带你玩转Kafka之初步使用
目录
- 前言
- 1 简单介绍
- 2 下载安装
- 3 基本使用
- 3.1 启动Kafka
- 3.2 简单测试使用
- 3.3 搭建多代理集群
- 3.3.1 开始搭建
- 3.3.2 使用
- 3.3.3 验证容错性
- 4 小总结
- 总结
前言
官方文档:http://kafka.apache.org/
中文文档:https://kafka.apachecn.org/
Apache Kafka是分布式发布-订阅消息系统。
Apache Kafka与传统消息系统相比,有以下不同:
- 它被设计为一个分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
1 简单介绍
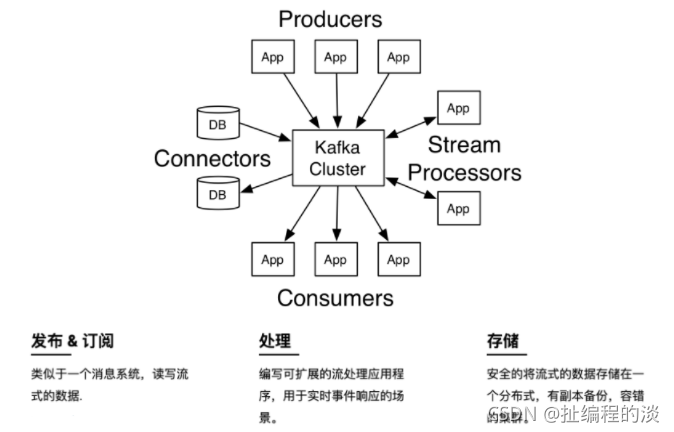
首先是一些概念:
Kafka作为一个集群,运行在一台或者多台服务器上.Kafka 通过 topic 对存储的流数据进行分类。每条记录中包含一个key,一个value和一个timestamp(时间戳)。
Kafka有四个核心的API:
The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
The Consumer API允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
支持的语言(除了Java之外的):

常见概念:
1 Topics和日志
让我们首先深入了解下Kafka的核心概念:提供一串流式的记录— topic
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:

每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制. 举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题.
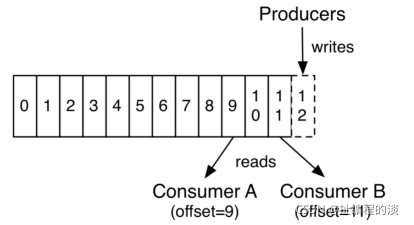
日志中的 partition(分区)有以下几个用途。第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。第二,可以作为并行的单元集—关于这一点,更多细节如下
2 分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
3 生产者
生产者可以将数据发布到所选择的topic中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。下面会介绍更多关于分区的使用。
4 消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
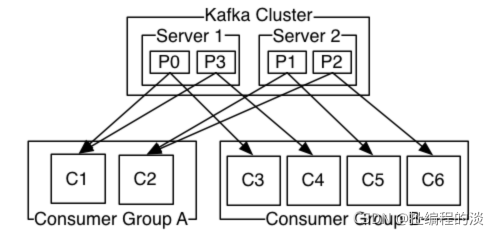
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
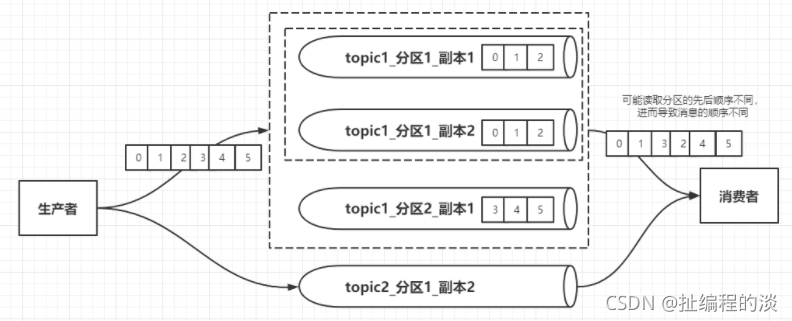
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
保证
high-level Kafka给予以下保证:
生产者发送到特定topic partition 的消息将按照发送的顺序处理。 也就是说,如果记录M1和记录M2由相同的生产者发送,并先发送M1记录,那么M1的偏移比M2小,并在日志中较早出现一个消费者实例按照日志中的顺序查看记录.对于具有N个副本的主题,我们最多容忍N-1个服务器故障,从而保证不会丢失任何提交到日志中的记录.
