Pandas替换及部分替换(replace)实现流程详解
在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法。

源数据
1、替换全部或者某一行
replace的基本结构是:df.replace(to_replace, value) 前面是需要替换的值,后面是替换后的值。
例如我们要将南岸改为城区:

将南岸改为城区
这样Python就会搜索整个DataFrame并将文档中所有的南岸替换成了城区(要注意这样的操作并没有改变文档的源数据,要改变源数据需要使用inplace = True)。

使用inplace = True更改源数据
由于南岸只有城市一列具有相同值,使用起来比较方便。
但是如果我们要改变表1Lon里的某个数据,而不改变Longitude的数据要怎么做呢?

改变指定的列的数据
所以只想替换部分数据的时候并且要写入源数据就需要指定inplace。
在上面的操作只改变了表1Lon的数据,其它列的数据并没有被替换,而且在替换后的结果不需要我们再和源数据进行合并操作,可以直接体现在源数据中。
2、替换指定的某个或指定的多个数值(用字典的形式)

只改变指定的值
这个很好理解,就是字典里的建作为原值,字典里的值作为替换的新值。
当然,我们也可是使用列表的形式进行替换:df.replace(['A','29.54'],['B',100])

用列表的形式进行替换
还有如果想要替换的新值是一样的话,我们还可以这样做:
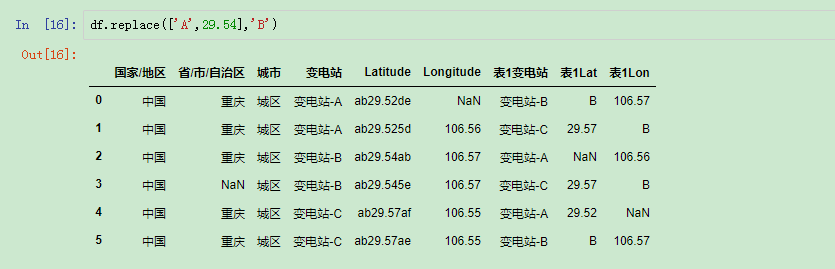
替换的新值一样时
部分替换和替换某个值结合使用的话就可以替换单个列的数值:

替换单个列的数值
3、使用正则表达式替换
正则表达式很强大,能够让我们实现一次替换很多很多个不同的值:

源数据

正则表达式没有指定regex =True
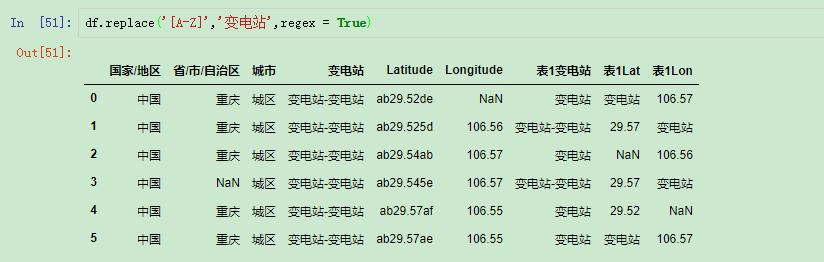
正则表达式指定regex =True
使用正则表达式的时候记得后面加 regex=True参数。
有图中我们可以看到只要包含有大写的英文字母的数据都被替换了,如果我们要写入源数据还需要指定inpla = True。

指定列替换数据
当需要将缺失值替换掉的时候,我们可以考虑直接只用fillna(),功能更强大,这个前面已经有说过了。
在某些情况下,如果我们只需要某个数据的部分内容,我们该怎么操作呢?
比如要把变电站都改为transformer_substation,或者是把Latitude列的前面的ab改为AB:

指定列更改替换部分字符

指定列更改替换部分字符
需要注意的时更好指定列的时候,使用str.replace时不能使用inplace = True参数,因此需要改成赋值,赋值的时候不要忘了是列的赋值而不是整个表格的赋值。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
对python pandas中 inplace 参数的理解
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改 inplace = True:不创建新的对象,直接对原始对象进行修改: inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果. 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似. 例: inplace=True情况: import pandas as pd import numpy as np df=pd.DataFrame(np.rand
-
pandas.DataFrame.drop_duplicates 用法介绍
如下所示: DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据 keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除:last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
对pandas replace函数的使用方法小结
语法:replace(self, to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None) 使用方法如下: import numpy as np import pandas as pd df = pd.read_csv('emp.csv') df #Series对象值替换 s = df.iloc[2]#获取行索引为2数据 #单值替换 s.replace('?',np.
-
用pandas划分数据集实现训练集和测试集
1.使用model_select子模块中的train_test_split函数进行划分 数据:使用kaggle上Titanic数据集 划分方法:随机划分 # 导入pandas模块,sklearn中model_select模块 import pandas as pd from sklearn.model_select import train_test_split # 读取数据 data = pd.read_csv('.../titanic_dataset/train.csv') # 将特征划分到
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');
-
pandas to_excel 添加颜色操作
我就废话不多说了,大家还是直接看代码吧~ import pandas as pd import numpy as np columns = [['A', 'A', 'B', 'B', 'C'], ['a', 'b', 'c', 'd', 'e']] # 创建形状为(10,5) 的DataFrame 并设置二级标题 demo_df = pd.DataFrame(np.arange(50).reshape(10, 5), columns=columns) print(demo_df) def sty
-

