详解Python中的进程和线程
进程是什么?
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
线程是什么?
线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。线程的引入减小了程序并发执行时的开销,提高了操作系统的并发性能。线程没有自己的系统资源。
进程和线程的区别
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。或者说进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程则是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。

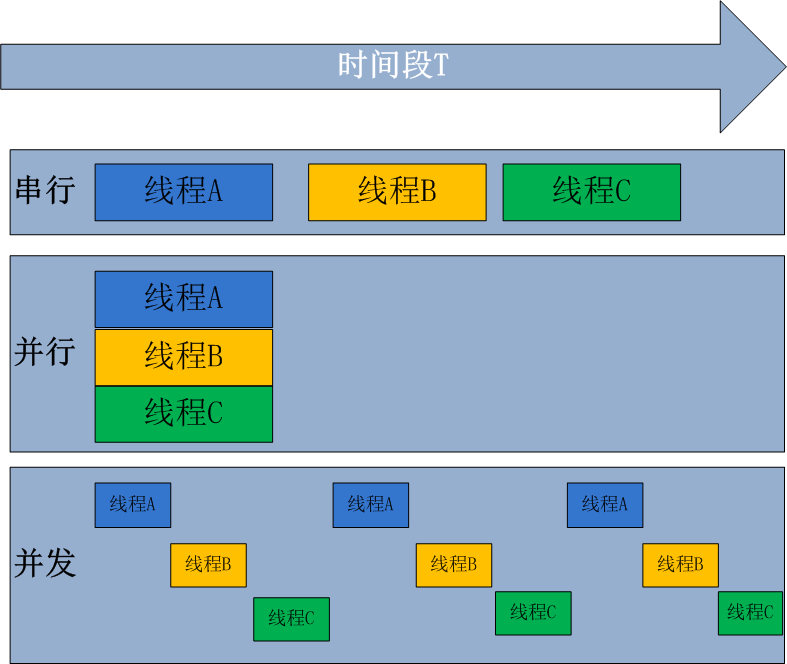
并行和并发
并行处理(Parallel Processing)是计算机系统中能同时执行两个或者更多个处理的一种计算方法。并行处理可同时工作于同一程序的不同方面,并行处理的主要目的是节省大型和复杂问题的解决时间。
并发处理(concurrency Processing)是指一个时间段中有几个程序都处于已经启动运行到运行完毕之间,而且这几个程序都是在同一处理机(CPU)上运行,但任意时刻点上只有一个程序在处理机(CPU)上运行
同步和异步
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
举个例子,打电话时就是同步通信,发短息时就是异步通信。
单例执行
from random import randint
from time import time, sleep
def download_task(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
download_task('Python入门.pdf')
download_task('av.avi')
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
运行是顺序执行,所以耗时是多个进程的时间总和
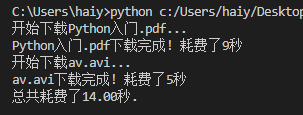
因为是单进程任务,所有任务都是排队进行所以这样执行效率非常的低。我们来添加多进程模式进行多进程同时执行,这样一个进程执行时,另一个进程无需等待,执行时间将大大缩短。
多进程
from random import randint
from time import time, sleep
from multiprocessing import Process
from os import getpid
def download_task(filename):
print('启动下载进程,进程号:[%d]'%getpid())
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task,args=('python入门.pdf',))
p2 = Process(target=download_task,args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
# download_task('Python入门.pdf')
# download_task('av.avi')
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
多个进程并排执行,总耗时就是最长耗时的那个进程的时间。
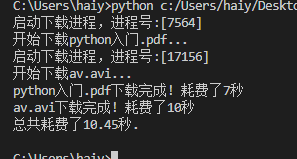
大致的执行流程如下图
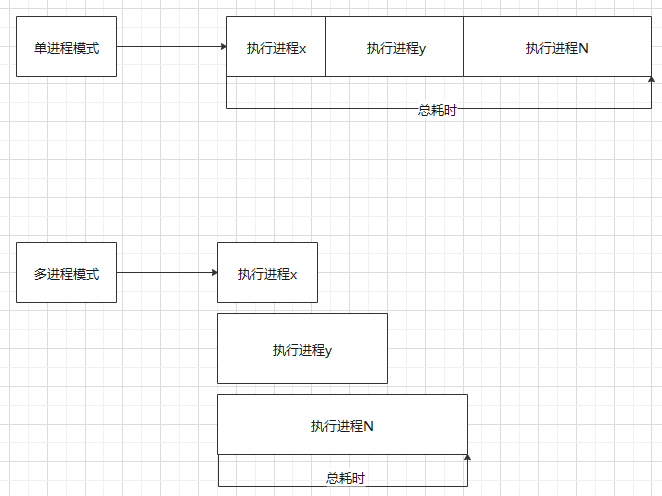
多进程的特点是相互独立,不会共享全局变量,即在一个进程中对全局变量修改过后,不会影响另一个进程中的全局变量。
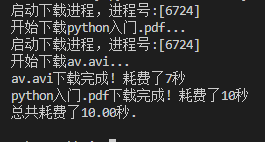
进程间通信
from random import randint
from time import time,sleep
from multiprocessing import Process
from os import getpid
time_to_download = 3
def download_task(filename):
global time_to_download
time_to_download += 1
print('启动下载进程,进程号:[%d]'%getpid())
print('开始下载%s...' % filename)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def download_task2(filename):
global time_to_download
print('启动下载进程,进程号:[%d]'%getpid())
print('开始下载%s...' % filename)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task,args=('python入门.pdf',))
p2 = Process(target=download_task2,args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
从执行结果可以看出,两个进程间的全局变量无法共享,所以它们是相互独立的