关于保证的更多细节可以看文档的设计部分。
2 下载安装
Kafka依赖于Zookeeper,而Zookeeper又依赖于Java,因此在使用Kafka之前要安装jdk1.8的环境和启动zookeeper服务器。
下载或安装地址:
JDK1.8://www.jb51.net/article/229780.htm:
https://www.jb51.net/article/229783.htm:
https://kafka.apachecn.org/downloads.html
好,下面我们开始进行安装
[root@iZ2ze4m2ri7irkf6h6n8zoZ local]# tar -zxf kafka_2.11-1.0.0.tgz [root@iZ2ze4m2ri7irkf6h6n8zoZ local]# mv kafka_2.11-1.0.0 kafka-2.11
3 基本使用
3.1 启动Kafka
首先检查下自己的jdk 是否安装:
[root@iZ2ze4m2ri7irkf6h6n8zoZ local]# java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
启动Zookeeper:
[root@iZ2ze4m2ri7irkf6h6n8zoZ zookeeper-3.5.9]# ls bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.txt [root@iZ2ze4m2ri7irkf6h6n8zoZ zookeeper-3.5.9]# cd conf/ [root@iZ2ze4m2ri7irkf6h6n8zoZ conf]# ls configuration.xsl log4j.properties zoo_sample.cfg [root@iZ2ze4m2ri7irkf6h6n8zoZ conf]# cp zoo_sample.cfg zoo.cfg [root@iZ2ze4m2ri7irkf6h6n8zoZ conf]# cd ../bin/ [root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ls README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd [root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./zkServer. zkServer.cmd zkServer.sh [root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.5.9/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
启动Kafka:
[root@iZ2ze4m2ri7irkf6h6n8zoZ kafka-2.11]# ls bin config libs LICENSE NOTICE site-docs [root@iZ2ze4m2ri7irkf6h6n8zoZ kafka-2.11]# cd config/ [root@iZ2ze4m2ri7irkf6h6n8zoZ config]# ls connect-console-sink.properties connect-file-source.properties log4j.properties zookeeper.properties connect-console-source.properties connect-log4j.properties producer.properties connect-distributed.properties connect-standalone.properties server.properties connect-file-sink.properties consumer.properties tools-log4j.properties [root@iZ2ze4m2ri7irkf6h6n8zoZ config]# cd ../bin/ [root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-server-start.sh ../config/server.properties [2021-11-20 10:21:10,326] INFO KafkaConfig values: ...... [2021-11-20 10:21:12,423] INFO Kafka version : 1.0.0 (org.apache.kafka.common.utils.AppInfoParser) [2021-11-20 10:21:12,423] INFO Kafka commitId : aaa7af6d4a11b29d (org.apache.kafka.common.utils.AppInfoParser) [2021-11-20 10:21:12,424] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
3.2 简单测试使用
新建和查看topic
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic ymx Created topic "ymx". [root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-topics.sh --list --zookeeper localhost:2181 ymx
生产者发送消息:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic ymx >Hello Kafka! >Hello Ymx! >Hello Kafka and Ymx! >
消费者消费消息:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ymx --from-beginning Hello Kafka! Hello Ymx! Hello Kafka and Ymx!
