详解Python Celery和RabbitMQ实战教程
前言
Celery是一个异步任务队列。它可以用于需要异步运行的任何内容。RabbitMQ是Celery广泛使用的消息代理。在本这篇文章中,我将使用RabbitMQ来介绍Celery的基本概念,然后为一个小型演示项目设置Celery 。最后,设置一个Celery Web控制台来监视我的任务
基本概念
来!看图说话:
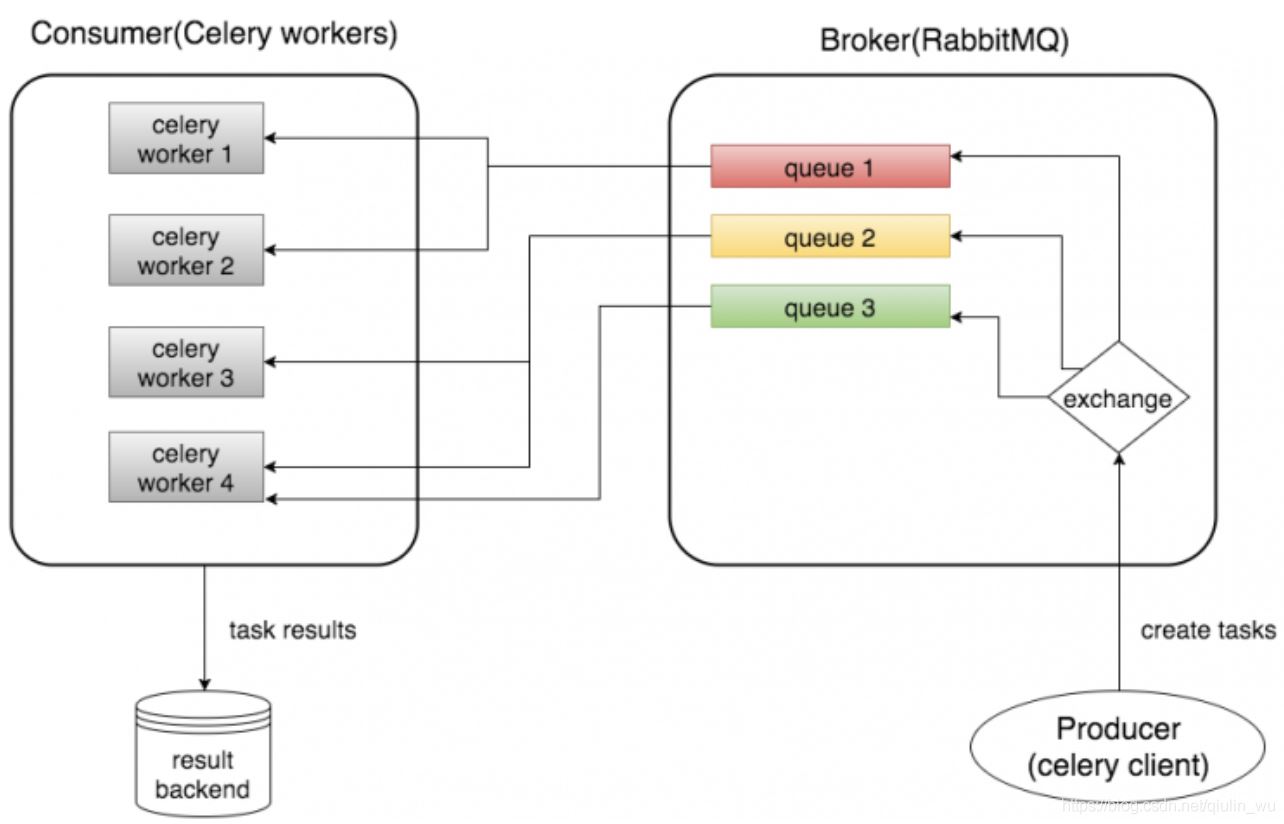
Broker
Broker(RabbitMQ)负责创建任务队列,根据一些路由规则将任务分派到任务队列,然后将任务从任务队列交付给worker
Consumer (Celery Workers)
Consumer是执行任务的一个或多个Celery workers。可以根据用例启动许多workers
Result Backend
后端用于存储任务的结果。但是,它不是必需的元素,如果不在设置中包含它,就无法访问任务的结果
安装Celery
首先,需要安装好Celery,可以使用PyPI:
pip install celery
选择一个Broker:RabbitMQ
为什么我们需要broker呢?这是因为Celery本身并不构造消息队列,所以它需要一个额外的消息传输来完成这项工作。这里可以将Celery看作消息代理的包装器
实际上,也可以从几个不同的代理中进行选择,比如RabbitMQ、Redis或数据库(例如Django数据库)
在这里使用RabbitMQ作为代理,因为它功能完整、稳定,Celery推荐使用它。由于演示我的环境是在Mac OS中,安装RabbitMQ使用Homebrew即可:
brew install rabbitmq #如果是Ubuntu的话使用apt-get安装
启动RabbitMQ
程序将在/usr/local/sbin中安装RabbitMQ,虽然有些系统可能会有所不同。可以将此路径添加到环境变量路径,以便以后方便地使用。例如,打开shell启动文件~/.bash_profile添加:
PATH=$PATH:/usr/local/sbin
现在,可以使用rabbitmq-server命令启动我们的RabbitMQ服务器。检查RabbitMQ服务器成功启动,将看到类似的输出:

为Celery配置RabbitMQ
RabbitMQ使用Celery之前,需要对RabbitMQ进行一些配置。简单地说,我们需要创建一个虚拟主机和用户,然后设置用户权限,以便它可以访问虚拟主机
# 添加用户跟密码 $ rabbitmqctl add_user test test123 # 添加虚拟主机 $ rabbitmqctl add_vhost test_vhost # 为用户添加标签 $ rabbitmqctl set_user_tags test test_tag # 设置用户权限 $ rabbitmqctl set_permissions -p test_vhost test ".*" ".*" ".*"
敲黑板!RabbitMQ中有三种操作:配置、写入和读取
上面命令末尾的字符串表示用户test将拥有所有配置、写入和读取权限
演示项目
现在让我们创建一个简单的项目来演示Celery的使用

在celery.py中添加以下代码:
from __future__ import absolute_import
from celery import Celery
app = Celery('test_celery',
broker='amqp://test:test123@localhost/test_vhost',
backend='rpc://',
include=['test_celery.tasks'])
在这里,初始化了一个名为app的Celery实例,将用于创建一个任务。Celery的第一个参数只是项目包的名称,即“test_celery”。
broker参数指定代理URL,对于RabbitMQ,传输是amqp。
后端参数指定后端URL。Celery中的后端用于存储任务结果。因此,如果需要在任务完成时访问任务的结果,应该为Celery设置一个后端。
rpc意味着将结果作为AMQP消息发送回去,这对本次演示来说是一种可接受的格式
include参数指定了在Celery工作程序启动时要导入的模块列表。我们在这里添加了tasks模块,以便找到我们的任务。
在tasks.py这个文件中,定义了我们的任务add_longtime:
from __future__ import absolute_import from test_celery.celery import app import time @app.task def add_longtime(a, b): print 'long time task begins' # sleep 5 seconds time.sleep(5) print 'long time task finished' return a + b