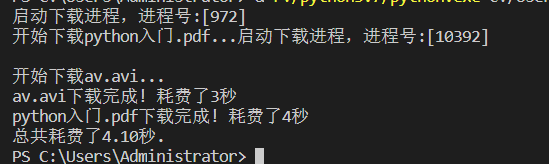
当然多进程也是可以进行通过一些方法进行数据共享的。可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序。
这里介绍Queue的常用进程通信的两种方法:
put 方法用以插入数据到队列中, put 方法还有两个可选参数: blocked 和 timeout。如果 blocked 为 True(默认值),并且 timeout 为正值,该方法会阻塞 timeout 指定的时间,直到该队列有剩余的空间。如果超时,会抛出 Queue.full 异常。如果 blocked 为 False,但该 Queue 已满,会立即抛出 Queue.full 异常。
get 方法可以从队列读取并且删除一个元素。同样, get 方法有两个可选参数: blocked和 timeout。如果 blocked 为 True(默认值),并且 timeout 为正值,那么在等待时间内没有取到任何元素,会抛出 Queue.Empty 异常。如果 blocked 为 False,有两种情况存在,如果Queue 有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty 异常。
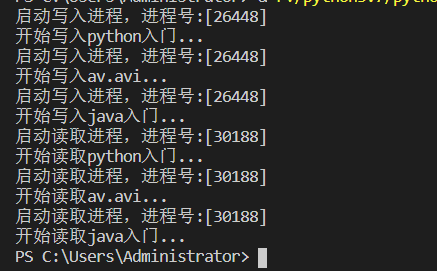
Queue 队列实现进程间通信
from random import randint
from time import time,sleep
from multiprocessing import Process
import multiprocessing
from os import getpid
time_to_download = 3
def write(q):
for i in ['python入门','av.avi','java入门']:
q.put(i)
print('启动写入进程,进程号:[%d]'%getpid())
print('开始写入%s...' % i)
sleep(time_to_download)
def read(q):
while True:
if not q.empty():
print('启动读取进程,进程号:[%d]'%getpid())
print('开始读取%s...' % q.get())
sleep(time_to_download)
else:
break
def main():
q = multiprocessing.Queue()
p1 = Process(target=write,args=(q,))
p2 = Process(target=read,args=(q,))
p1.start()
p1.join()
p2.start()
p2.join()
if __name__ == '__main__':
main()
上一个进程写入的数据通过Queue队列共享给了下一个进程,然后下一个进程可以直接进行使用,这样就完成了多进程间的数据共享。
进程池
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
进程池中常见三个方法:
◆apply:串行
◆apply_async:并行
◆map
多线程
from random import randint
from time import time, sleep
from threading import Thread
from os import getpid
def download_task(filename):
print('启动下载进程,进程号:[%d]' % getpid())
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Thread(target=download_task, args=('python入门.pdf',))
p2 = Thread(target=download_task, args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
多线程执行因为GIL锁的存在,实际上执行是进行单线程,即一次只执行一个线程,然后在切换其他的线程进行执行,因为其中切换的时间非常的短,所以看上去依然像是多线程一起执行。
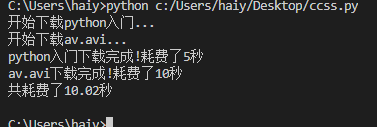
通过继承Thread类的方式来创建自定义的线程类,然后再创建线程对象并启动线程
from random import randint
from threading import Thread
from time import time, sleep
class DownloadTask(Thread):
def __init__(self, filename):
super().__init__()
self._filename = filename
def run(self):
print('开始下载%s...'% self._filename)
time_to_download = randint(5,10)
sleep(time_to_download)
print('%s下载完成!耗费了%d秒' %(self._filename, time_to_download))
def main():
start = time()
t1 = DownloadTask('python入门')
t2 = DownloadTask('av.avi')
t1.start()
t2.start()