3.3 搭建多代理集群
3.3.1 开始搭建
首先要copy下配置文件
[root@iZ2ze4m2ri7irkf6h6n8zoZ config]# cp server.properties server-01.properties [root@iZ2ze4m2ri7irkf6h6n8zoZ config]# cp server.properties server-02.properties [root@iZ2ze4m2ri7irkf6h6n8zoZ config]# vim server-01.properties #### 内容开始 #### broker.id=1 # 21行左右,broker的唯一标识(同一个集群中) listeners=PLAINTEXT://:9093 # 31行左右,放开,代表kafka的端口号 log.dirs=/tmp/kafka-logs-01 # 60行左右,用逗号分隔的目录列表,在其中存储日志文件 #### 内容结束 #### [root@iZ2ze4m2ri7irkf6h6n8zoZ config]# vim server-02.properties #### 内容开始 #### broker.id=2 # 21行左右,broker的唯一标识(同一个集群中) listeners=PLAINTEXT://:9094 # 31行左右,放开,代表kafka的端口号 log.dirs=/tmp/kafka-logs-02 # 60行左右,用逗号分隔的目录列表,在其中存储日志文件 #### 内容结束 ####
根据配置文件启动Kafka(同一主机下)
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties
报错信息:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12) # # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory. # An error report file with more information is saved as: # /usr/local/kafka-2.11/bin/hs_err_pid4036.log
原因:物理机或虚拟机内存不足,不足以保证Kafka启动或运行时需要的内容容量
解决方式:
增加物理机或虚拟机的内存
减少Kafka启动所需内容的配置,将要修改的文件为kafka-server-start.sh
export KAFKA_HEAP_OPTS="-Xmx512M -Xms256M" #29行左右
3.3.2 使用
解决好之后我们开始启动:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties [2021-11-20 10:58:33,138] INFO KafkaConfig values:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-server-start.sh ../config/server-02.properties [2021-11-20 10:59:04,187] INFO KafkaConfig values:
ps:看下我们的阿里云服务器的状况

[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic mr-yan
Created topic "mr-yan".
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic mr-yan
Topic:mr-yan PartitionCount:1 ReplicationFactor:3 Configs:
Topic: mr-yan Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
- PartitionCount:主题分区数。
- ReplicationFactor:用来设置主题的副本数。
- leader:是负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- replicas:是复制分区日志的节点列表,不管这些节点是leader还是仅仅活着。
- isr:是一组“同步”replicas,是replicas列表的子集,它活着并被指到leader。
进行集群环境下的使用:
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic mr-yan >Hello Kafkas! >Hello Mr.Yan >
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mr-yan Hello Kafkas! Hello Mr.Yan
3.3.3 验证容错性
首先我们停掉一个Kafka的Broker:
[root@iZ2ze4m2ri7irkf6h6n8zoZ ~]# ps -ef|grep server-01.properties
root 19859 28247 1 10:58 pts/3 ../config/server-01.properties
root 23934 16569 0 11:12 pts/11 00:00:00 grep --color=auto server-01.properties
[root@iZ2ze4m2ri7irkf6h6n8zoZ ~]# kill -9 28247
[root@iZ2ze4m2ri7irkf6h6n8zoZ ~]# ps -ef|grep server-01.properties
root 32604 16569 0 11:13 pts/11 00:00:00 grep --color=auto server-01.properties
[root@iZ2ze4m2ri7irkf6h6n8zoZ ~]# cd /usr/local/kafka-2.11/bin/
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic mr-yan
Topic:mr-yan PartitionCount:1 ReplicationFactor:3 Configs:
Topic: mr-yan Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
查看生产者和消费者的变化,并再次使用,发现仍可以进行使用
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic mr-yan >Hello Kafkas! >Hello Mr.Yan >[2021-11-20 11:12:28,881] WARN [Producer clientId=console-producer] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) >Hello Kafkas too! >Hello Mr.Yan too! >
[root@iZ2ze4m2ri7irkf6h6n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mr-yan Hello Kafkas! Hello Mr.Yan [2021-11-20 11:12:28,812] WARN [Consumer clientId=consumer-1, groupId=console-consumer-22158] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) [2021-11-20 11:12:29,165] WARN [Consumer clientId=consumer-1, groupId=console-consumer-22158] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) Hello Kafkas too! Hello Mr.Yan too!
