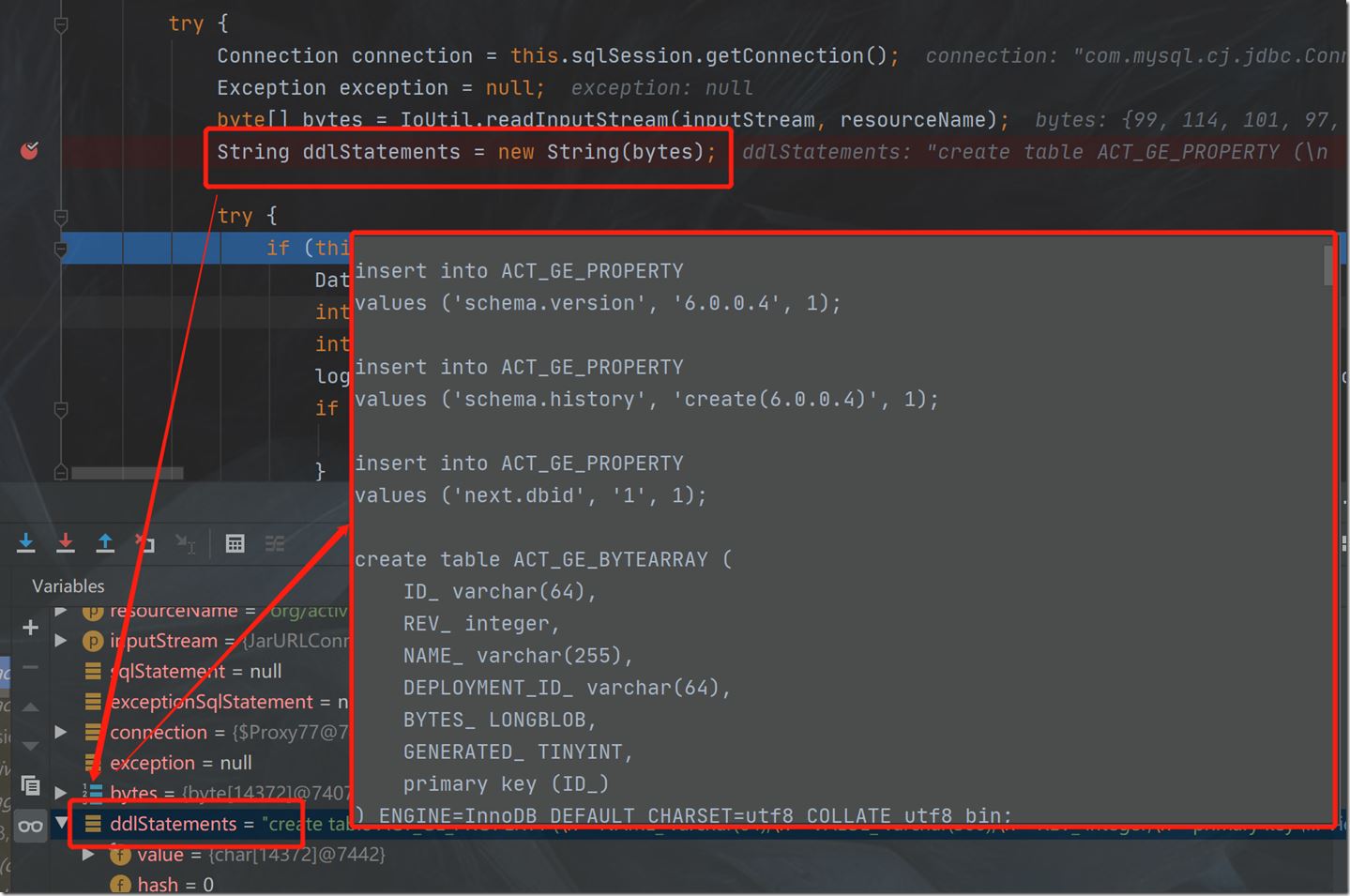
每次执行到";"时,都会得到一个完整的create建表语句:
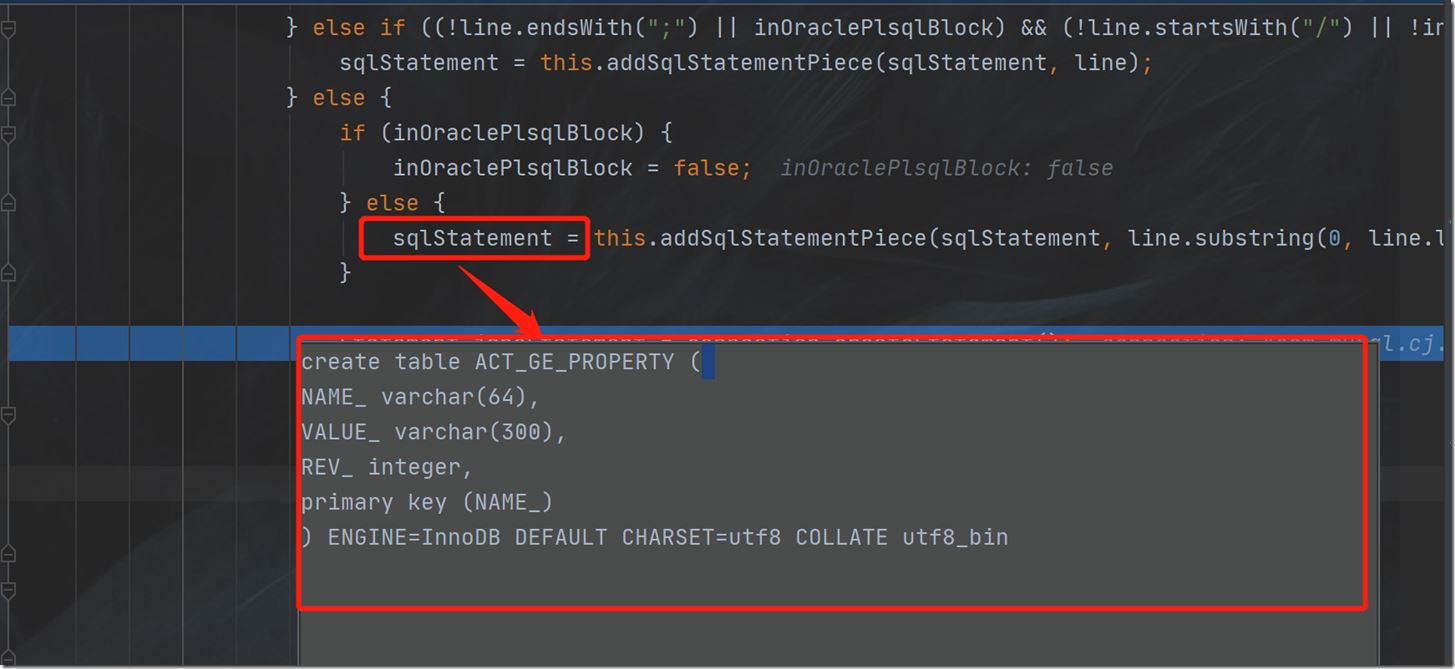
执行完一个建表语句,就会在数据库里同步生成一张数据库表,如上图执行的是ACT_GE_PROPERTY表,数据库里便生成了这张表:

在执行完之后,看idea控制台打印信息,可以看到,我的数据库是5.7版本,引擎在启动过程中分别执行了engine.sql、history.sql、identity.sql三个sql文件来进行数据库表结构的构建。

到这一步,引擎整个生成表的过程就结束了,以上主要是基于true策略模式,通过对engine.sql的执行,来说明工作流引擎生成表的底层逻辑,其余模式基本都类似,这里就不一一展开分析了。
最后,进入到数据库,可以看到,已成功生成28张ACT开头的工作流自带表——
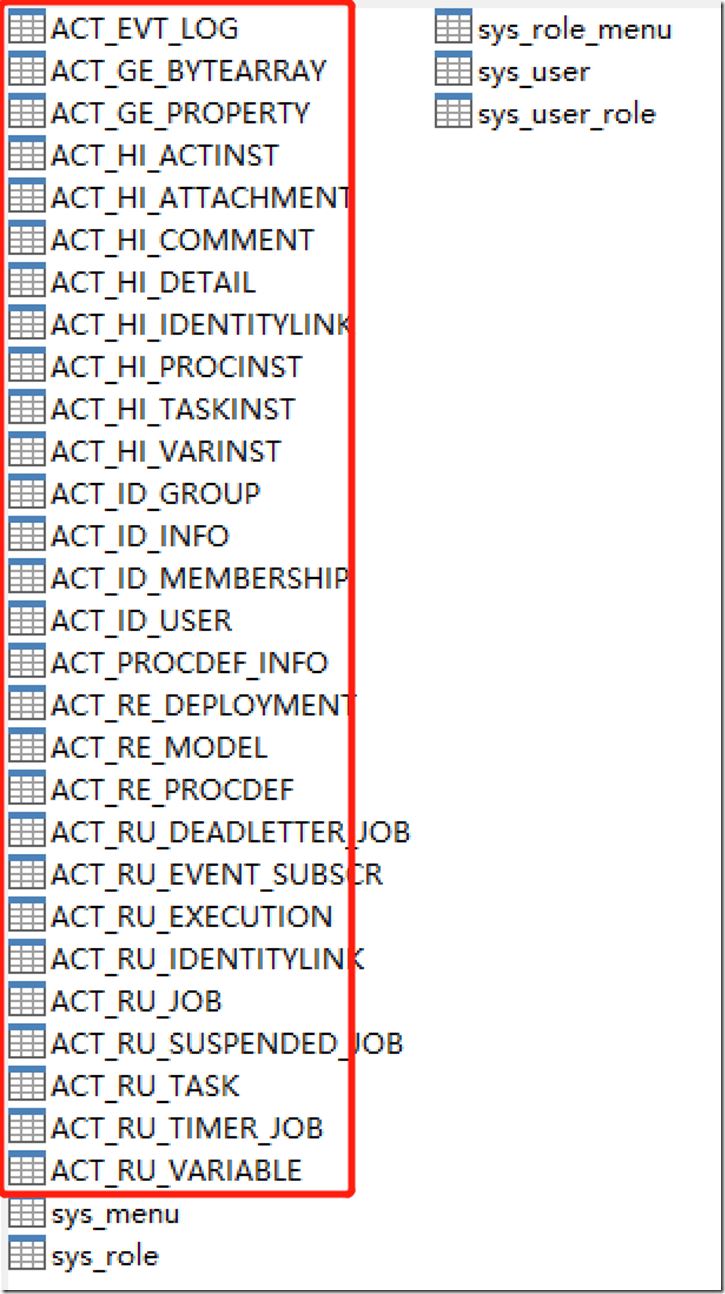
jdbc连接mysql数据库
到此这篇关于Activiti工作流学习笔记之自动生成28张数据库表的底层原理解析的文章就介绍到这了,更多相关Activiti工作流自动生成28张数据库表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于在IDEA中SpringBoot项目中activiti工作流的使用详解
记录一下工作流的在Springboot中的使用,,顺便写个demo,概念,什么东西的我就不解释了,如有问题欢迎各位大佬指导一下. 1.创建springboot项目后导入依赖 <dependency> <groupId>org.activiti</groupId> <artifactId>activiti-spring-boot-starter-basic</artifactId> <version>6.0.0</version&
-

Activiti-Explorer使用sql server数据库实现方法
