R语言 用均值替换、回归插补及多重插补进行插补的操作
用均值替换、回归插补及多重插补进行插补
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("E:\\R_workspace\\R语言数据分析与挖掘实战\\chp4")
# 读取销售数据文件,提取标题行
inputfile <- read.csv('./data/catering_sale.csv', header = TRUE)
View(inputfile)
# 变换变量名
inputfile <- data.frame(sales = inputfile$'销量', date = inputfile$'日期')
View(inputfile)
# 数据截取
inputfile <- inputfile[5:16, ]
View(inputfile)
# 缺失数据的识别
is.na(inputfile) # 判断是否存在缺失
n <- sum(is.na(inputfile)) # 输出缺失值个数
n
# 异常值识别
par(mfrow = c(1, 2)) # 将绘图窗口划为1行两列,同时显示两图
dotchart(inputfile$sales) # 绘制单变量散点图
boxplot(inputfile$sales, horizontal = TRUE) # 绘制水平箱形图
# 异常数据处理
inputfile$sales[5] = NA # 将异常值处理成缺失值
fix(inputfile) # 表格形式呈现数据
# 缺失值的处理
inputfile$date <- as.numeric(inputfile$date) # 将日期转换成数值型变量
sub <- which(is.na(inputfile$sales)) # 识别缺失值所在行数
sub
# 将数据集分成完整数据和缺失数据两部分
inputfile1 <- inputfile[-sub, ]
inputfile2 <- inputfile[sub, ]
# 行删除法处理缺失,结果转存
result1 <- inputfile1
View(result1)
# 均值替换法处理缺失,结果转存
avg_sales <- mean(inputfile1$sales) # 求变量未缺失部分的均值
avg_sales
# 用均值替换缺失
inputfile2$sales <- rep(avg_sales,n)
# 并入完成插补的数据
result2 <- rbind(inputfile1, inputfile2)
View(result2)
# 回归插补法处理缺失,结果转存
# 回归模型拟合
# 注意:因变量~自变量
model <- lm(sales ~ date, data = inputfile1)
# 模型预测
inputfile2$sales <- predict(model, inputfile2)
result3 <- rbind(inputfile1, inputfile2)
# 多重插补法处理缺失,结果转存
library(lattice) # 调入函数包
library(MASS)
library(nnet)
library(mice) # 前三个包是mice的基础
# 4重插补,即生成4个无缺失数据集
imp <- mice(inputfile, m = 4)
# 选择插补模型
# inputfile为原始数据,有缺失
fit <- with(imp,lm(sales ~ date, data = inputfile))
# m重复完整数据分析结果池
pooled <- pool(fit)
summary(pooled)
result4 <- complete(imp, action = 3) # 选择第三个插补数据集作为结果
补充:R语言数据缺失值处理(随机森林,多重插补)
缺失值是指数据由于种种因素导致的数据不完整,可以分为机械原因和人为原因。对于缺失值我们通常采用以下几种方法来进行插补。
1.读取数据
通过read.csv函数导入文档,也可以用其他函数读入,如openxlsx::read.xlsx,read.table等。
head()查看数据前几行。
airquality <- read.csv(data.csv) head(airquality)

2.检查数据完整性
首先,summary()查看数据基本信息
summary(airairquality)

可以看到Ozone中存在缺失值NA
通过调用VIM::aggr()查看函数的缺失值(如果包安装较慢,可选用本地安装,链接已附需自行下载)
#install.packages(‘VIM') library(VIM) aggr(airquality)