4 小总结
主题,分区,副本的概念
Kafka是根据主题(topic)进行消息的传递,但是又有分区和副本的概念,下面来分别解释下:
分区:kafka对每一条消息的key做一个hashcode运算,然后将得到的数值对分区数量进行模运算就得到了这条消息所在分区的数字。副本:同一分区的几个副本之间保存的是相同的数据,副本之间的关系是“一主多从”,其中的主(leader)则负责对外提供读写操作的服务,而从(follower)则负责与主节点同步数据,当主节点宕机,从节点之间能重新选举leader进行对外服务。
kafka会保证同一个分区内的消息有序,但是不保证主题内的消息有序。
参考:https://kafka.apachecn.org/quickstart.html
总结
到此这篇关于带你玩转Kafka之初步使用的文章就介绍到这了,更多相关Kafka初步使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

kafka生产实践(详解)
1.引言 最近接触到一个APP流量分析的项目,类似于友盟.涉及到几个C端(客户端)高并发的接口,这几个接口主要用于C端数据的提交.在没有任何缓冲的情况下,一个接口涉及到5张表的提交.压测的结果很不理想,主要瓶颈就在与RDS的交互. 一台双核,16G机子,单实例,jdbc最大连接数100,吞吐量竟然只有50TPS. 能想到的改造方案就是引入一层缓冲,让C端接口不与RDS直接交互,很自然就想到了rabbitmq,但是rabbitmq对分布式的支持比较一般,我们的数据体量也比较大,所以我们借鉴了友盟,
-
Linux下Kafka单机安装配置方法(图文)
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topic为单位进行归纳. •将向Kafka topic发布消息的程序成为producers. •将预订topics并消费消息的程序成为consumer. •Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群
-
Java使用kafka发送和生产消息的示例
1. maven依赖包 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.9.0.1</version> </dependency> 2. 生产者代码 package com.lnho.example.kafka; import org.apache.kafka.c
-
Kafka 常用命令行详细介绍及整理
Kafka 常用命令行详细介绍及整理 以下是kafka常用命令行总结: 1.查看topic的详细信息 ./kafka-topics.sh -zookeeper 127.0.0.1:2181 -describe -topic testKJ1 2.为topic增加副本 ./kafka-reassign-partitions.sh -zookeeper 127.0.0.1:2181 -reassignment-json-file json/partitions-to-move.json -execu
-
详解使用docker搭建kafka环境
Requirements 最近学习了下kafka,为方便搭建环境,使用docker进行部署. 需要首先安装docker的环境.要求操作系统是linux的64位系统. docker的安装(适于rpm/deb安装): curl -fsSL https://get.docker.com/ | sh docker-compose的安装: curl -L https://github.com/docker/compose/releases/download/1.7.0/docker-compose-`un
-
带你玩转Kafka之初步使用
目录 前言 1 简单介绍 2 下载安装 3 基本使用 3.1 启动Kafka 3.2 简单测试使用 3.3 搭建多代理集群 3.3.1 开始搭建 3.3.2 使用 3.3.3 验证容错性 4 小总结 总结 前言 官方文档:http://kafka.apache.org/ 中文文档:https://kafka.apachecn.org/ Apache Kafka是分布式发布-订阅消息系统. Apache Kafka与传统消息系统相比,有以下不同: 它被设计为一个分布式系统,易于向外扩展: 它同时为
-
开源 5 款超好用的数据库 GUI 带你玩转 MongoDB、Redis、SQL 数据库(推荐)
工欲善其事必先利其器,想要玩溜数据库,不妨去试试本文安利的 5 款开源的数据库管理工具.除了流行的 SQL 类数据库--MySQL.PostgreSQL 之外,文档型数据库 MongoDB.内存数据库 Redis 的管理工具也在列表之中. MongoDB 图形化的管理工具:Mongood GitHub Star 数 :222 Mongood 是一个 MongoDB 图形化的管理工具.