如何让Activiti-Explorer使用sql server数据库 从官网下载的Activiti-explorer的war文件内部默认是使用h2内存数据库的,如果想改用其他的数据库来做持久化,比如sql server,需要做如下配置. 1)修改db.properties文件 路径:C:\apache-tomcat-7.0.64\webapps\activiti-explorer\WEB-INF\classes\db.properties 内容如下: db=mssql jdbc.driver=
-
spring boot activiti工作流的搭建与简单使用
前言 最近一直研究springboot,根据工作需求,工作流需要作为一个单独的微服务工程来提供给其他服务调用,现在简单的写下工作流(使用的activiti)微服务的搭建与简单使用 jdk:1.8 数据库:mysql 5.7 IDE:eclipse springboot:1.5.8 activiti:6.0.0 1.新建空白的maven微服务架构 新建maven项目的流程不在阐述,这里添加上activiti.myslq连接的依赖,只贴主要代码 pox.xml <project xmlns="
-
Activiti工作流学习笔记之自动生成28张数据库表的底层原理解析
网上关于工作流引擎Activiti生成表的机制大多仅限于四种策略模式,但其底层是如何实现的,相关文章还是比较少,因此,觉得撸一撸其生成表机制的底层原理. 我接触工作流引擎Activiti已有两年之久,但一直都只限于熟悉其各类API的使用,对底层的实现,则存在较大的盲区. Activiti这个开源框架在设计上,其实存在不少值得学习和思考的地方,例如,框架用到以命令模式.责任链模式.模板模式等优秀的设计模式来进行框架的设计. 故而,是值得好好研究下Activiti这个框架的底层实现. 我在工作当中现
-
MySQL学习笔记之创建、删除、修改表的方法
本文实例讲述了MySQL学习笔记之创建.删除.修改表的方法.分享给大家供大家参考,具体如下: 创建表: create table users( id int, name varchar(64), sex bit(1), birthday date, Entry_date date, job varchar(32), salary float, resume text ); 1 添加列: alter table 表名 add 列名 数据类型 alter table users add image
-
Laravel自动生成UUID,从建表到使用详解
