python爬虫用scrapy获取影片的实例分析
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。
1. 创建项目
运行命令:
scrapy startproject myfrist(your_project_name)
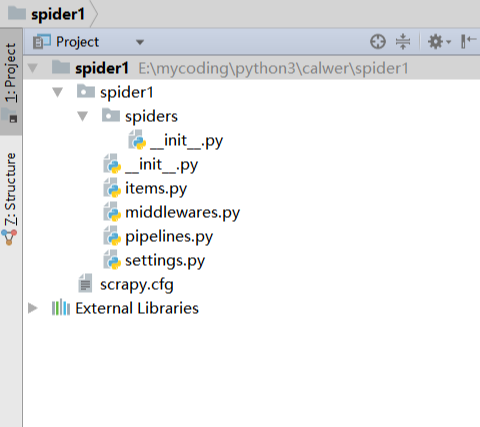
文件说明: 名称 | 作用 --|-- scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) items.py | 设置数据存储模板,用于结构化数据,如:Django的Model pipelines | 数据处理行为,如:一般结构化的数据持久化 settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 spiders | 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2 编写 spdier
在spiders目录中新建 daidu_spider.py 文件
2.1 注意
爬虫文件需要定义一个类,并继承scrapy.spiders.Spider
必须定义name,即爬虫名,如果没有name,会报错。因为源码中是这样定义的
2.2 编写内容
在这里可以告诉 scrapy 。要如何查找确切数据,这里必须要定义一些属性
name: 它定义了蜘蛛的唯一名称
allowed_domains: 它包含了蜘蛛抓取的基本URL;
start-urls: 蜘蛛开始爬行的URL列表;
parse(): 这是提取并解析刮下数据的方法;
下面的代码演示了蜘蛛代码的样子:
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allwed_url = 'douban.com'
start_urls = [
'https://movie.douban.com/top250/'
]
def parse(self, response):
movie_name = response.xpath("//div[@class='item']//a/span[1]/text()").extract()
movie_core = response.xpath("//div[@class='star']/span[2]/text()").extract()
yield {
'movie_name':movie_name,
'movie_core':movie_core
}
到此这篇关于python爬虫用scrapy获取影片的实例分析的文章就介绍到这了,更多相关python爬虫如何用scrapy获取影片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中scrapy处理项目数据的实例分析
在我们处理完数据后,习惯把它放在原有的位置,但是这样也会出现一定的隐患.如果因为新数据的加入或者其他种种原因,当我们再次想要启用这个文件的时候,小伙伴们就会开始着急却怎么也翻不出来,似乎也没有其他更好的搜集办法,而重新进行数据整理显然是不现实的.下面我们就一起看看python爬虫中scrapy处理项目数据的方法吧. 1.拉取项目 $ git clone https://github.com/jonbakerfish/TweetScraper.git $ cd TweetScraper/ $ pi
-
python爬虫scrapy图书分类实例讲解
我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍.如果其中的分类不是很细致的话,想找某一本书还是有一些困难的.同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用.所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下: spider抓取程序: 在贴上代码之前,先对抓取的页面和链接做一个分析: 网址:http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html 这个是当
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
scrapy处理python爬虫调度详解
学习了简单的知识点,就会想要向有难度的问题挑战,这里必须要夸一夸小伙伴们.不过我们今天不需要做什么程序的测试,只用简单的两个代码对比,小伙伴们就能在其中体会两者的不同和难易程度.scrapy能否适合处理python爬虫调度的问题,小编直接说出答案小伙伴们也不能马上信服,下面就让我们在示例中找寻答案吧. 总的来说,需要使用代码来爬一些数据的大概分为两类人: 非程序员,需要爬一些数据来做毕业设计.市场调研等等,他们可能连 Python 都不是很熟: 程序员,需要设计大规模.分布式.高稳定性的爬虫系统
-
简述python Scrapy框架
一.Scrapy框架简介 Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛.利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常的方便.它使用Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.Scrapy是Python世界里面最强大的爬虫框架,它比BeautifulSoup更加完善,BeautifulSoup可以说是轮子,而Scrapy则是车子,不
-
scrapy在python爬虫中搭建出错的解决方法
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了.一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题.有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点. 问题描述: 安装位置: 环境变量: 解决办法: 文件命名叫 scrapy.py,明显和scrapy自己的包名冲突了,这里 class StackOverFlowSpider(scrapy.Spider) 会直接找当前文件(scrapy.py
-
python爬虫用scrapy获取影片的实例分析
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情.周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题.那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧. 1. 创建项目 运行命令: scrapy startproject myfrist(your_project_name) 文件说明: 名称 | 作用 --|-- scrapy.cfg | 项目的配置信息
-
Python爬虫框架Scrapy实例代码
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间. 一.创建Scrapy项目 scrapy startproject Tencent 命令执行后,会创建一个Tencent文件夹,结构如下 二.编写item文件,根据需要爬取的内容定义爬取字段 # -*- coding: utf-8 -*- import scrapy class TencentItem(scrapy.Item): # 职位名 positionname = scrapy.
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-

Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令.分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令. 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行 全局命令 全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示: 可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch.runspi
-
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
Python爬虫框架Scrapy基本用法入门教程
本文实例讲述了Python爬虫框架Scrapy基本用法.分享给大家供大家参考,具体如下: Xpath <html> <head> <title>标题</title> </head> <body> <h2>二级标题</h2> <p>爬虫1</p> <p>爬虫2</p> </body> </html> 在上述html代码中,我要获取h2的内容,
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python爬虫框架scrapy实现的文件下载功能示例
本文实例讲述了Python爬虫框架scrapy实现的文件下载功能.分享给大家供大家参考,具体如下: 我们在写普通脚本的时候,从一个网站拿到一个文件的下载url,然后下载,直接将数据写入文件或者保存下来,但是这个需要我们自己一点一点的写出来,而且反复利用率并不高,为了不重复造轮子,scrapy提供很流畅的下载文件方式,只需要随便写写便可用了. mat.py文件 # -*- coding: utf-8 -*- import scrapy from scrapy.linkextractor impor
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验