Python机器学习NLP自然语言处理Word2vec电影影评建模
目录
- 概述
- 词向量
- 词向量维度
- 代码实现
- 预处理
- 主程序
概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

词向量
我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量.
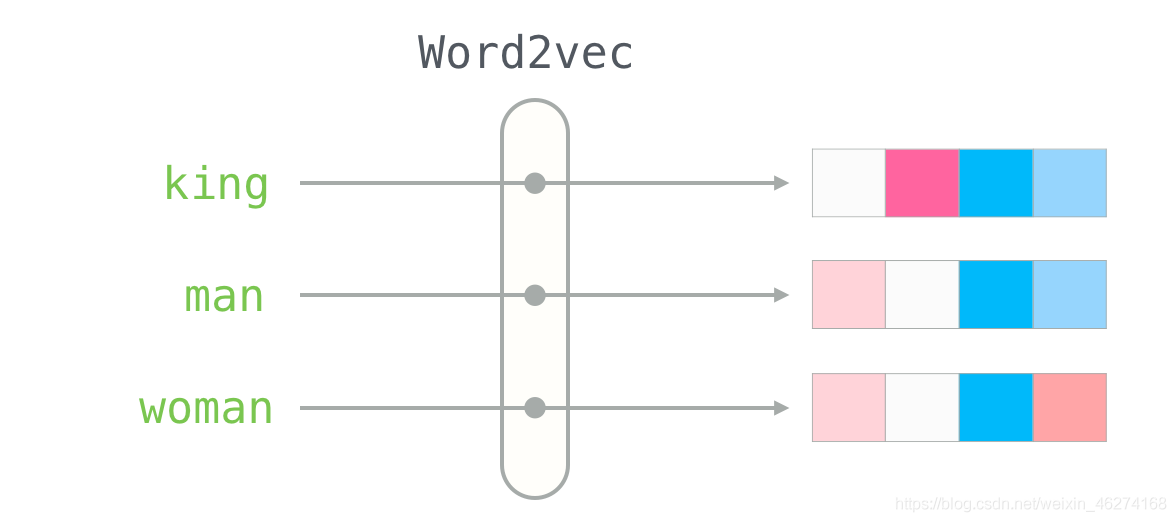
当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量我们就可以使用不同方法来计算相似度.

那我们如何来描述语言的特征呢? 我们把语言分割成一个个词, 然后在词的层面上构建特征.
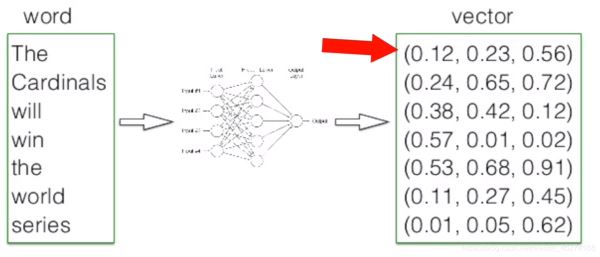
词向量维度
词向量的维度越高, 其所能提供的信息也就越多, 计算结果的可靠性就更值得信赖.
50 维的词向量:

用热度图表示一下:


从上图我们可以看出, 相似的词在特征表达中比较相似. 由此也可以证明词的特征是有意义的.
代码实现
预处理
import numpy as np
import pandas as pd
import itertools
import re
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
import nltk
# 停用词
stop_words = pd.read_csv("data/stopwords.txt", index_col=False, quoting=3, sep="\n", names=["stop_words"])
stop_words = [word.strip() for word in stop_words["stop_words"].values]
def load_train_data():
"""读取训练数据"""
# 语料
data = pd.read_csv("data/labeledTrainData.tsv", sep="\t", escapechar="\\")
print(data[:5])
print("训练评论数量:", len(data)) # 25,000
return data
def load_test_data():
# 语料
data = pd.read_csv("data/unlabeledTrainData.tsv", sep="\t", escapechar="\\")
print("测试评论数量:", len(data)) # 50,000
return data
def pre_process(text):
# 去除网页链接
text = BeautifulSoup(text, "html.parser").get_text()
# 去除标点
text = re.sub("[^a-zA-Z]", " ", text)
# 分词
words = text.lower().split()
# 去除停用词
words = [w for w in words if w not in stop_words]
return " ".join(words)
def split_train_data():
# 读取文件
data = pd.read_csv("data/train.csv")
print(data.head())
# 抽取bag of words特征
vec = CountVectorizer(max_features=5000)
# 拟合
vec.fit(data["review"])
# 转换
train_data_features = vec.transform(data["review"]).toarray()
print(train_data_features.shape)
# 词袋
print(vec.get_feature_names())
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(train_data_features, data["sentiment"], test_size=0.2,
random_state=0)
return X_train, X_test, y_train, y_test
def test():
# 读取测试数据
data = pd.read_csv("data/test.csv")
print(data.head())
tokenizer = nltk.data.load("tokenizers/punkt/english.pickle")
# 分词
def split_sentences(review):
raw_sentences = tokenizer.tokenize(review.strip())
return sentences
sentences = sum(data["review"][:10].apply(split_sentences), [])
def visualize(cm, classes, title="Confusion matrix", cmap=plt.cm.Blues):
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max()
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j], horizontalalignment="center", color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.show()
if __name__ == '__main__':
# # 处理训练数据
# train_data = load_train_data()
# train_data["review"] = train_data["review"].apply(pre_process)
# print(train_data.head())
#
# # 保存
# train_data.to_csv("data/train.csv")
# # 处理训练数据
# test_data = load_test_data()
# test_data["review"] = test_data["review"].apply(pre_process)
# print( test_data.head())
#
# # 保存
# test_data.to_csv("data/test.csv")
split_train_data()
主程序
import pandas as pd
import nltk
from gensim.models.word2vec import Word2Vec
def pre_process():
"""预处理"""
# 读取测试数据
data = pd.read_csv("data/test.csv")
print(data.head())
# 存放结果
result = []
# 分词
for line in data["review"]:
result.append(nltk.word_tokenize(line))
return result
def main():
# 获取分词语料
word_list = pre_process()
# 设定词向量训练的参数
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
# 创建w2c模型
model = Word2Vec(sentences=word_list, workers=num_workers,
vector_size=num_features, min_count=min_word_count,
window=context)
# 保存模型
model.save(model_name)
def test():
# 加载模型
model = Word2Vec.load("300features_40minwords_10context.model")
# 不匹配
match = model.wv.doesnt_match(['man','woman','child','kitchen'])
print(match)
# 最相似
print(model.wv.most_similar("boy"))
print(model.wv.most_similar("bad"))
if __name__ == '__main__':
test()
输出结果:
2021-09-16 20:36:40.791181: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
Unnamed: 0 id sentiment review
0 0 5814_8 1 stuff moment mj ve started listening music wat...
1 1 2381_9 1 classic war worlds timothy hines entertaining ...
2 2 7759_3 0 film starts manager nicholas bell investors ro...
3 3 3630_4 0 assumed praised film filmed opera didn read do...
4 4 9495_8 1 superbly trashy wondrously unpretentious explo...
73423
[[15958 623 12368 4459 622 835 30 152 2097 2408 35364 57143
892 2997 766 42223 967 266 25276 157 108 696 1631 198
2576 9850 3745 27 52 3789 9503 696 526 52 354 862
474 38 2 101 11027 696 6456 22390 969 5873 5376 4044
623 1401 2069 718 618 92 96 138 1345 714 96 18
123 1770 518 3314 354 983 1888 520 83 73 983 2
28 28635 1044 2054 401 1071 85 8565 8957 7226 804 46
224 447 2113 2691 5742 10 5 3217 943 5045 980 373
28 873 438 389 41 23 19 56 122 9 253 27176
2149 19 90 57144 53 4874 696 6558 136 2067 10682 48
518 1482 9 3668 1587 3786 2 110 10 506 25150 20744
340 33 316 17 4824 3892 978 14 10150 2596 766 42223
5082 4784 700 198 6276 5254 700 198 2334 696 20879 5
86 30 2 583 2872 30601 30 86 28 83 73 32
96 18 2 224 708 30 167 7 3791 216 45 513
2 2310 513 1860 4536 1925 414 1321 578 7434 851 696
997 5354 57145 162 30 2 91 1839]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 357 684
28 3027 10371 5801 20987 21481 19800 1 3027 10371 21481 19800
1719 204 49 168 250 7355 1547 374 401 5415 24 1719
24 49 168 7355 1547 3610 21481 19800 123 204 49 168
1102 1547 656 213 5432 5183 61 4 66166 20 36 56
7 5183 2025 116 5031 11 45 782]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 2189 1 586
2189 15 1855 615 400 5394 3797 23866 2892 481 2892 810
22020 17820 1 741 231 20 746 2028 1040 6089 816 5555
41772 1762 26 811 288 8 796 45]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 85 310 1734 78 1906 78 1906 1412 1985
78 7644 1412 244 9287 7092 6374 2584 6183 3795 3080 1288
2217 3534 6005 4851 1543 762 1797 26144 699 237 6745 7
1288 1415 9003 5623 237 1669 17987 874 421 234 1278 347
9287 1609 7100 1065 75 9800 3344 76 5021 47 380 3015
14366 6523 1396 851 22330 3465 20861 7106 6374 340 60 19035
3089 5081 3 7 1695 10735 3582 92 6374 176 8348 60
1491 11540 28826 1847 464 4099 22 3561 51 22 1538 1027
38926 2195 1966 3089 33 19894 287 142 6374 184 37 4025
67 325 37 421 549 21976 28 7744 2466 31533 27 2836
1339 6374 14805 1670 4666 60 33 12]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 27 52
4639 9 5774 1545 8575 855 10463 2688 21019 1542 1701 653
9765 9 189 706 2212 18342 566 437 2639 4311 4504 26110
307 496 893 317 1 27 52 587]]
[[0. 1.]
[0. 1.]
[0. 1.]
[1. 0.]
[0. 1.]]
2021-09-16 20:36:46.488438: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-09-16 20:36:46.489070: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcuda.so.1'; dlerror: /usr/lib/x86_64-linux-gnu/libcuda.so.1: file too short; LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/cuda/lib64/:/usr/lib/x86_64-linux-gnu
2021-09-16 20:36:46.489097: W tensorflow/stream_executor/cuda/cuda_driver.cc:326] failed call to cuInit: UNKNOWN ERROR (303)
2021-09-16 20:36:46.489128: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (313c6f2d15e2): /proc/driver/nvidia/version does not exist
2021-09-16 20:36:46.489488: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX512F
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-09-16 20:36:46.493241: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 200) 14684800
_________________________________________________________________
lstm (LSTM) (None, 200) 320800
_________________________________________________________________
dropout (Dropout) (None, 200) 0
_________________________________________________________________
dense (Dense) (None, 64) 12864
_________________________________________________________________
dense_1 (Dense) (None, 2) 130
=================================================================
Total params: 15,018,594
Trainable params: 15,018,594
Non-trainable params: 0
_________________________________________________________________
None
2021-09-16 20:36:46.792534: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2021-09-16 20:36:46.830442: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2300000000 Hz
Epoch 1/2
313/313 [==============================] - 101s 315ms/step - loss: 0.5581 - accuracy: 0.7229 - val_loss: 0.3703 - val_accuracy: 0.8486
Epoch 2/2
313/313 [==============================] - 98s 312ms/step - loss: 0.2174 - accuracy: 0.9195 - val_loss: 0.3016 - val_accuracy: 0.8822
以上就是Python机器学习NLP自然语言处理Word2vec电影影评建模的详细内容,更多关于NLP自然语言处理Word2vec影评建模的资料请关注我们其它相关文章!
相关推荐
-