gitHub地址: https://github.com/EmadAdly/laravel-uuid.git 1.安装依赖 composer require emadadly/laravel-uuid 2.然后在config/app.php的providers里添加ServiceProvider 'providers' => [ ... Emadadly\LaravelUuid\LaravelUuidServiceProvider::class, ], 3.然后根目录执行 php artisan
-
PHP面向对象学习笔记之二 生成对象的设计模式
一. 单例模式(Singleton) 如果应用程序每次包含且仅包含一个对象,那么这个对象就是一单例. 用来替代全局变量. 复制代码 代码如下: <?php require_once("DB.php"); class DatabaseConnection{ <STRONG><SPAN style="COLOR: #ff0000">public static function get()</SPAN></STRONG>
-
Ruby学习笔记二帮助生成Vim添加代码头的代码
脚本语言真是太强了. 我的目的是把我的默认代码头功能加到Vim里面. /****************************************************************************** * COPYRIGHT NOTICE * Copyright (c) 2014 All rights reserved * ----Stay Hungry Stay Foolish---- * * @author : Shen * @name : * @file : G
-
从Oracle数据库中读取数据自动生成INSERT语句的方法
Oracle INSERT 语句 方法1 我估计有点 SQL 基础的人都会写 INSERT 语句.下面是 SQL 标准写法. INSERT INTO employees (employee_id, name) VALUES (1, 'Zhangsan'); INSERT INTO employees VALUES (1, 'Shangbo'); 方法2 其实, Oracle 还支持下面的写法,作用和上面的语句完全相同. INSERT INTO (SELECT employee_id, name