可以看到,导入了在前面的Celery模块中定义的应用程序,并将其用作任务方法的装饰器。另外注意!app.task只是一个装饰器。此外,我们在add_longtime任务中休眠5秒,以模拟一个耗时较长的Task
在设置好Celery之后,我们需要开始运行任务,它包含在runs_tasks.py:
from .tasks import add_longtime import time if __name__ == '__main__': result = add_longtime.delay(1,2) #此时,任务还未完成,它将返回False print 'Task finished? ', result.ready() print 'Task result: ', result.result # 延长到10秒以确保任务已经完成 time.sleep(10) # 现在任务完成,ready方法将返回True print 'Task finished? ', result.ready() print 'Task result: ', result.result
这里,我们使用delay方法调用任务add_longtime,如果我们想异步处理任务,就需要使用delay方法。此外,保存任务的结果并打印一些信息。如果任务已经完成,ready方法将返回True,否则返回False。result属性是任务的结果,如果任务尚未完成,则返回None。
启动Celery
现在,可以使用下面的命令启动Celery(注:在项目文件夹中运行):
celery -A test_celery worker --loglevel=info
Celery成功连接到RabbitMQ,你会看到这样的东西:

运行任务
再项目文件中输入以下命令运行它:
python -m test_celery.run_tasks
查看Celery控制台,看到运行任务:
[2020-05-15 17:15:21,508: INFO/MainProcess]
Received task: test_celery.tasks.add_longtime[25ba9c87-69a7-4383-b983-1cefdb32f8b3]
[2020-05-15 17:15:21,508: WARNING/Worker-3] long time task begins
[2020-05-15 17:15:31,510: WARNING/Worker-3] long time task finished
[2020-05-15 17:15:31,512: INFO/MainProcess]
Task test_celery.tasks.add_longtime[25ba9c87-69a7-4383-b983-1cefdb32f8b3] succeeded in 15.003732774s: 3
当Celery收到一个任务,它打印出任务名称与任务id(在括号中):
Received task: test_celery.tasks.add_longtime[7d942984-8ea6-4e4d-8097-225616f797d5]
在这一行下面是我们的任务add_longtime打印的两行,时间延迟为5秒:
long time task begins long time task finished
最后一行显示我们的任务在5秒内完成,任务结果为3:
Task test_celery.tasks.add_longtime[7d942984-8ea6-4e4d-8097-225616f797d5] succeeded in 5.025242167s: 3
在当前控制台中,您将看到以下输出:

实时监控Celery
Flower是一款基于网络的Celery实时监控软件。使用Flower,可以轻松地监视任务进度和历史记录
使用pip来安装Flower:
pip install flower
要启动Flower web控制台,需要运行以下命令:
celery -A test_celery flower
Flower将运行具有默认端口5555的服务器,可以通过http://localhost:5555访问web控制台
到此这篇关于详解Python Celery和RabbitMQ实战教程的文章就介绍到这了,更多相关Python Celery和RabbitMQ实战内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python celery分布式任务队列的使用详解