t1.join()
t2.join()
end = time()
print('共耗费了%.2f秒'%(end - start))
if __name__ == '__main__':
main()
多线程使用类还是函数执行的结果完全一致,具体怎么使用可以结合自己的使用场景。
到此这篇关于详解Python中的进程和线程的文章就介绍到这了,更多相关Python进程和线程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 多进程、多线程效率对比
Python 界有条不成文的准则: 计算密集型任务适合多进程,IO 密集型任务适合多线程.本篇来作个比较. 通常来说多线程相对于多进程有优势,因为创建一个进程开销比较大,然而因为在 python 中有 GIL 这把大锁的存在,导致执行计算密集型任务时多线程实际只能是单线程.而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的 GIL,互不干扰. 而在 IO 密集型任务中,CPU 时常处于等待状态,操作系统需要
-
Python队列、进程间通信、线程案例
进程互斥锁 多进程同时抢购余票 # 并发运行,效率高,但竞争写同一文件,数据写入错乱 # data.json文件内容为 {"ticket_num": 1} import json import time from multiprocessing import Process def search(user): with open('data.json', 'r', encoding='utf-8') as f: dic = json.load(f) print(f'用户{user}查看
-
python中线程和进程有何区别
引入进程和线程的概念及区别 threading模块提供的类: Thread, Lock, Rlock, Condition, [Bounded]Semaphore, Event, Timer, local. 1.什么是进程 计算机程序只不过是磁盘中可执行的二进制(或其他类型)的数据.它们只有在被读取到内存中,被操作系统调用的时候才开始它们的生命期. 进程(有时被称为重量级进程)是程序的一次执行.每个进程都有自己的地址空间.内存.数据栈及其它记录其运行轨迹的辅助数据. 操作系统管理在其上运行的所有
-
python 在threading中如何处理主进程和子线程的关系
之前用python的多线程,总是处理不好进程和线程之间的关系.后来发现了join和setDaemon函数,才终于弄明白.下面总结一下. 1.使用join函数后,主进程会在调用join的地方等待子线程结束,然后才接着往下执行. join使用实例如下: import time import random import threading class worker(threading.Thread): def __init__(self): threading.Thread.__init__(self
-

Python多线程与多进程相关知识总结
一.什么是进程 进程是执行中的程序,是资源分配的最小单位:操作系统以进程为单位分配存储空间,进程拥有独立地址空间.内存.数据栈等 操作系统管理所有进程的执行,分配资源 可以通过fork或 spawn的方式派生新进程,新进程也有自己独立的内存空间 进程间通信方式(IPC,Inter-Process Communication)共享信息,实现数据共享,包括管道.信号.套接字.共享内存区等. 二.什么是线程 线程是CPU调度的的最小单位 一个进程可以有多个线程 同进程下执行,并共享相同的上下文 线程间
-
Python多进程与多线程的使用场景详解
前言 Python多进程适用的场景:计算密集型(CPU密集型)任务 Python多线程适用的场景:IO密集型任务 计算密集型任务一般指需要做大量的逻辑运算,比如上亿次的加减乘除,使用多核CPU可以并发提高计算性能. IO密集型任务一般指输入输出型,比如文件的读取,或者网络的请求,这类场景一般会遇到IO阻塞,使用多核CPU来执行并不会有太高的性能提升. 下面使用一台64核的虚拟机来执行任务,通过示例代码来区别它们, 示例1:执行计算密集型任务,进行1亿次运算 使用多进程 from multipro
-
Python之多进程与多线程的使用
进程与线程 想象在学校的一个机房,有固定数量的电脑,老师安排了一个爬虫任务让大家一起完成,每个学生使用一台电脑爬取部分数据,将数据放到一个公共数据库.共同资源就像公共数据库,进程就像每一个学生,每多一个学生,就多一个进程来完成这个任务,机房里的电脑数量就像CPU,所以进程数量是CPU决定的,线程就像学生用一台电脑开多个爬虫,爬虫数量由每台电脑的运行内存决定. 一个CPU可以有多个进程,一个进程有一个或多个线程. 多进程 1.导包 from multiprocessing import Proce
-
详解Python中的进程和线程
进程是什么? 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成.我们编写的程序用来描述进程要完成哪些功能以及如何完成:数据集则是程序在执行过程中所需要使用的资源:进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志. 线程是什么? 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID.程序计数器.寄存器集合和堆栈共同组成.线程的引入减小了程序并发
-
详解python中的线程