-
springboot+mybatis通过实体类自动生成数据库表的方法
前言 本章介绍使用mybatis结合mysql数据库自动根据实体类生成相关的数据库表. 首先引入相关的pom包我这里使用的是springboot2.1.8.RELEASE的版本 <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.0</ve
-
MVC使用T4模板生成其他类的具体实现学习笔记2
在前篇中我们已经将User类中的代码做了具体的实现,但仍然有多个实体类未实现,以后可能还会增加新的数据表,数据表结构也有可能发生变化,所以我们使用T4模板来完成类的生成,这样就算数据库表发生了改变,也会自动根据改变后的实体对类进行重新生成. 下面是数据访问层的T4模板文件 Dal.tt <#@ template language="C#" debug="false" hostspecific="true"#> <#@ inclu
-
Laravel学习笔记之Artisan命令生成自定义模板的方法
说明:本文主要讲述Laravel的Artisan命令来实现自定义模板,就如经常输入的php artisan make:controller ShopController就会自动生成一个ShopController.php模板文件一样,通过命令生成模板也会提高开发效率.同时,作者会将开发过程中的一些截图和代码黏上去,提高阅读效率. 备注:个人平时在写Repository代码时会这样写,如先写上ShopRepositoryInterface并定义好接口方法如all().create().update
-
tensorflow学习笔记之tfrecord文件的生成与读取
训练模型时,我们并不是直接将图像送入模型,而是先将图像转换为tfrecord文件,再将tfrecord文件送入模型.为进一步理解tfrecord文件,本例先将6幅图像及其标签转换为tfrecord文件,然后读取tfrecord文件,重现6幅图像及其标签. 1.生成tfrecord文件 import os import numpy as np import tensorflow as tf from PIL import Image filenames = [ 'images/cat/1.jpg'