scrapy+scrapyd+gerapy 爬虫调度框架超详细教程
目录
- 一、scrapy
- 1.1 概述
- 1.2 构成
- 1.3 安装和使用
- 二、scrapyd
- 2.1 简介
- 2.2 安装和使用
- 三、gerapy
- 3.1 简介
- 3.2 安装使用
- 四、scrapy+scrapyd+gerapy的结合使用
- 4.1 创建scrapy项目
- 4.2 部署打包scrapy项目
- 4.3 运行
- 五、填坑
- 5.1 运行scrapy爬虫报错
- 5.2 scrapyd 运行 scrapy 报错
一、scrapy
1.1 概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 后台也应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持.
1.2 构成
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
1.3 安装和使用
安装
pip install scrapy(或pip3 install scrapy)
使用
创建新项目:scrapy startproject 项目名
创建新爬虫:scrapy genspider 爬虫名 域名
启动爬虫: scrapy crawl 爬虫名
二、scrapyd
2.1 简介
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
2.2 安装和使用
安装
pip install scrapyd(或pip3 install scrapyd) pip install scrapyd-client(或pip3 install scrapyd-client)
文件配置
vim /usr/local/python3/lib/python3.7/site-packages/scrapyd/default_scrapyd.conf
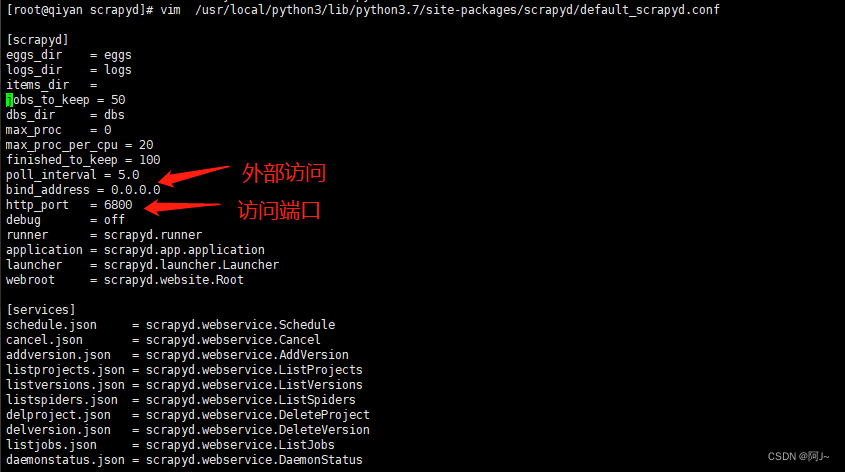
启动
scrapyd

访问 ip:6800,出现此页面则启动成功

三、gerapy
3.1 简介
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 方便地控制爬虫运行
- 直观地查看爬虫状态
- 实时地查看爬取结果
- 简单地实现项目部署
- 统一地实现主机管理
- 轻松地编写爬虫代码
3.2 安装使用
安装
pip install gerapy(或pip3 install gerapy)

安装完后先建立软链接
ln -s /usr/local/python3/bin/gerapy /usr/bin/gerapy
初始化
gerapy init

初始化数据库
cd gerapy gerapy migrate
报错sqllite 版本过低

解决办法:升级sqllite
下载 wget https://www.sqlite.org/2019/sqlite-autoconf-3300000.tar.gz --no-check-certificate tar -zxvf sqlite-autoconf-3300000.tar.gz
安装 mkdir /opt/sqlite cd sqlite-autoconf-3300000 ./configure --prefix=/opt/sqlite make && make install
建立软连接 mv /usr/bin/sqlite3 /usr/bin/sqlite3_old ln -s /opt/sqlite/bin/sqlite3 /usr/bin/sqlite3 echo “/usr/local/lib” > /etc/ld.so.conf.d/sqlite3.conf ldconfig vim ~/.bashrc 添加 export LD_LIBRARY_PATH=“/usr/local/lib” source ~/.bashrc
查看当前sqlite3的版本 sqlite3 --version