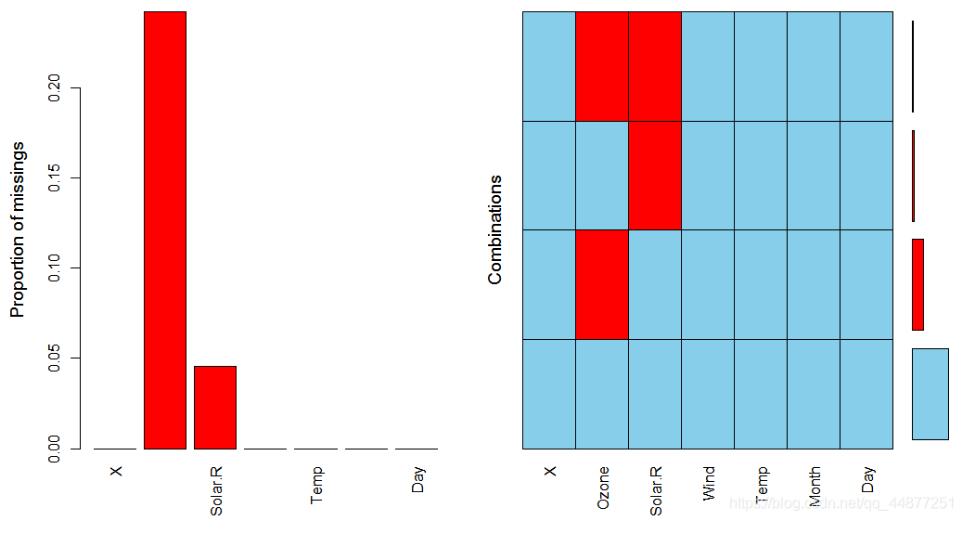
通过上图,可以看到Ozone和Solar.R存在缺失值。
3.缺失值填补
3.1简单处理填补
(1)删除缺失值
若样本中存在较少缺失值或缺失值比例较小不影响分析结果时,可选择直接将缺失值删除。
dat1 <- na.omit(airquality)
(2)平均值、中位数填补
若不能直接将缺失值删除也可选择平均值、众数、中位数等进行填补
#平均值填补
airquality$ Ozone[is.na(airquality$Ozone)] <- mean(airquality $ Ozone,na.rm=T)
#中位数填补
airquality$ Solar.R[is.na(airquality$ Solar.R)] <- median(airquality$ Solar.R,na.rm = T)
#计算缺失值个数,等于0 则不存在缺失值
sum(is.na(airquality))
#相邻均值填补
airquality <- read.csv(data.csv) #重新读入数据
for (i in 1:length(airquality$ Ozone)) {
airquality$ Ozone[i] <- ifelse(is.na(airquality$ Ozone[i]),
mean(c(airquality$ Ozone[i-1],airquality$ Ozone[i+1]),na.rm=T),
airquality$ Ozone[i])
}
3.2复杂处理填补
(1)K-近邻算法填补
基本思想:对于需要填补的观测值,先利用欧氏距离找到其邻近的K个观测,再将这K个邻近的值进行加权平均进行填补。
原始数据中存在多个缺失值,可以利用DMwR包中的knnImputation()函数进行填补
dat1 <- knnImputation(airquality[,c(1:4)],meth = ‘weighAvg',scale = T)
提取原始数据中的前4列进行填补,meth = 'weighAvg'指使用加权平均的方法进行填补,scale = T指在选取邻近值时,先对数据进行标准化。
aggr(dat1) #查看缺失值分布
(2)随机森林填补缺失值
接下来介绍一个新的填补方法–随机森林填补,随机森林是机器学习中一种常见的方法,以决策树为基分类的器的集成学习模型。
missForest包中missForest()函数可实现随机森林填补,ntree代表模型中的树的棵数,一般情况下,对于高维数据可选择较小的值(如100),以达到快速插补的效果;对于大数据集进行填补时,可能耗时比较多。
library(missForest) dat2 <- missForest(airquality,ntree = 100)
dat2中包含填补好的数据,可利用dat2$ximp查看填补后的值,
head(dat2$ximp) aggr(dat2$ximp)
同时,OOBerror表示袋外填补缺失的误差估计。
dat2$OOBerror

4.多重插补法
多重插补法是在一个缺失的数据集中生成一个完整的数据集,并利用蒙特卡洛的方法进行填补的一种重复模拟的方法。
包mice中的mice()函数可实现对缺失数据的多重插补,原数据集中Ozone和Solar.R变量存在缺失,采用‘rf'法插补。
dat3 <- mice(airquality,m=5,method = ‘rf')
其中,m为生成完整数据集的个数,默认为5. method为插补参数的方法,‘norm.predict'、‘pmm'、‘rf'、‘norm'依次为回归预测法、平均值插补法、随机森林法和高斯线性回归法。
summary(dat3)

通过以下代码可查看填补的值
dat3$ imp$Solar.R

最后选择某一列(如1,2,3)填充到缺失数据集中即可形成完整的数据集.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言绘制空间热力图实例讲解
先上图 R语言的REmap包拥有非常强大的空间热力图以及空间迁移图功能,里面内置了国内外诸多城市坐标数据,使用起来方便快捷. 开始首先安装相关包 install_packages("devtools") install_packages("REmap") library(devtools) library(REmap) 我们来试试其强大的城市坐标获取功能 city<- c("beijing","上海") get_geo_
-
R语言归一化处理实例讲解