MongoDB中数据的替换方法实现类Replace()函数功能详解
近日接到一个开发需求,因业务调整,需要DBA协助,将MongoDB数据库中某集合的进行替换.例如我们需要将集合A中B字段中,有关<美好>的字符替换为 <非常美好>.个人感觉这个需求如果是在SQL Server 或MySQL 数据库上处理是小菜一碟,如果是针对MongoDB数据,可能要费神了. 1.常见关系数据数据库中的替换函数 在SQL Server数据库中,我们用Replace函数来实现字符的替换. 语法 REPLACE ( ''string_replace1'' , ''str
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
Vue登录功能的实现流程详解
目录 Vue项目中实现登录大致思路 安装插件 创建store 封装axios qs vue 插件 api.js的作用 路由拦截 登录页面实际使用 Vue项目中实现登录大致思路 1.第一次登录的时候,前端调后端的登陆接口,发送用户名和密码 2.后端收到请求,验证用户名和密码,验证成功,就给前端返回一个token 3.前端拿到token,将token存储到localStorage和vuex中,并跳转路由页面 4.前端每次跳转路由,就判断 localStroage 中有无 token ,没有就跳转到登
-
react组件的创建与更新实现流程详解
目录 React源码执行流程图 legacyRenderSubtreeIntoContainer legacyCreateRootFromDOMContainer createLegacyRoot ReactDOMBlockingRoot createRootImpl createContainer createFiberRoot createHostRootFiber createFiber updateContainer 总结 这一章节就来讲讲ReactDOM.render()方法的内部实现
-
js中substr,substring,indexOf,lastIndexOf,split,replace的用法详解
indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置. lastIndexOf() 方法可返回一个指定的字符串值最后出现的位置,在一个字符串中的指定位置从后向前搜索. substring() 方法用于提取字符串中介于两个指定下标之间的字符. substr(start,length)表示从start位置开始,截取length长度的字符串 split 将一个字符串分割为子字符串,然后将结果作为字符串数组返回 replace 用于在字符串中用一些字符替换另一些字符,或替换一个与正则
-
对pandas通过索引提取dataframe的行方法详解
一.假设有这样一个原始dataframe 二.提取索引 (已经做了一些操作将Age为NaN的行提取出来并合并为一个dataframe,这里提取的是该dataframe的索引,道理和操作是相似的,提取的代码没有贴上去是为了不显得太繁杂让读者看着繁琐) >>> index = unknown_age_Mr.index.tolist() #记得转换为list格式 三.提取索引对应的原始dataframe的行 使用iloc函数将数据块提取出 >>> age_df.iloc[in
-
对angularJs中自定义指令replace的属性详解
如下所示: <div ng-app="module"> <div my-exam></div> </div> <script> var m = angular.module('module', []); m.directive('myExam', [function () { return { restrict: 'EA', template: '<h1>欢迎浏览泠泠在路上</h1>', /*1.rep
-
pandas中read_csv、rolling、expanding用法详解
如下所示: import pandas as pd from pandas import DataFrame series = pd.read_csv('daily-min-temperatures.csv',header=0, index_col=0, parse_dates=True,squeeze=True) temps = DataFrame(series.values) width = 3 shifted = temps.shift(width-1) print(shifted) wi
-
微信小程序访问mysql数据库流程详解
目录 1 开通云上的mysql 2 创建自定义连接器 3 创建云函数 4 安装依赖 5 出参映射 6 在小程序中使用连接器 总结 1 开通云上的mysql 经过询价,我发现阿里云的数据库是比较便宜的,新人购买非常划算.对于爱学习的博主来说,果断购买一个. 按照操作指引购买后,云会帮你创建一系列的环境,在控制台就可以看到属于自己的实例 点击操作列上的管理,就可以创建我们自己的数据库.配置的步骤是先创建数据库的账号 然后创建一个数据库 都设置好之后就可以登录数据库,创建表,加数据了 刚创建好的数据库
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False