重新初始化gerapy 数据库

配置账密
gerapy createsuperuser
启动gerapy
gerapy runserver gerapy runserver 0.0.0.0:9000 # 外部访问 9000端口启动

由于没有启动scrapy 这里的主机未0

启动scrapyd后,配置scrapyd的主机信息

配置成功后就会加入到主机列表里

四、scrapy+scrapyd+gerapy的结合使用
4.1 创建scrapy项目
进到gerapy的项目目录
cd ~/gerapy/projects/
然后新建一个scrapy项目
scrapy startproject gerapy_test scrapy genspider baidu_test www.baidu.com
修改scrapy.cfg 如下

在使用scrapyd-deploy 上传到scrapyd,先建立软连接再上传
ln -s /usr/local/python3/bin/scrapyd-deploy /usr/bin/scrapyd-deploy scrapyd-deploy app -p gerapy_test

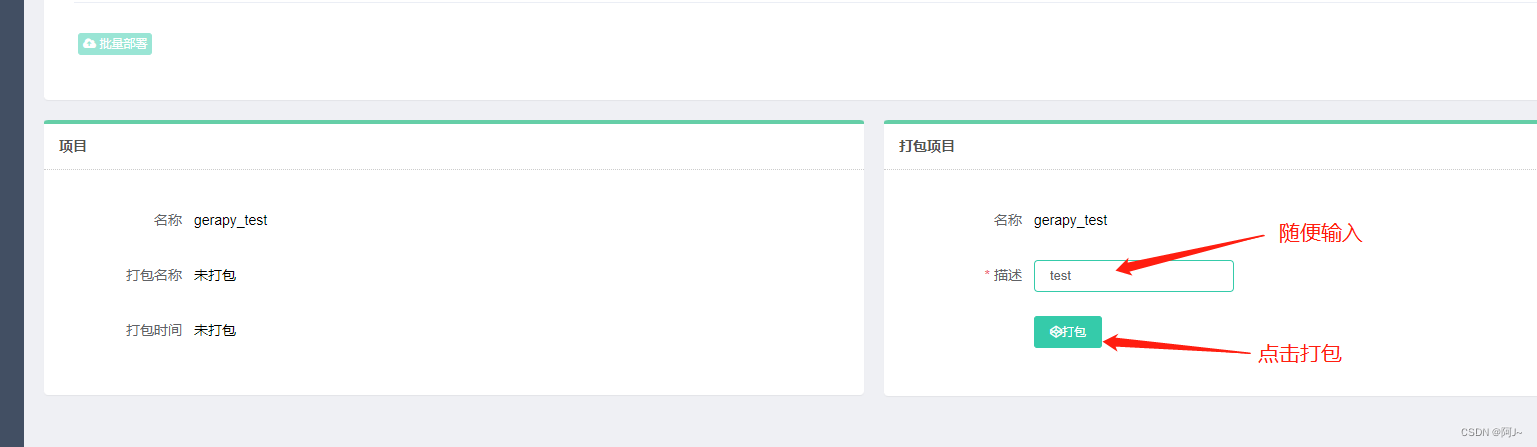
4.2 部署打包scrapy项目
然后再gerapy页面上可以看到我们新建的项目,再打包一下



