Python分析最近大火的网剧《隐秘的角落》
前言
估计最近很火的连续剧《隐秘的角落》大家趁着端午假期都看过了吧?小编也跟着潮流,一口气把12集的连续剧全部看完了。看过的人肯定对朋友圈里有人发的“一起去爬山”、“小白船”、“还有机会吗”的意思心照不宣。没看过的,如果已为人父人母的,强烈要求看一下。
剧很精彩,但追剧界有句俗话说得好:“弹幕往往比剧更精彩”,为了让精彩延续下去,咱们来看看该剧弹幕的部分。电视剧是在爱奇艺独播,因此从爱奇艺上爬虫最为合适。
爬取弹幕
爱奇艺的弹幕数据是以 .z 形式的压缩文件存在的,先获取 tvid 列表,再根据 tvid 获取弹幕的压缩文件,最后对其进行解压及存储,大概就是这样一个过程。
def get_data(tv_name,tv_id):
url = https://cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z
datas = pd.DataFrame(columns=[uid,contentsId,contents,likeCount])
for i in range(1,20):
myUrl = url.format(tv_id[-4:-2],tv_id[-2:],tv_id,i)
print(myUrl)
res = requests.get(myUrl)
if res.status_code == 200:
btArr = bytearray(res.content)
xml=zlib.decompress(btArr).decode(utf-8)
bs = BeautifulSoup(xml,"xml")
data = pd.DataFrame(columns=[uid,contentsId,contents,likeCount])
data[uid] = [i.text for i in bs.findAll(uid)]
data[contentsId] = [i.text for i in bs.findAll(contentId)]
data[contents] = [i.text for i in bs.findAll(content)]
data[likeCount] = [i.text for i in bs.findAll(likeCount)]
else:
break
datas = pd.concat([datas,data],ignore_index = True)
datas[tv_name]= str(tv_name)
return datas
共爬取得到201865 条《隐秘的角落》弹幕数据。

弹幕发射器
按照用户id分组并对弹幕id计数,可以得到每位用户的累计发送弹幕数。
#累计发送弹幕数的用户 danmu_counts = df.groupby(uid)[contentsId].count().sort_values(ascending = False).reset_index() danmu_counts.columns = [用户id,累计发送弹幕数] danmu_counts.head()
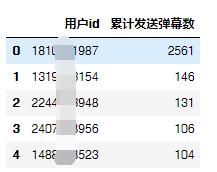
累计发送弹幕数用户top5
第一名竟然发送了2561条弹幕,这只是一部12集的网剧啊。
难道他/她是水军?每条都发的差不多?
df_top1 = df[df[uid] == 1810351987].sort_values(by="likeCount",ascending = False).reset_index() df_top1.head(10)

然而并不是,每一条弹幕都是这位观众的有感而发,可能他/她只是在发弹幕的同时顺便看看剧吧。
这位“弹幕发射器”朋友,在每一集的弹幕量又是如何呢?
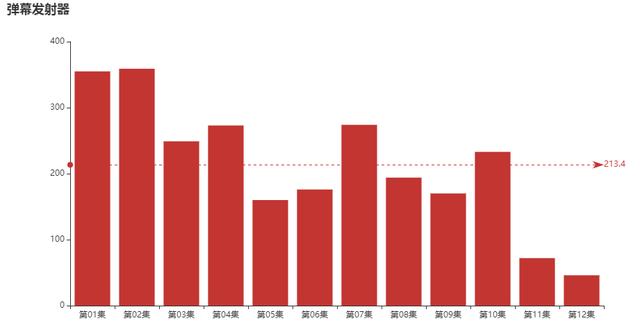
分集&平均弹幕量
是不是通过上图可以侧面说明个别剧集的戏剧冲突更大,更能引发观众吐槽呢?
“弹幕发射器”同志,11、12集请加大输出!
这些弹幕大家都认同
抛开“弹幕发射器”同志,我们继续探究一下分集的弹幕。
看看每一集当中,哪些弹幕大家都很认同(赞)?
df_like = df[df.groupby([tv_name])[likeCount].rank(method="first", ascending=False)==1].reset_index()[[tv_name,contents,likeCount]] df_like.columns = [剧集,弹幕,赞] df_like
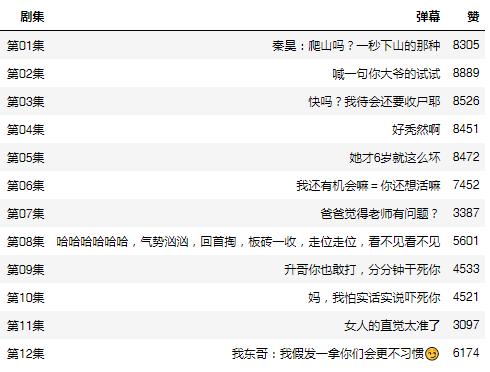
每一集中点赞最多的弹幕
每一集的最佳弹幕都是当集剧情的浓缩,这些就是观众们票选出来的梗(吐槽)啊!
应该不算剧透吧,不算吧,不算吧
实在不行我请你去爬山也可

