详解python的变量缓存机制
变量的缓存机制
变量的缓存机制(以下内容仅对python3.6.x版本负责)
机制
只要有两个值相同,就只开辟一个空间
为什么要有这样的机制
在计算机的硬件当中,内存是最重要的配置之一,直接关系到程序的运行速度和流畅度。在过去计算机内存资源昂贵而小的年代中,程序的内存管理成为编程中的重要技术之一。python没有C/C++中的指针那样的定义可以编程者自主的控制内存的分配,而是有一套自动的内存地址分配和缓存机制。在这个机制当中,可以把一些相同值的变量在内存中指向同一块区域,而不再重新开辟一个空间,这样就达到了节省内存的目的。


python中使用id()函数查看数据的内存地址
number部分
整型
对于整型而言,-5~~正无穷的范围内的相同值的id地址一致
# 在后续的版本中所有的数的id地址都一致 # 相同 print(id(9999999), id(9999999)) print(id(100), id(100)) print(id(-5), id(-5)) # 不同 print(id(-6), id(-6))
浮点型
对于浮点型而言,非负数范围内的相同值id一致
# 相同 print(id(9999999.0), id(9999999.0)) print(id(100.0), id(100.0)) # 不同 print(id(-5.0), id(-5.0)) print(id(-6.0), id(-6.0))
布尔值
对于布尔值而言,值相同测情况下,id一致
# 相同 print(id(True), id(True)) print(id(False), id(False))
复数
复数在(实数+虚数)这样的结构当中永不相同,只有单个虚数相同才会一致
# 相同 print(id(1j), id(1j)) print(id(0j), id(0j)) # 不同 print(id(1234j), id(3456j)) print(id(1+1j), id(1+1j)) print(id(2+0j), id(2+0j))
容器部分
字符串
字符串在相同的情况下,地址相同
# 相同
print(id('hello '), id("hello "))
# 不同
print(id('msr'), id('wxd'))
字符串配合使*号使用有特殊的情况:
乘数为1:只要数据相同,地址就是相同的
# 等于1,和正常的情况下是一样的,只要值相同地址就是一样的 a = 'hello ' * 1 b = 'hello ' * 1 print(a is b) a = '祖国' * 1 b = '祖国' * 1 print(a is b)
乘数大于1:只有仅包含数字、字母、下划线时地址是相同的,而且字符串的长度不能大于20
# 纯数字字母下划线,且长度不大于20 a = '_70th' * 3 b = '_70th' * 3 c = '_70th_70th_70th' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: _70th_70th_70th 1734096389168 15 _70th_70th_70th 1734096389168 15 _70th_70th_70th 1734096389168 15 True '''
# 纯数字字母下划线,长度大于20 a = 'motherland_70th' * 3 b = 'motherland_70th' * 3 c = 'motherland_70thmotherland_70thmotherland_70th' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: motherland_70thmotherland_70thmotherland_70th 2281801354864 45 motherland_70thmotherland_70thmotherland_70th 2281801354960 45 motherland_70thmotherland_70thmotherland_70th 2281801354768 45 False '''
# 有其它字符,且长度不大于20 a = '你好' * 3 b = '你好' * 3 c = '你好你好你好' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: 你好你好你好 3115902573360 6 你好你好你好 3115902573448 6 你好你好你好 3115900671904 6 False '''
字符串指定驻留