运行之前还需修改下scrapy代码
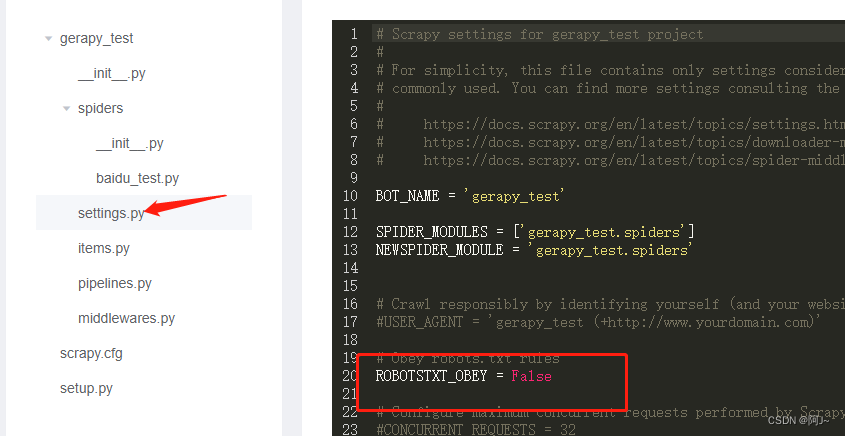

修改完后再运行代码

4.3 运行
运行成功,本次的部署就ok了!