Python机器学习NLP自然语言处理Word2vec电影影评建模
目录 概述 词向量 词向量维度 代码实现 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量. 当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量
-
Python机器学习NLP自然语言处理基本操作电影影评分析
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天天气真好&
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.
-
Python机器学习NLP自然语言处理基本操作家暴归类
目录 概述 数据介绍 词频统计 朴素贝叶斯 代码实现 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 数据介绍 该数据是家庭暴力的一份司法数据.分为 4 个不同类别: 报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打. 今天我们就要运用我们前几次学到的知识, 来实现一个 NLP 分类问题. 词频统计 CountVectorizer是一个文本特征提取的方
-
Python机器学习NLP自然语言处理基本操作词袋模型
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词袋模型 词袋模型 (Bag of Words Model) 能帮助我们把一个句子转换为向量表示. 词袋模型把文本看作是无序的词汇集合, 把每一单词都进行统计. 向量化 词袋模型首先会进行分词, 在分词之后. 通过通过统计在每个词在文本中出现的次数. 我们就可以得到该文本基于词语的特征, 如果将各个文本样本的这些词与对应的词频放在一起
-
Python机器学习NLP自然语言处理基本操作关键词
目录 概述 关键词 TF-IDF 关键词提取 TF IDF TF-IDF jieba TF-IDF 关键词抽取 jieba 词性 不带关键词权重 附带关键词权重 TextRank 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 关键词 关键词 (keywords), 即关键词语. 关键词能描述文章的本质, 在文献检索, 自动文摘, 文本聚类 / 分类等方面有着重要的应用. 关键词抽
-
Python机器学习NLP自然语言处理基本操作之精确分词
目录 概述 分词器 jieba 安装 精确分词 全模式 搜索引擎模式 获取词性 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 分词器 jieba jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viter
-
Python机器学习NLP自然语言处理基本操作新闻分类
目录 概述 TF-IDF 关键词提取 TF IDF TF-IDF TfidfVectorizer 数据介绍 代码实现 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. TF-IDF 关键词提取 TF-IDF (Term Frequency-Inverse Document Frequency), 即词频-逆文件频率是一种用于信息检索与数据挖掘的常用加权技术. TF-IDF 可以帮助我
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习NLP自然语言处理基本操作之Seq2seq的用法
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. Seq2seq Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列. Seq2seq 的使用领域: 机器翻译: Encoder-Decoder 的最经典应用 文本摘要: 输入是一段文本序列, 输出是这段文本