基于pandas向csv添加新的行和列
首先创建一个csv文件,创建方式为新建一个文本文档,然后将这个文本文档重命名为test.csv
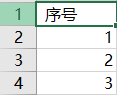
再用Excel打开,添加内容
内容如下:
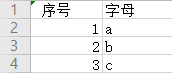
先来添加列
data = ['a','b','c']
df['字母'] = data
import pandas as pd filename = './test.csv' df = pd.read_csv(filename,encoding='gbk') data = ['a','b','c'] df['字母'] = data df.to_csv(filename,index=None)
由于我们的列标签是中文,所以是encoding=‘gbk'
由于我将文件放在了python的工程文件夹内,所以filename='./test.csv',或者也可以换成其绝对路径
再来添加行
df.loc[4]=[4,'d']
import pandas as pd filename = './test.csv' df = pd.read_csv(filename,encoding='gbk') # data = ['a','b','c'] # df['字母'] = data df.loc[4]=[4,'d'] df.to_csv(filename,index=None)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
解决pandas使用read_csv()读取文件遇到的问题
如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.01 2.35 武钢股份 (sh600005) 75.85 1.3 浦发银行 (sh600000) 6.65 0.96 在使用read_csv() API读取CSV文件时求取某一列数据比较大小时, df=pd.read_csv(output_file,encoding='gb23
-
pandas.read_csv参数详解(小结)
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html 参数: filepath_or_buffer : str,pathlib.str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a file
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
利用pandas向一个csv文件追加写入数据的实现示例
我们越来越多的使用pandas进行数据处理,有时需要向一个已经存在的csv文件写入数据,传统的方法之前我也有些过,向txt,excel文件写入数据,传送门:Python将二维列表(list)的数据输出(TXT,Excel) pandas to_csv()只能在新文件写数据?当然不是! pandas to_csv() 是可以向已经存在的具有相同结构的csv文件增加dataframe数据. df.to_csv('my_csv.csv', mode='a', header=False) to_csv(
-
Pandas之read_csv()读取文件跳过报错行的解决
读取文件时遇到和列数不对应的行,此时会报错.若报错行可以忽略,则添加以下参数: 样式: pandas.read_csv(***,error_bad_lines=False) pandas.read_csv(filePath) 方法来读取csv文件时,可能会出现这种错误: ParserError:Error tokenizing data.C error:Expected 2 fields in line 407,saw 3. 是指在csv文件的第407行数据,期待2个字段,但在第407行实际发现
-
python pandas获取csv指定行 列的操作方法
pandas获取csv指定行,列 house_info = pd.read_csv('house_info.csv') 1:取行的操作: house_info.loc[3:6]类似于python的切片操作 2:取列操作: house_info['price'] 这是读取csv文件时默认的第一行索引 3:取两列 house_info[['price',tradetypename']] 取多个列也是同理的,注意里面是一个list的列表,不然会报错误: 4:增加列: house_Info['adre
-
pandas读取csv文件,分隔符参数sep的实例
在python中读取csv文件时,一般操作如下: import pandas as pd pd.read_csv(filename) 该读文件方式,默认是以逗号","作为分割符,若是以其它分隔符,比如制表符"/t",则需要显示的指定分隔符.如下 pd_read_csv(filename,'/t') 但如果遇见某个字段包含了"/t"的字符,比如网址"www.xxx.xx/t-",则也会把字段中的"/t"理解为
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
基于pandas向csv添加新的行和列
首先创建一个csv文件,创建方式为新建一个文本文档,然后将这个文本文档重命名为test.csv 再用Excel打开,添加内容 内容如下: 先来添加列 data = ['a','b','c'] df['字母'] = data import pandas as pd filename = './test.csv' df = pd.read_csv(filename,encoding='gbk') data = ['a','b','c'] df['字母'] = data df.to_csv(filen
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A
-
基于Pandas读取csv文件Error的总结
OSError:报错1 <span style="font-size:14px;">pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas\_libs\parsers.c:4209)() pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas\_libs\
-
Pandas通过index选择并获取行和列
目录 获取pandas.DataFrame的列 列名称:将单个列作为pandas.Series获得 列名称的列表:将单个或多个列作为pandas.DataFrame获得 获取pandas.DataFrame的行 行名・行号的切片:将单行或多行作为pandas.DataFrame获得 获取pandas.Series的值 标签名称:获取每种类型的单个元素的值 标签名称/数字切片:将单个元素或多个元素的值作为pandas.Series获得 获取pandas.DataFrame元素的值 行名/列名是整数
-

如何基于pandas读取csv后合并两个股票
最近在研究螺纹钢与铁矿石的比价变化,所以用python写个代码分析一下. 数据文件: 数据下载自网络. 代码: 中间有些没用的,看官们请忽略,那是我从另一个文件直接复制来的,后面要plt出图的. 今天的文章只讲两个DataFrame如何连接到一起,相当于SQL的left-join ,或者update A left join B ON key1=key2. 控制台输出: 好了, 数据已经按日期关联到一起,后面就简单了,准备用matplotlib画3条拆线,观察历史相关性. 以上就是本文的全部内容,
-
js添加table的行和列 具体实现方法
复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml"><head> <title></titl
-
pandas添加新列的5种常见方法
目录 前言 一.insert()函数 二.直接赋值法 三.reindex()函数 四.concat()函数 五.loc()函数 附:pandas根据现有列新添加一列 总结 前言 pandas为DataFrame格式数据添加新列的方法非常简单,只需要新建一个列索引,再为其赋值即可. 以下总结了5种常见添加新列的方法. 首先,创建一个DataFrame结构数据,作为数据举例. import pandas as pd # 创建一个DataFrame结构数据 data = {'a': ['a0', 'a
-
pandas 选取行和列数据的方法详解
前言 本文介绍在 pandas 中如何读取数据行列的方法.数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field).回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取.比如获取 student_id 和 studnent_name 两个字段:记录筛选,比如 sales_amount 大于 10000 的所有记录.对于熟悉 SQL 语句的人来说,就是下面的语句: select student_id, student_name
-
Android开发中数据库升级且表添加新列的方法
本文实例讲述了Android开发中数据库升级且表添加新列的方法.分享给大家供大家参考,具体如下: 今天突然想到我们android版本升级的时候经常会遇到升级版本的时候在新版本中数据库可能会修改,今天我们就以数据库升级且表添加新列为例子写一个测试程序. 首先在要创建一个数据库,一般我们先创建一个DbHelper,继承SQLiteOpenHelper,构造函数我们使用传递版本号的: public DbHelper(Context context, String name, int version){
-
pandas选择或添加列生成新的DataFrame操作示例
目录 如何向 pandas.DataFrame 添加新的列或行 选择某些列 选择某些列和行 添加新的列 更改某一列的值 补全缺失值 如何向 pandas.DataFrame 添加新的列或行 通过指定新的列名/行名来添加,或者用pandas.DataFrame的assign().insert().append()方法添加等方法. 这里,将描述以下内容. 将列添加到 pandas.DataFrame 通过指定新列名添加 用assign()方法添加/分配 用insert()方法添加到任意位置 使用 c