五、填坑
5.1 运行scrapy爬虫报错

解决办法:修改lzma源代码如下
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties

5.2 scrapyd 运行 scrapy 报错

解决办法:降低scrapy版本 pip3 install scrapy==2.5.1
到此这篇关于scrapy+scrapyd+gerapy 爬虫调度框架超详细教程的文章就介绍到这了,更多相关scrapy+scrapyd+gerapy 爬虫调度框架内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
快速部署 Scrapy项目scrapyd的详细流程
快速部署 Scrapy项目 scrapyd 给服务端 install scrapyd pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple 运行 scrapyd 修改配置项 , 以便远程访问 使用Ctrl +c 停止 上一步的运行的scrapyd 在要运行scrapyd 命令的路径下,新建文件scrapyd.cnf 文件 输入以下内容 [scrapyd] # 网页和Json服务监听的IP地址,默认为127.0.0.1(只
-
Python爬虫Scrapy框架IP代理的配置与调试
目录 代理ip的逻辑在哪里 如何配置动态的代理ip 在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬们的解释不一样,因为我是从Java 的角度看Python.这样也便于Java开发人员阅读理解. 代理ip的逻辑在哪里 一个scrapy 的项目结构是这样的 scrapydownloadertest # 项目文件夹 │ ite
-
scrapyd schedule.json setting 传入多个值问题
使用案例: import requests adder='http://127.0.0.1:6800' data = { 'project':'v1', 'version':'12379', 'setting':['ROBOTSTXT_OBEY=True','CONCURRENT_REQUESTS=32'] } resp = requests.post(adder,data=data) 问题解决思路: 版本1.2文档中: ◦setting (string, optional) - a Scrap
-
scrapy+scrapyd+gerapy 爬虫调度框架超详细教程
目录 一.scrapy 1.1 概述 1.2 构成 1.3 安装和使用 二.scrapyd 2.1 简介 2.2 安装和使用 三.gerapy 3.1 简介 3.2 安装使用 四.scrapy+scrapyd+gerapy的结合使用 4.1 创建scrapy项目 4.2 部署打包scrapy项目 4.3 运行 五.填坑 5.1 运行scrapy爬虫报错 5.2 scrapyd 运行 scrapy 报错 一.scrapy 1.1 概述 Scrapy,Python开发的一个快速.高层次的屏幕抓取和w
-
python爬虫scrapy基本使用超详细教程
一.介绍 官方文档:中文2.3版本 下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的. 二.基本使用 2.1 环境安装 1.linux和mac操作系统: pip install scrapy 2.windows系统: 先安装wheel:pip install wheel 下载twisted:下载地址 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd
-
scrapy处理python爬虫调度详解
学习了简单的知识点,就会想要向有难度的问题挑战,这里必须要夸一夸小伙伴们.不过我们今天不需要做什么程序的测试,只用简单的两个代码对比,小伙伴们就能在其中体会两者的不同和难易程度.scrapy能否适合处理python爬虫调度的问题,小编直接说出答案小伙伴们也不能马上信服,下面就让我们在示例中找寻答案吧. 总的来说,需要使用代码来爬一些数据的大概分为两类人: 非程序员,需要爬一些数据来做毕业设计.市场调研等等,他们可能连 Python 都不是很熟: 程序员,需要设计大规模.分布式.高稳定性的爬虫系统
-
Java集合框架超详细小结
目录 一:Collection集合 1.1集合概述: 1.2集合架构 1.3Collection集合常用方法 二:迭代器Iterator 2.1Iterator接口 2.2Iterator的实现原理: 2.3增强for() 2.4迭代器注意事项 三:泛型 3.1泛型概述 3.2泛型的优缺点 3.3泛型的定义与使用 泛型方法 泛型接口 3.4泛型的通配符 通配符高级使用-----受限泛型 四:Java常见数据结构 4.1栈 4.2队列 4.3数组 4.4链表 4.5红黑树 五:List集合体系 5
-
pytest测试框架+allure超详细教程
目录 1.测试识别和运行 2.参数化 3.测试报告美化-allure 1.测试识别和运行 文件识别: 在给定的目录中,搜索所有test_.py或者_test.py文件 用例识别: Test*类包含的所有test_*的方法(测试类不能有__init__方法) 不在类中的所有test_*方法 pytest也能执行unit test写的用例和方法 运行方式1.pycharm页面修改默认的测试运行方式settings页面,输入pytest,修改Default test runner 2.右键执行pyth
-
Springboot启动扩展点超详细教程小结
1.背景 Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片.Springboot更是封装了Spring,遵循约定大于配置,加上自动装配的机制.很多时候我们只要引用了一个依赖,几乎是零配置就能完成一个功能的装配. 我非常喜欢这种自动装配的机制,所以在自己开发中间件和公共依赖工具的时候也会用到这个特性.让使用者以最小的代价接入.想要把自动装配玩的转,就必须要了解spring对于bean的构造生命周期以及各个扩展接口.当然了解了bean
-
Windows下PyCharm配置Anaconda环境(超详细教程)
首先来明确一下Python.PyCharm和Anaconda的关系 1.Python是一种解释型.面向对象.动态数据类型的高级程序设计语言. 虽然Python3.5自带了一个解释器IDLE用来执行.py脚本,但是却不利于我们书写调试大量的代码.常见的是用Notepade++写完脚本,再用idle来执行,但却不便于调试.这时候就出现了PyCharm等IDE,来帮助我们调试开发. 2.PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调
-
SpringBoot整合MyBatis超详细教程
1.整合MyBatis操作 前面一篇提到了SpringBoot整合基础的数据源JDBC.Druid操作,实际项目中更常用的还是MyBatis框架,而SpringBoot整合MyBatis进行CRUD也非常方便. 下面从配置模式.注解模式.混合模式三个方面进行说明MyBatis与SpringBoot的整合. 1.1.配置模式 MyBatis配置模式是指使用mybatis配置文件的方式与SpringBoot进行整合,相对应的就有mybatis-config.xml(用于配置驼峰命名,也可以省略这个文
-
spring boot actuator监控超详细教程
spring boot actuator介绍 Spring Boot包含许多其他功能,可帮助您在将应用程序推送到生产环境时监视和管理应用程序. 您可以选择使用HTTP端点或JMX来管理和监视应用程序. 审核,运行状况和指标收集也可以自动应用于您的应用程序. 总之Spring Boot Actuator就是一款可以帮助你监控系统数据的框架,其可以监控很多很多的系统数据,它有对应用系统的自省和监控的集成功能,可以查看应用配置的详细信息,如: 显示应用程序员的Health健康信息 显示Info应用信息
-
BootstrapValidator超详细教程(推荐)
一.引入必要文件 下载地址:(https://github.com/nghuuphuoc/bootstrapvalidator/archive/v0.4.5.zip) <link rel="stylesheet" href="/path/to/bootstrap/css/bootstrap.css"/> <link rel="stylesheet" href="/path/to/dist/css/bootstrapVa