使用sys模块中的intern函数,让变量指向同一个地址,只要字符串的值是相同的,无论字符的类型、长度、变量的数量,都指向同一个内存地址。
语法:intern(string)
from sys import intern
a = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
b = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
c = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
d = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
e = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
print(a is b is c is d is e)
元组
元组只有为空的情况下,地址相同
# 相同 print(id(()), id(tuple())) # 不同 print(id((1, 2)), id((1, 2)))
列表、集合、字典
任何情况下,地址都不会相同
# 列表、非空元组、集合、字典 无论在声明情况下,id表示都不会相同
# 不同
print(id([]), id([]))
print(id(set()), id(set()))
print(id({}), id({}))
总结
# -->Number 部分 1.对于整型而言,-5~正无穷范围内的相同值 id一致 2.对于浮点数而言,非负数范围内的相同值 id一致 3.布尔值而言,值相同情况下,id一致 4.复数在 实数+虚数 这样的结构中永不相同(只有虚数的情况例外,只有虚数的虚数相同才会id一致) # -->容器类型部分 5.字符串 和 空元组 相同的情况下,地址相同 6.列表,元组,字典,集合无论什么情况 id标识都不同 [空元组例外]
小数据池
以下内容仅对python3.6.8负责
数据在同一个文件(模块)当中,变量存储的的缓存机制就是上述的那样。
但是如果是在不同文件(模块)当中的数据,部分数据就会驻留在小数据池当中。
什么是小数据池
不同的python文件(模块)中的相同数据的本应该是不在同一个内存地址当中的, 而是应该全新的开辟一个新空间,但是这样就造成了内存的空间压力,所以python定义了小数据池的概念,默认允许小部分数据即使在不同的文件当中,只要数据相同就可以使用同一个内存空间,节省内存。
小数据池支持什么类型
小数据池只针对:int、bool、None关键字 ,这些数据类型有效。
int
对于int而言,python在内存中创建了-5 ~ 256 范围的整数,提前驻留在了内存的一块区域,如果是不同文件(模块)的两个变量,声明同一个值,在-5~256这个范围里,那么id一致,两个变量的值都同时指向一个值的地址,节省空间。
# 现在我们打开两个终端,进入python环境中,然后执行下面的指令,你会发现,只有-5 ~ 256范围内的整型的id值相同,而不是之前说过的是-5 ~ 正无穷的范围,这是因为,两个终端环境就相当于两个python文件或者是模块。 print(id(1000)) print(id(500)) print(id(257)) print(id(256)) print(id(-5)) print(id(-6))
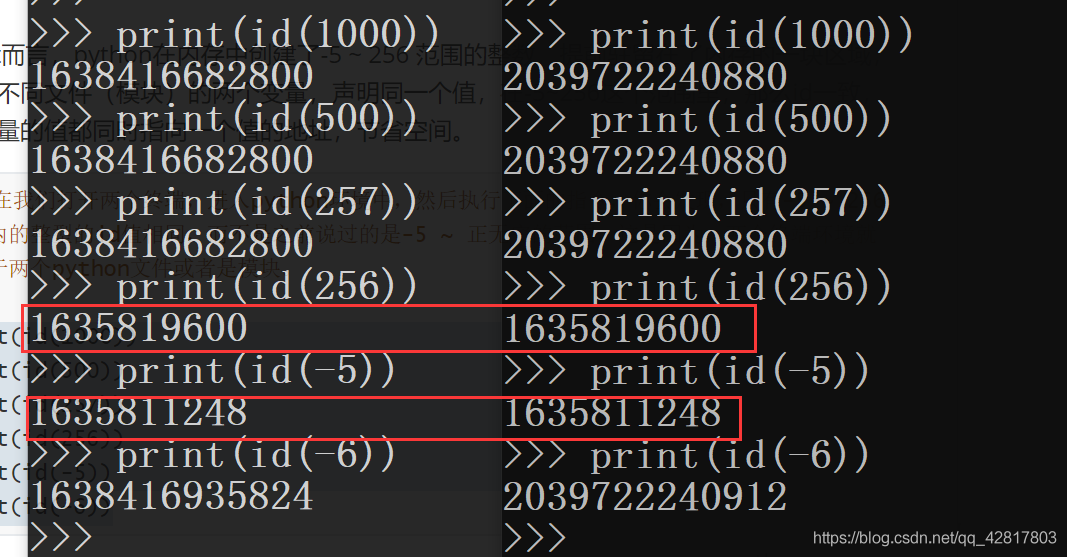
其它
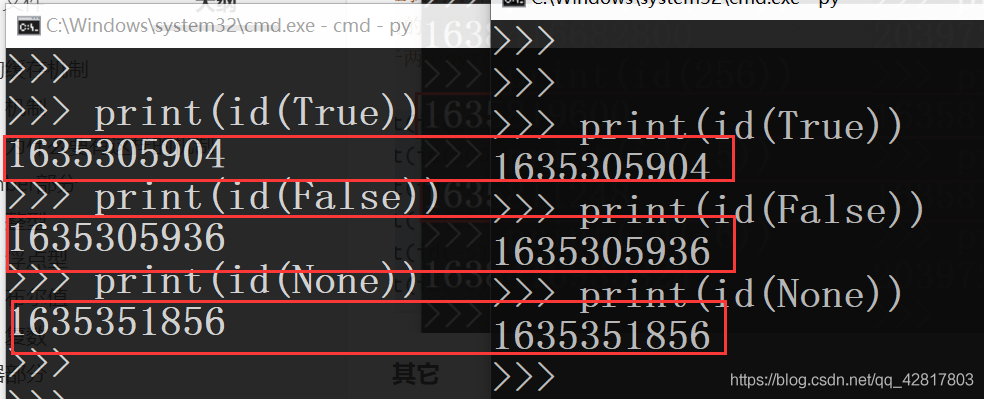
布尔、None这些类型都是有效的
# 开启两个终端测试吧 print(id(True)) print(id(False)) print(id(None))
到此这篇关于python的变量缓存机制的文章就介绍到这了,更多相关python的变量缓存机制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python如何设置静态变量
众所周知,Python语言并不支持静态变量,比如下面这样一个应用场景: void foo() { static int count = 0; count ++; } 在Python中无法自然实现这个功能.换个角度来看这个问题,函数中的静态变量其实可以看做是函数的一个内部变量,而不是调用期间生成的局部变量.所以这里介绍一种使用装饰器的方法给函数添加这样的内部变量. def static_vars(**kwargs): def decorate(func):
-
Python爬虫DNS解析缓存方法实例分析