-
JavaScript一文带你玩转web表单网页
一.前言 前面我们介绍了web网页的快速开发,这次我们讲点更深层次些的,看这面之前建议先看 上篇,之后在食用这篇. 二.正文部分 如图示:点击webapp上面的小三角形点到直到看到jsp位置 我们在创建好了之后这里会有jsp的空单子,我们在这输入的内容,会先反馈到前端,之后再进行 后端数据处理和接收. 第一步:我们先在这输入一些东西如图:其中<h1>内容</h1>这是格式,说明中间的内容是 一个h1 大小的标题,h1--h6标题在逐渐减小,要慎用h1,因为h1比较大 要先点击这个运
-
一文带你玩转Java异常处理
目录 1.前言 2. Exception 类的层次 2.1 Exception 类的层次简介 3. Java 内置异常类 3.1 Java 内置异常类简介 3.2 非检查异常类举例 3.3 检查性异常类表 4. 异常方法 4.1 Throwable 类的主要方法 5. 捕获异常 5.1 捕获异常简介 5.2 try/catch语法如下 5.3 多重捕获块语法说明 6. throws/throw 关键字 6.1 throws/throw 关键字简介 6.2 代码实例 7. finally关键字 7
-
一文带你玩转JavaScript的箭头函数
目录 箭头函数 语法规则 简写规则 常见应用 map filter reduce 箭头函数中的this使用 concat this的查找规则 箭头函数 在ES6中新增了函数的简写方式----箭头函数,箭头函数的出现不仅简化了大量代码,也让代码看起来更加优雅,同时也解决了this指向问题,下面我们就来详细讲解如何玩转箭头函数. 语法规则 1.之前的方法 function foo1(){} var foo2 = function(name,age){ console.log("函数体代码"
-
一文带你玩转MySQL获取时间和格式转换各类操作方法详解
目录 前言 一.SQL时间存储类型 1.date 2.datetime 3.time 4.timestamp 5.varchar/bigint 二.获取时间 1.now() 2.localtime() 3.current_timestamp() 4.localtimestamp() 5.sysdate() 6.curdate() 7.current_time() 8. curtime() 9.current_time() 10. utc_date() 11.utc_time 12.utc_tim
-
C#带你玩扫雷(附源码)
扫雷游戏,大家都应该玩过吧!其实规则也很简单,可是我们想自己实现一个扫雷,我们应该怎么做呢? Step1: 知晓游戏原理 扫雷就是要把所有非地雷的格子揭开即胜利:踩到地雷格子就算失败.游戏主区域由很多个方格组成.使用鼠标左键随机点击一个方格,方格即被打开并显示出方格中的数字:方格中数字则表示其周围的8个方格隐藏了几颗雷:如果点开的格子为空白格,即其周围有0颗雷,则其周围格子自动打开:如果其周围还有空白格,则会引发连锁反应:在你认为有雷的格子上,点击右键即可标记雷:如果一个已打开格子周围所有的雷已
-
酷! 程序员用Python带你玩转冲顶大会
2018年1月3日,王思聪被迫动用自己的微博,为一个诞生不到10天的App打了广告,"每天我都发奖金,今晚9点就发10万".对他而言,这天的微博并非生日宴会,而是战场.王思聪的一则微博开启了"全民竞答"类APP的爆红之路. 一时间,直播巨头们都跟上"王校长"的节奏,"冲顶大会"之外,映客旗下的"芝士超人".今日头条旗下的"百万英雄"和花椒直播旗下的"百万作战"纷纷亮相
-
三分钟带你玩转jQuery.noConflict()
jQuery是目前使用最广泛的前端框架之一,有大量的第三方库和插件基于它开发.为了避免全局命名空间污染,jQuery提供了jQuery.noConflict()方法解决变量冲突.这个方法,毫无疑问,非常有效.遗憾的是,jQuery的官方文档对该方法的描述不够清晰,许多开发者并不清楚当他们调用jQuery.noConflict()时,究竟发生了什么,从而导致在使用时出现了许多问题.尽管如此,jQuery.noConflict()背后实现原理依然值得Web开发者学习掌握,成为解决类似全局命名空间污染
-
详解Android中的NestedScrolling机制带你玩转嵌套滑动
一.概述 Android在support.v4包中为大家提供了两个非常神奇的类: NestedScrollingParent NestedScrollingChild 如果你从未听说过这两个类,没关系,听我慢慢介绍,你就明白这两个类可以用来干嘛了.相信大家都见识过或者使用过CoordinatorLayout,通过这个类可以非常便利的帮助我们完成一些炫丽的效果,例如下面这样的: 这样的效果就非常适合使用NestedScrolling机制去完成,并且CoordinatorLayout背后其实也是利用