一.Celery介绍和基本使用 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子: 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情. 你想做一个定时任务,比如每天检测一下你们
-
python Celery定时任务的示例
本文介绍了python Celery定时任务的示例,分享给大家,具体如下: 配置 启用Celery的定时任务需要设置CELERYBEAT_SCHEDULE . Celery的定时任务都由celery beat来进行调度.celery beat默认按照settings.py之中的时区时间来调度定时任务. 创建定时任务 一种创建定时任务的方式是配置CELERYBEAT_SCHEDULE: #每30秒调用task.add from datetime import timedelta CELERYBEA
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
Python并行分布式框架Celery详解
Celery 简介 除了redis,还可以使用另外一个神器---Celery.Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农. 在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是"中间人"的意思,在这里 Broker 起到一个中间人的角色.在工头提
-
python使用celery实现异步任务执行的例子
使用celery在django项目中实现异步发送短信 在项目的目录下创建celery_tasks用于保存celery异步任务. 在celery_tasks目录下创建config.py文件,用于保存celery的配置信息 ```broker_url = "redis://127.0.0.1/14"``` 在celery_tasks目录下创建main.py文件,用于作为celery的启动文件 from celery import Celery # 为celery使用django配置文件进行
-
Python celery原理及运行流程解析
celery简介 celery是一个基于分布式消息传输的异步任务队列,它专注于实时处理,同时也支持任务调度.它的执行单元为任务(task),利用多线程,如Eventlet,gevent等,它们能被并发地执行在单个或多个职程服务器(worker servers)上.任务能异步执行(后台运行)或同步执行(等待任务完成). 在生产系统中,celery能够一天处理上百万的任务.它的完整架构图如下: 组件介绍: Producer:调用了Celery提供的API.函数或者装饰器而产生任务并交给任务队列处理的
-
Python Celery多队列配置代码实例
这篇文章主要介绍了Python Celery多队列配置代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Celery官方文档 项目结构 /proj -__init__ -app.py #实例化celery对象 -celeryconfig.py #celery的配置文件 -tasks.py #celery编写任务文件 app.py #coding:utf-8 from __future__ import absolute_import fr
-
Python Celery异步任务队列使用方法解析
Celery是一个异步的任务队列(也叫做分布式任务队列),一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需要的工具. celery的优点 1:简单,容易使用,不需要配置文件 2:高可用,任务执行失败或执行过程中发生连续中断,celery会自动尝试重新执行任务 3:快速,一个单进程的celery每分钟可以处理上百万个任务 4:灵活,几乎celery的各个组件都可以被扩展 celery应用场景 1:异步发邮件,一般发邮件等比较耗时的操作,这个时候需要提交任务给cel
-
详解Python Celery和RabbitMQ实战教程
前言 Celery是一个异步任务队列.它可以用于需要异步运行的任何内容.RabbitMQ是Celery广泛使用的消息代理.在本这篇文章中,我将使用RabbitMQ来介绍Celery的基本概念,然后为一个小型演示项目设置Celery .最后,设置一个Celery Web控制台来监视我的任务 基本概念 来!看图说话: Broker Broker(RabbitMQ)负责创建任务队列,根据一些路由规则将任务分派到任务队列,然后将任务从任务队列交付给worker Consumer (Celery Wo