Python中创建线程有两种方式:函数或者用类来创建线程对象. 函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程. 类:创建threading.Thread的子类来包装一个线程对象. 1.线程的创建 1.1 通过thread类直接创建 import threading import time def foo(n): time.sleep(n) print("foo func:",n) def bar(n): time.sleep(n) prin
-
详解python中GPU版本的opencv常用方法介绍
引言 本篇是以python的视角介绍相关的函数还有自我使用中的一些问题,本想在这篇之前总结一下opencv编译的全过程,但遇到了太多坑,暂时不太想回看做过的笔记,所以这里主要总结python下GPU版本的opencv. 主要函数说明 threshold():二值化,但要指定设定阈值 blendLinear():两幅图片的线形混合 calcHist() createBoxFilter ():创建一个规范化的2D框过滤器 canny边缘检测 createGaussianFilter():创建一个Ga
-
详解Python中的Lock和Rlock
线程是进程中可以调度执行的实体.而且,它是操作系统中可以执行的最小处理单元.简单地说,一个线程就是一个程序中可以独立于其他代码执行的指令序列.为了简单起见,你可以假设线程只是进程的子集! Locks 锁是Python中用于同步的最简单的方式.锁有两种状态:上锁.释放锁. 锁是线程模块中的一个类,有两个主要方法:acquire()和release() 当调用acquire()方法时,它锁定锁的执行并阻塞锁的执行,直到其他线程调用release()方法将其设置为解锁状态.锁帮助我们有效地访问程序中的
-
详解Python中的GIL(全局解释器锁)详解及解决GIL的几种方案
先看一道GIL面试题: 描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因. GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题.它并不是python语言的特性,仅仅是由于历史的原因在CPython解释器中难以移除,因为python语言运行环境大部分默认在CPython解释器中. 通过
-
详解Python中神奇的字符串驻留机制
目录 1 什么是字符串驻留机制 2 如何使用字符串驻留机制 3 简单拼接驻留, 运行时不驻留 4 总结 5 全部代码 今天有一个初学者在学习Python的时候又整不会了. 原因是以下代码: a = [1, 2, 3] b = [1, 2, 3] if a is b: print("a and b point to the same object") else: print("a and b point to different objects") 运行结果是a an
-
一文详解Python中logging模块的用法
目录 一.低配logging 1.v1 2.v2 3.v3 二.高配logging 1.配置日志文件 2.使用日志 三.Django日志配置文件 一.低配logging 日志总共分为以下五个级别,这个五个级别自下而上进行匹配 debug-->info-->warning-->error-->critical,默认最低级别为warning级别. 1.v1 import logging logging.debug('调试信息') logging.info('正常信息') logging
-
详解python中 os._exit() 和 sys.exit(), exit(0)和exit(1) 的用法和区别
详解python中 os._exit() 和 sys.exit(), exit(0)和exit(1) 的用法和区别 os._exit() 和 sys.exit() os._exit() vs sys.exit() 概述 Python的程序有两中退出方式:os._exit(), sys.exit().本文介绍这两种方式的区别和选择. os._exit()会直接将python程序终止,之后的所有代码都不会继续执行. sys.exit()会引发一个异常:SystemExit,如果这个异常没有被捕获,那
-
详解python中asyncio模块
一直对asyncio这个库比较感兴趣,毕竟这是官网也非常推荐的一个实现高并发的一个模块,python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? 异步网络操作并发协程 python3.0时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado python3.4时代,asyncio:支持TCP,子进程 现在的asyncio,有了很多的模块已经在支持:aiohttp,ai
-
详解Python中while无限迭代循环方法
目录 前言 while循环 break语句 和 continue语句 else 子句 无限循环 嵌套while循环 单行 while 循环 前言 Python 有 while 语句和 for 语句作为循环处理.虽然 for 语句具有一定数量的进程,但 while 语句是『直到满足条件』类型的循环进程. 对于无限迭代 while,循环执行的次数没有事先明确指定.相反,只要满足某些条件指定的块就会重复执行. 使用定义迭代 for,指定块将被执行的次数在循环开始时已经倍明确指定. 除了 while 语