解决Python复杂zip文件的解压问题

废话不多说,直接看问题,使用过 Python 中的标准库 zipfile 解压过 zip 格式压缩包的朋友们,可能遇到过,当压缩文件中的目录或文件名中包含中文等常见 unicode 字符时,典型如下面的例子:

使用 zipfile 的 extract() 或 extractall() 方法直接解压时,产生的解压结果名充斥着乱码,这一点我们通过调用 namelist() 方法就可以看出来:
from zipfile import ZipFile
# 读入压缩包文件
file = ZipFile('示例压缩包.zip')
# 查看压缩包内目录、文件名称
file.namelist()

这是因为 zipfile 中针对压缩包内容的编码兼容性差,但我们可以通过下面的函数自行矫正:
def recode(raw: str) -> str:
'''
编码修正
'''
try:
return raw.encode('cp437').decode('gbk')
except:
return raw.encode('utf-8').decode('utf-8')
for file_or_path in file.namelist():
print(file_or_path, ' -------> ' , recode(file_or_path))
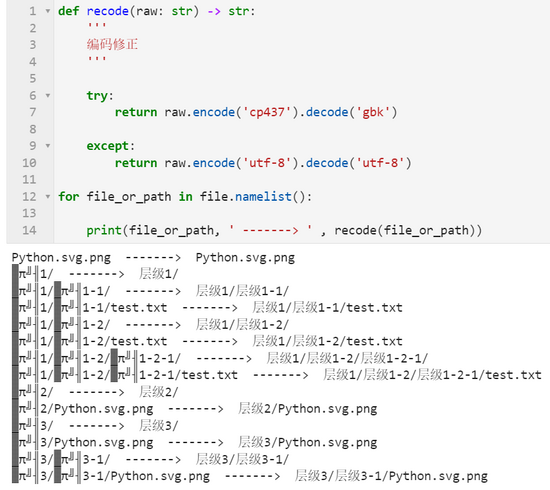
解决了文件名乱码的问题后,接下来我们就可以配合 shutil 与 os 标准库中的相关功能,实现将指定任意 zip 压缩包,完好地解压到指定的目录中,代码如下:
def zip_extract_all(src_zip_file: ZipFile, target_path: str) -> None:
# 遍历压缩包内所有内容
for file_or_path in file.namelist():
# 若当前节点是文件夹
if file_or_path.endswith('/'):
try:
# 基于当前文件夹节点创建多层文件夹
os.makedirs(os.path.join(target_path, recode(file_or_path)))
except FileExistsError:
# 若已存在则跳过创建过程
pass
# 否则视作文件进行写出
else:
# 利用shutil.copyfileobj,从压缩包io流中提取目标文件内容写出到目标路径
with open(os.path.join(target_path, recode(file_or_path)), 'wb') as z:
# 这里基于Zipfile.open()提取文件内容时需要使用原始的乱码文件名
shutil.copyfileobj(src_zip_file.open(file_or_path), z)
# 向已存在的指定文件夹完整解压当前读入的zip文件
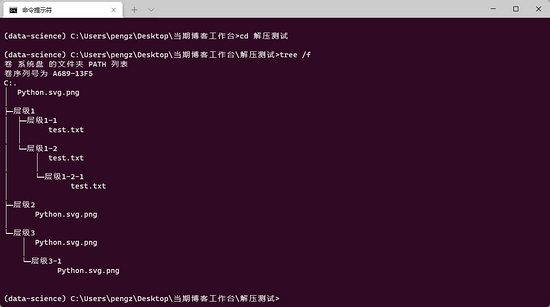
zip_extract_all(file, '解压测试')
可以看到,效果完美 :
到此这篇关于Python复杂zip文件的解压的文章就介绍到这了,更多相关Python zip文件的解压内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python下解压缩zip文件并删除文件的实例
利用python下载数据,下载下来的数据为zip格式,因为有上千个这样的文件,因此便直接在爬虫程序里加入了解压缩zip文件的内容,并且因为数据量较大,为了节省空间,便在解压缩后立即删除该zip文件. 先来介绍解压缩的方法: import zipfile filename = '/home/username/work/1.zip' fz = zipfile.ZipFile(filename, 'r') for file in fz.namelist(): fz.extract(file, path
-
Python实现压缩文件夹与解压缩zip文件的方法
本文实例讲述了Python实现压缩文件夹与解压缩zip文件的方法.分享给大家供大家参考,具体如下: 直接上代码 #coding=utf-8 #甄码农python代码 #使用zipfile做目录压缩,解压缩功能 import os,os.path import zipfile def zip_dir(dirname,zipfilename): filelist = [] if os.path.isfile(dirname): filelist.append(dirname) else : for
-
python批量解压zip文件的方法
这是一个用python写解压大量zip脚本的说明,本人新手一个,希望能对各位有所启发. 首先要注意的,在运行自己的脚本之前一定先备份或者复制出一些样本进行测试,不然出错会很麻烦: 之后我用到的是解压zip文件的扩展包zipfile,可以直接pip安装或者在IDE里安装,需要特别注意的是这个包的文件名解码方式需要我们去修改,先去查看源文件,直接搜索"cp437"(一个编码方式),找到后全部替换为"gbk",即可解决中文显示问题. 代码: import os impor
-