总结
除了剧本、音乐等,“老戏骨”和“小演员”们的演技也获得了网友的一致好评。
这部剧虽然短短12集,但故事线不仅仅在一两个人身上。每个人都有自己背后的故事,又因为种种巧合串联在一起,引发观众的持续性讨论。
我们统计一下演员们在弹幕中的出现次数,看看剧中的哪些角色大家提及最多
到此这篇关于Python分析最近大火的网剧《隐秘的角落》的文章就介绍到这了,更多相关python分析隐秘的角落内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬取Bilibili弹幕过程解析
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的. 也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的. 接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件
-
Python爬虫 bilibili视频弹幕提取过程详解
两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 import requests from lxml import etree import re # 使用手机UA headers = { "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like
-
python3写爬取B站视频弹幕功能
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快: pip3 install request -i http://pypi.douban.com/simple 爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求 点击查看历史弹幕,获取请求 其中rolldate后面的数字表示该视频对应的弹幕号,返
-
Python脚本如何在bilibili中查找弹幕发送者
总所周知bilibili是没有办法直接查看弹幕的发送者的,这使得当我们看到一些nt弹幕的时候虽然生气,却无可奈何,但是B站是可以屏蔽某个用户发送的弹幕的,这说明数据接口里肯定有用户信息,由于最近在学爬虫,所以我想先找找弹幕接口,分析下里面的数据. 找接口 找接口当然是随便打开一个视频然后F12啦,可是当我找了两圈后我傻眼了,没找到啊..得,不能把时间浪费在这种事情上,果断打开百度,不出所料,找到了如下的两个接口,都是XML格式网页 https://comment.bilibili.com/+ci
-
Python分析最近大火的网剧《隐秘的角落》
前言 估计最近很火的连续剧<隐秘的角落>大家趁着端午假期都看过了吧?小编也跟着潮流,一口气把12集的连续剧全部看完了.看过的人肯定对朋友圈里有人发的"一起去爬山"."小白船"."还有机会吗"的意思心照不宣.没看过的,如果已为人父人母的,强烈要求看一下. 剧很精彩,但追剧界有句俗话说得好:"弹幕往往比剧更精彩",为了让精彩延续下去,咱们来看看该剧弹幕的部分.电视剧是在爱奇艺独播,因此从爱奇艺上爬虫最为合适. 爬取弹幕
-
如何基于Python爬取隐秘的角落评论
"一起去爬山吧?" 这句台词火爆了整个朋友圈,没错,就是来自最近热门的<隐秘的角落>,豆瓣评分8.9分,好评不断. 感觉还是蛮不错的.同时,为了想更进一步了解一下小伙伴观剧的情况,永恒君抓取了爱奇艺平台评论数据并进行了分析.下面来做个分享,给大伙参考参考. 1.爬取评论数据 因为该剧是在爱奇艺平台独播的,自然数据源从这里取比较合适.永恒君爬取了<隐秘的角落>12集的从开播日6月16日-6月26日的评论数据. 使用 Chrome 查看源代码模式,在播放页面往下面滑
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
python分析网页上所有超链接的方法
本文实例讲述了python分析网页上所有超链接的方法.分享给大家供大家参考.具体实现方法如下: import urllib, htmllib, formatter website = urllib.urlopen("http://yourweb.com") data = website.read() website.close() format = formatter.AbstractFormatter(formatter.NullWriter()) ptext = htmllib.H
-
Python 分析Nginx访问日志并保存到MySQL数据库实例
使用Python 分析Nginx access 日志,根据Nginx日志格式进行分割并存入MySQL数据库.一.Nginx access日志格式如下: 复制代码 代码如下: $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_f
-
Python简单获取自身外网IP的方法
本文实例讲述了Python简单获取自身外网IP的方法.分享给大家供大家参考,具体如下: #encoding=utf-8 #author: walker #date: 2016-03-07 #function: 获取自己的外网IP import requests from bs4 import BeautifulSoup #获取外网IP def GetOuterIP(): url = r'http://www.whereismyip.com/' r = requests.get(url) bTag
-
python分析作业提交情况
这次做一个比较贴近我实际的东西:python分析作业提交情况. 要求: 将服务器中交作业的学生(根据文件的名字进行提取)和统计成绩的表格中的学生的信息进行比对,输出所有没有交作业的同学的信息(学号和姓名),并输出所交的作业中命名格式有问题的文件名的信息(如1627406012_E03....). 提示: 提示: 1.根据服务器文件可以拿到所有交了作业的同学的信息. 2.根据表格可以拿到所有上课学生的信息 3.对1和2中的信息进行比对,找出想要得到的信息 注意:提取服务器中学生交的作业的信息的时候
-
Python实现的文轩网爬虫完整示例
本文实例讲述了Python实现的文轩网爬虫.分享给大家供大家参考,具体如下: encoding=utf8 import pymysql import time import sys import requests import os #捕获错误 import traceback import types #将html实体化 import cgi import warnings reload(sys) sys.setdefaultencoding('utf-8') from pyquery imp
-
使用python分析统计自己微信朋友的信息
首先,你得安装itchat,命令为pip install itchat,其余的较为简单,我不再说明,直接看注释吧. 以下的代码我在Win7+Python3.7里面调试通过 __author__ = 'Yue Qingxuan' # -*- coding: utf-8 -*- import itchat # hotReload=True可不用每次都去扫描二维码,只需要手机上确认下 itchat.auto_login(hotReload=True) # 获取好友列表 friends = itchat
-
python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息) import requests from bs4 import BeautifulSoup from http import cookies import urllib impo