本文实例讲述了Python爬虫DNS解析缓存方法.分享给大家供大家参考,具体如下: 前言: 这是Python爬虫中DNS解析缓存模块中的核心代码,是去年的代码了,现在放出来 有兴趣的可以看一下. 一般一个域名的DNS解析时间在10~60毫秒之间,这看起来是微不足道,但是对于大型一点的爬虫而言这就不容忽视了.例如我们要爬新浪微博,同个域名下的请求有1千万(这已经不算多的了),那么耗时在10~60万秒之间,一天才86400秒.也就是说单DNS解析这一项就用了好几天时间,此时加上DNS解析缓存,效果就
-
浅谈Python的Django框架中的缓存控制
关于缓存剩下的问题是数据的隐私性以及在级联缓存中数据应该在何处储存的问题. 通常用户将会面对两种缓存: 他或她自己的浏览器缓存(私有缓存)以及他或她的提供者缓存(公共缓存). 公共缓存由多个用户使用,而受其他某人的控制. 这就产生了你不想遇到的敏感数据的问题,比如说你的银行账号被存储在公众缓存中. 因此,Web 应用程序需要以某种方式告诉缓存那些数据是私有的,哪些是公共的. 解决方案是标示出某个页面缓存应当是私有的. 要在 Django 中完成此项工作,可使用 cache_control 视图修
-
python跨文件使用全局变量的实现
Python 定义了全局变量的特性,使用global 关键字修饰 global key_word 但是他的一大缺陷就是只能本module 中也就是本文件中使用,跳出这个module就不行. try 1: 使用一个更宏观的思路,全局变量就用全局加载的模块解决,很遗憾也是不行, file_1: global a a = "test" file 2: import file_1 print(a) 报错a没有定义 try 2: file_1: global a a = "test&q
-
python判断一个变量是否已经设置的方法
python判断一个变量是否已经设置的方法:可以使用locals()函数来进行判断. locals()函数会以字典类型返回当前位置的全部局部变量,具体使用方法如:['testvar' in locals().keys()]. 方法如下: 第一种方法使用内置函数locals(): locals():获取已定义对象字典 'testvar' in locals().keys() 第二种方法使用内置函数dir(): dir():获取已定义对象列表 'testvar' in dir() 第
-
Python的Flask框架使用Redis做数据缓存的配置方法
Redis是一款依据BSD开源协议发行的高性能Key-Value存储系统.会把数据读入内存中提高存取效率.Redis性能极高能支持超过100K+每秒的读写频率,还支持通知key过期等等特性,所以及其适合做缓存. 下载安装 根据redis中文网使用wget下载压缩包 $ wget http://download.redis.io/releases/redis-3.0.5.tar.gz $ tar xzf redis-3.0.5.tar.gz $ cd redis-3.0.5 $ make 二进制文
-

详解python的变量缓存机制
变量的缓存机制 变量的缓存机制(以下内容仅对python3.6.x版本负责) 机制 只要有两个值相同,就只开辟一个空间 为什么要有这样的机制 在计算机的硬件当中,内存是最重要的配置之一,直接关系到程序的运行速度和流畅度.在过去计算机内存资源昂贵而小的年代中,程序的内存管理成为编程中的重要技术之一.python没有C/C++中的指针那样的定义可以编程者自主的控制内存的分配,而是有一套自动的内存地址分配和缓存机制.在这个机制当中,可以把一些相同值的变量在内存中指向同一块区域,而不再重新开辟一个空间,
-
详解python的内存分配机制
开始 作为一个实例,让我们创建四个变量并为其赋值: variable1 = 1 variable2 = "abc" variable3 = (1,2) variable4 = ['a',1] #打印他们的ids print('Variable1: ', id(variable1)) print('Variable2: ', id(variable2)) print('Variable3: ', id(variable3)) print('Variable4: ', id(variabl
-
一文详解Python中的重试机制