-
详解Python GUI编程之PyQt5入门到实战
1. PyQt5基础 1.1 GUI编程学什么 大致了解你所选择的GUI库 基本的程序的结构:使用这个GUI库来运行你的GUI程序 各种控件的特性和如何使用 控件的样式 资源的加载 控件的布局 事件和信号 动画特效 界面跳转 设计工具的使用 1.2 PyQT是什么 QT是跨平台C++库的集合,它实现高级API来访问现代桌面和移动系统的许多方面.这些服务包括定位和定位服务.多媒体.NFC和蓝牙连接.基于Chromium的web浏览器以及传统的UI开发.PyQt5是Qt v5的一组完整的Python
-
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for yo
-
详解python 支持向量机(SVM)算法
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度.而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中. 本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂.至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~ 1.SVM简介 支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图: 如上图中,
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
详解Python之unittest单元测试代码
前言 编写函数或者类时,还可以为其编写测试.通过测试,可确定代码面对各种输入都能够按要求的那样工作. 本次我将介绍如何使用Python模块unittest中的工具来测试代码. 测试函数 首先我们先编写一个简单的函数,它接受姓.名.和中间名三个参数,并返回完整的姓名: names.py def get_fullname(firstname,lastname,middel=''): '''创建全名''' if middel: full_name = firstname + ' ' + middel
-
详解python中asyncio模块
一直对asyncio这个库比较感兴趣,毕竟这是官网也非常推荐的一个实现高并发的一个模块,python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? 异步网络操作并发协程 python3.0时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado python3.4时代,asyncio:支持TCP,子进程 现在的asyncio,有了很多的模块已经在支持:aiohttp,ai
-
详解Python 实现 ZeroMQ 的三种基本工作模式
简介 引用官方说法:ZMQ(以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个 socket library,他使得 Socket 编程更加简单.简洁和性能更高. 是一个消息处理队列库,可在多个线程.内核和主机盒之间弹性伸缩. ZMQ 的明确目标是"成为标准网络协议栈的一部分,之后进入 Linux 内核".现在还未看到它们的成功.但是,它无疑是极具前景的.并且是人们更加需要的"传统" BSD 套接字之上的一 层封装.ZMQ 让编写高性能网络应
-
详解Python中第三方库Faker
项目开发初期,为了测试方便,我们总要造不少假数据到系统中,尽量模拟真实环境. 比如要创建一批用户名,创建一段文本,电话号码,街道地址.IP地址等等. 平时我们基本是键盘一顿乱敲,随便造个什么字符串出来,当然谁也不认识谁. 现在你不要这样做了,用Faker就能满足你的一切需求. 1. 安装 pip install Faker 2. 简单使用 >>> from faker import Faker >>> fake = Faker(locale='zh_CN') >&
-
详解Python 关联规则分析
1. 关联规则 大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品. 不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules. 关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系. 1