归一化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内.首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快. R语言中的归一化函数:scale 数据归一化包括数据的中心化和数据的标准化. 1. 数据的中心化 所谓数据的中心化是指数据集中的各项数据减去数据集的均值. 例如有数据集1, 2, 3, 6, 3,其均值为3,那么中心化之后的数据集为1-3,2-3,3-3,6-3,3-3,即:-2,-1,0,3,0 2. 数据的标准化 所谓数据的标准化是指中心化之后
-
linux命令行下使用R语言绘图实例讲解
使用系统:centos 6.4 64bit 在R语言中可以使用png()等函数生成图片,例如: png("aa.png")可以生成图片. 但是如果你是通过shell远程连接到系统上,可能会碰到如下错误: > png("aa.png") 错误于.External2(C_X11, paste("png::", filename, sep = ""), g$width, : 无法打开PNG设备 此外: 警告信息: In
-
R语言实现对数据框按某一列分组求组内平均值
可使用aggregate函数 如: aggregate(.~ID,data=这个数据框名字,mean) 如果是对数据框分组,组内有重复的项,对于重复项保留最后一行数据用: pcm_df$duplicated <- duplicated(paste(pcm_df$OUT_MAT_NO, pcm_df$Posit, sep = "_"), fromLast = TRUE) pcm_df <- subset(pcm_df, !duplicated) pcm_df$duplicat
-
R语言基本语法深入讲解
基本数据类型 数据类型 向量 vector 矩阵 matrix 数组 array 数据框 data frame 因子 factor 列表 list 向量 单个数值(标量)没有单独的数据类型,它只不过是向量的一种特例 向量的元素必须属于某种模式(mode),可以整型(integer).数值型(numeric).字符型(character).逻辑型(logical).复数型(complex) 循环补齐(recycle):在一定情况下自动延长向量 筛选:提取向量子集 向量化:对向量的每一个元素应用函数
-
R语言写2048游戏实例讲解
2048 是一款益智游戏,只需要用方向键让两两相同的数字碰撞就会诞生一个翻倍的数字,初始数字由 2 或者 4 构成,直到游戏界面全部被填满,游戏结束. 编程时并未查看原作者代码,不喜勿喷. 程序结构如下: R语言代码: #!/usr/bin/Rscript #画背景 draw_bg <- function(){ plot(0,0,xlim=c(0,0.8),ylim=c(0,0.8),type='n',xaxs="i", yaxs="i") for (i in
-
R语言的xtabs函数实例讲解
今天在做一个列联表独立性检验的时候,总是无法处理好要求的数据类型,偶然的机会,看到了xtabs()函数,感觉很适合用来做列联表,适合将一列数据转换成列联表. shifou <- c("yes","yes","no","no") xinbie <- c("nan","nv","nan","nv") freq <- c(34,38,2
-
R语言 用均值替换、回归插补及多重插补进行插补的操作
用均值替换.回归插补及多重插补进行插补 # 设置工作空间 # 把"数据及程序"文件夹拷贝到F盘下,再用setwd设置工作空间 setwd("E:\\R_workspace\\R语言数据分析与挖掘实战\\chp4") # 读取销售数据文件,提取标题行 inputfile <- read.csv('./data/catering_sale.csv', header = TRUE) View(inputfile) # 变换变量名 inputfile <- da
-
R语言多元Logistic逻辑回归应用实例
可以使用逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 如何进行多元逻辑回归 可以使用阶梯函数通过逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 通常建议不要盲目地遵循逐步程序,而是要使用拟合统计(AIC,AICc,BIC)比较模型,或者根据生物学或科学上合理的可用变量建立模型. 多元相关是研究潜在自变量之间关系的一种工具.例如,如果两个独立变量彼此相关,可能在最终模型中都不需要这两个变量,但可能有理由选择一个变量而不是另一个变量. 多元相关 创建数值变量的数据框 Data.