手把手教你使用Python解决简单的zip文件解压密码
目录 简介 文件创建 纯数字密码 字母数字混合密码 补充说明 简介 使用的核心模块是python标准库中的zipfile模块.这个模块可以实现zip文件的各种功能,具体可以查看官方参考文档.这里的暴力破解的意思是对密码可能序列中的值一个一个进行密码尝试,这对人来说是很难的,可是对计算机而言并不难.有时候我们下载的zip文件需要密码解压而我们不知道,需要付费才知道.所以这里主要介绍两种暴力破解的密码:纯数字密码和英文数字组合密码. 文件创建 首先测试文件为test.txt(仅包含单行文本),压缩后
-
解决Python复杂zip文件的解压问题
废话不多说,直接看问题,使用过 Python 中的标准库 zipfile 解压过 zip 格式压缩包的朋友们,可能遇到过,当压缩文件中的目录或文件名中包含中文等常见 unicode 字符时,典型如下面的例子: 使用 zipfile 的 extract() 或 extractall() 方法直接解压时,产生的解压结果名充斥着乱码,这一点我们通过调用 namelist() 方法就可以看出来: from zipfile import ZipFile # 读入压缩包文件 file = ZipFile('
-
python 实现tar文件压缩解压的实例详解
python 实现tar文件压缩解压的实例详解 压缩文件: import tarfile import os def tar(fname): t = tarfile.open(fname + ".tar.gz", "w:gz") for root, dir, files in os.walk(fname): print root, dir, files for file in files: fullpath = os.path.join(root, file) t.
-
详解python破解zip文件密码的方法
1.单线程破解纯数字密码 注意: 不包括数字0开头的密码 import zipfile,time,sys start_time = time.time() def extract(): zfile = zipfile.ZipFile('IdonKnow.zip')#读取压缩包,如果用必要可以加上'r' for num in range(1,99999,1): try: pwd = str(num) zfile.extractall(path='.',pwd=pwd.encode('utf-8')
-
Python遍历zip文件输出名称时出现乱码问题的解决方法
本文实例讲述了Python遍历zip文件输出名称时出现乱码问题的解决方法.分享给大家供大家参考.具体如下: windows中使用python2.7遍历zip文件之后输出文件名等信息,console打印的中文及一些标点出现乱码.查了一下网上说的windows的编码为cp936,print()函数交给系统处理打印,所以要提前编码成windows能够识别的编码. 这种print的乱码也会出现在形如print(mylist)中(mylist是python的list类型变量,print(mylist[2]
-
Android实现下载zip压缩文件并解压的方法(附源码)
前言 其实在网上有很多介绍下载文件或者解压zip文件的文章,但是两者结合的不多,所以这篇文章在此记录一下下载zip文件并直接解压的方法,直接上代码,文末有源码下载. 下载: import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream
-
java实现文件夹解压和压缩
本文实例为大家分享了java实现文件夹解压和压缩的具体代码,供大家参考,具体内容如下 效果 实现多个文件以及文件夹的压缩和解压 代码分析 import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.util.zip.ZipEntry
-
手把手教你怎么用Python实现zip文件密码的破解
Python有一个内置模块zipfile可以干这个事情,测试一波,一个测试文件,设置解压密码为123. import zipfile # 创建文件句柄 file = zipfile.ZipFile("测试.zip", 'r') # 提取压缩文件中的内容,注意密码必须是bytes格式,path表示提取到哪 file.extractall(path='.', pwd='123'.encode('utf-8')) 运行效果如下图所示,提取成功. 好了开始破解老文件的密码,为了提高速度我加了多
-
Linux下.tar.xz文件的解压教程详解
前言 对于xz这个压缩相信很多人陌生,但xz是绝大数linux默认就带的一个压缩工具,xz格式比7z还要小. 最近在下载某个源码包的时候遇到的这种压缩格式,乘此机会分享一下xz的压缩与解压方法. 安装 如果系统没有xz命令,需要进行安装,安装方法非常简单, 在centos下,直接运行: yum install xz 也可以使用源码包安装: 先下载该工具源码包http://tukaani.org/xz/ 下载后解压进入该目录运行configure生成makefile文件用-prefix指定安装目录
-
Windows 64位重装MySQL的教程(Zip版、解压版MySQL安装)
卸载MySQL 1.在控制面板,卸载MySQL的所有组件 控制面板-->所有控制面板项-->程序和功能,卸载所有和MySQL有关的程序 2.找到你的MysQL安装路径,看还有没有和MySQL有关的文件夹,全删 如果安装在C盘,检查一下C:\Program Files (x86)和C:\Program Files 这两个文件夹 3.删除关于MySQL的注册表 在文件资源管理器中输入"C:\Windows\regedit.exe"会弹出注册表 删除HKEY_LOCAL_MACH