目录 介绍 1. 最基本的重试 2. 设置停止基本条件 3. 设置何时进行重试 4. 重试后错误重新抛出 5. 设置回调函数 介绍 为了避免由于一些网络或等其他不可控因素,而引起的功能性问题.比如在发送请求时,会因为网络不稳定,往往会有请求超时的问题. 这种情况下,我们通常会在代码中加入重试的代码.重试的代码本身不难实现,但如何写得优雅.易用,是我们要考虑的问题. 这里要给大家介绍的是一个第三方库 - Tenacity (标题中的重试机制并并不准确,它不是 Python 的内置模块,因此并不能称
-
详解Python小数据池和代码块缓存机制
前言 本文除"总结"外,其余均为认识过程:3.7.5:这部分官方文档不知道在哪里找,目前没有找到,有谁知道的可以麻烦留言吗? 谢谢了! 总结: 如果在同一代码块下,则采用同一代码块下的缓存机制: 如果是不同代码块,则采用小数据池的驻留机制: 需要注意的是,交互式输入时,每个命令都是一个代码块: 实现 Intern 保留机制的方式非常简单,就是通过维护一个字符串储蓄池,这个池子是一个字典结构,编译时,如果字符串已经存在于池子中就不再去创建新的字符串,直接返回之前创建好的字符串对象, 如果
-
详解Python中import机制
Python语言中import的使用很简单,直接使用import module_name语句导入即可.这里我主要写一下"import"的本质. Python官方定义: Python code in one module gains access to the code in another module by the process of importing it. 1.定义: 模块(module):用来从逻辑(实现一个功能)上组织Python代码(变量.函数.类),本质就是*.py文
-
详解Python垃圾回收机制和常量池的验证
Python的引入 人类认识世界是从认识世界中的一个又一个实物开始,然后再对其用语言加以描述.例如当中国人看到苹果时,便会用中文"苹果"加以描述,而用英语的一些国家则会用"apple"加以描述. 以上说到的中文和英文都是人类认识并描述世界的一个工具,而在计算机的世界中,为了让计算机去认知世界,从而帮助人类完成更多的任务.在计算机领域中也发展了语言这个工具,从早期的机器语言到汇编语言再到现在使用范围较广的高级语言.而我们接下来要介绍的Python则属于高级语言这一分支
-
详解Python中神奇的字符串驻留机制
目录 1 什么是字符串驻留机制 2 如何使用字符串驻留机制 3 简单拼接驻留, 运行时不驻留 4 总结 5 全部代码 今天有一个初学者在学习Python的时候又整不会了. 原因是以下代码: a = [1, 2, 3] b = [1, 2, 3] if a is b: print("a and b point to the same object") else: print("a and b point to different objects") 运行结果是a an
-
详解python变量与数据类型
这篇文章我们学习 Python 变量与数据类型 变量 变量来源于数学,是计算机语言中能储存计算结果或能表示值抽象概念,变量可以通过变量名访问.在 Python 中 变量命名规定,必须是大小写英文,数字和 下划线(_)的组合,并且不能用数字开头. 变量命名规则: 变量名只能是字母,数字和下划线的任意组合 变量名第一个字符不能是数字 变量名区分大小写,大小写字母被认为是两个不同的字符 特殊关键字不能命名为变量名 声明变量 Python 中的变量不需要声明,每个变量在使用前都必须赋值,变量赋值以后该变
-
详解python中的 is 操作符
大家可以与Java中的 == 操作符相互印证一下,加深一下对引用和对象的理解.原问题: Python为什么直接运行和在命令行运行同样语句但结果却不同,他们的缓存机制不同吗? 其实,高票答案已经说得很详细了.我只是再补充一点而已. is 操作符是Python语言的一个内建的操作符.它的作用在于比较两个变量是否指向了同一个对象. 与 == 的区别 class A(): def __init__(self, v): self.value = v def __eq__(self, t): return
-
详解Python自建logging模块
简单使用 最开始,我们用最短的代码体验一下logging的基本功能. import logging logger = logging.getLogger() logging.basicConfig() logger.setLevel('DEBUG') logger.debug('logsomething') #输出 out>>DEBG:root:logsomething 第一步,通过logging.getLogger函数,获取一个loger对象,但这个对象暂时是无法使用的. 第二步,loggi