-
R语言中平均值、中位数和模式知识点总结
R中的统计分析通过使用许多内置函数来执行. 这些函数大多数是R基础包的一部分. 这些函数将R向量作为输入和参数,并给出结果. 我们在本章中讨论的功能是平均值,中位数和模式. Mean平均值 通过求出数据集的和再除以求和数的总量得到平均值 函数mean()用于在R语言中计算平均值. 语法 用于计算R中的平均值的基本语法是 mean(x, trim = 0, na.rm = FALSE, ...) 以下是所使用的参数的描述 x是输入向量. trim用于从排序向量的两端丢弃一些观察结果. na.rm用
-
R语言glmnet包lasso回归中分类变量的处理图文详解
我们在既往文章<手把手教你使用R语言做LASSO 回归>中介绍了glmnet包进行lasso回归,后台不少粉丝发信息向我问到分类变量处理的问题,我后面查了一下资料之前文章分类变量没有处理,非常抱歉.现在来重新聊一聊分类变量的处理. 我们导入glmnet包的时候可以看到,还需要导入一个Matrix包,说明这个矩阵包很重要 按照glmnet包的原文如下: 就是告诉我们,除了Cox Model外,其他的表达都支持矩阵形式,在Cox Model的介绍中,函数样式为 说明我们应该把其他变量变为矩阵的形式
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
R语言 数据表匹配和拼接 merge函数的使用
R中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能. merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...) x,y:用于合并的两个
-
R语言逻辑回归、ROC曲线与十折交叉验证详解
自己整理编写的逻辑回归模板,作为学习笔记记录分享.数据集用的是14个自变量Xi,一个因变量Y的australian数据集. 1. 测试集和训练集3.7分组 australian <- read.csv("australian.csv",as.is = T,sep=",",header=TRUE) #读取行数 N = length(australian$Y) #ind=1的是0.7概率出现的行,ind=2是0.3概率出现的行 ind=sample(2,N,rep
-
详解R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计
MCMC是从复杂概率模型中采样的通用技术. 蒙特卡洛 马尔可夫链 Metropolis-Hastings算法 问题 如果需要计算有复杂后验pdf p(θ| y)的随机变量θ的函数f(θ)的平均值或期望值. 您可能需要计算后验概率分布p(θ)的最大值. 解决期望值的一种方法是从p(θ)绘制N个随机样本,当N足够大时,我们可以通过以下公式逼近期望值或最大值 将相同的策略应用于通过从p(θ| y)采样并取样本集中的最大值来找到argmaxp(θ| y). 解决方法 1.1直接模拟 1.2逆CDF 1.
-
R语言gsub替换字符工具的具体使用
gsub()可以用于字段的删减.增补.替换和切割,可以处理一个字段也可以处理由字段组成的向量. 具体的使用方法为:gsub("目标字符", "替换字符", 对象) 在gsub函数中,任何字段处理都由将"替换字符"替换到"目标字符"这一流程中实现,令替换字符为''''可实现删除,令替换字符为"目标字符+增补内容"可实现增补,替换和切割也是使用类似的操作. > text <- "AbcdE
-
R语言实现LASSO回归的方法
Lasso回归又称为套索回归,是Robert Tibshirani于1996年提出的一种新的变量选择技术.Lasso是一种收缩估计方法,其基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,进一步得到可以解释的模型.R语言中有多个包可以实现Lasso回归,这里使用lars包实现. 1.利用lars函数实现lasso回归并可视化显示 x = as.matrix(data5[, 2:7]) #data5为自己的数据集 y = as.ma