scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。
如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?
方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的process_request()以及Downloader都跳过了。
相关的配置:
1、scrapy环境中安装selenium:pip install selenium
2、确保python环境中有phantomJS(无头浏览器)
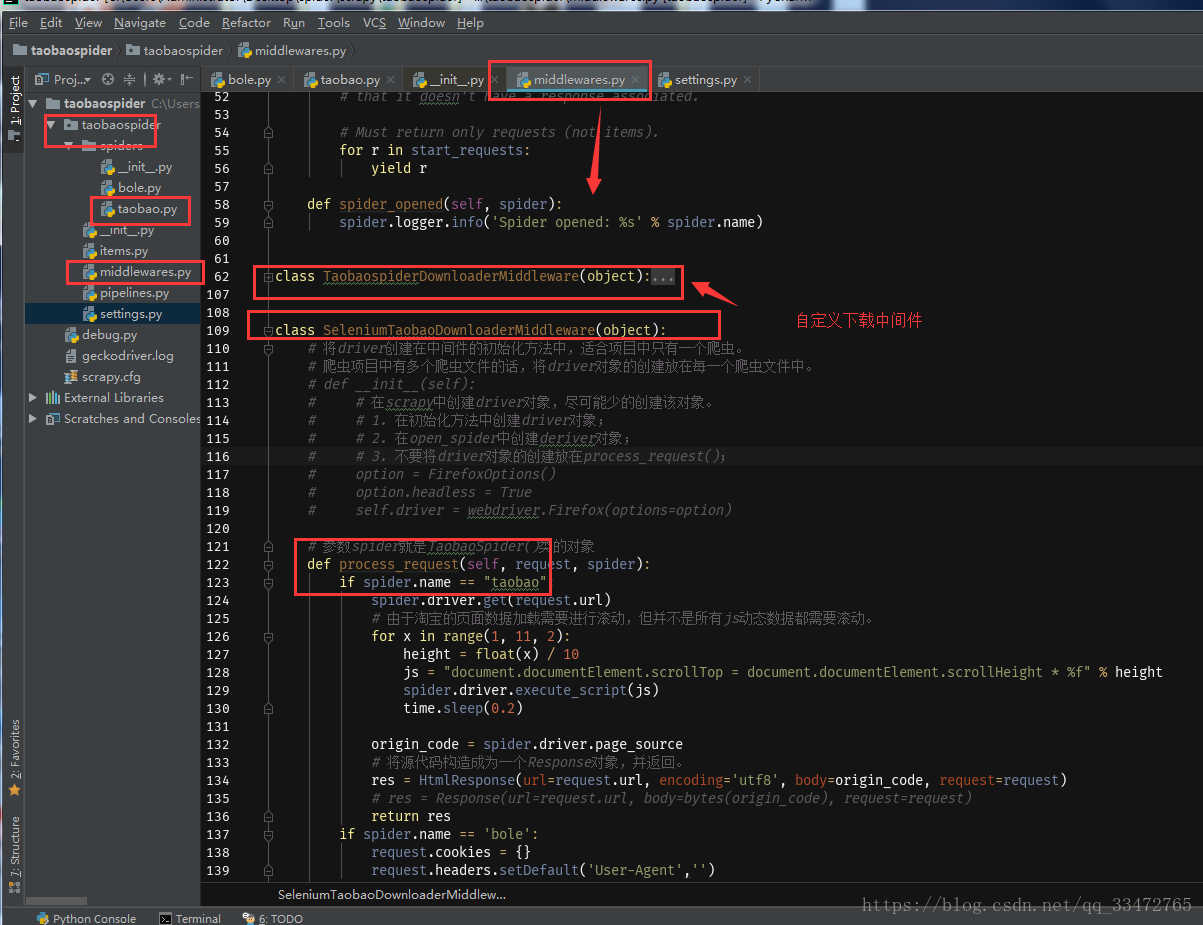
对于selenium的主要操作是下载中间件部分如下图:
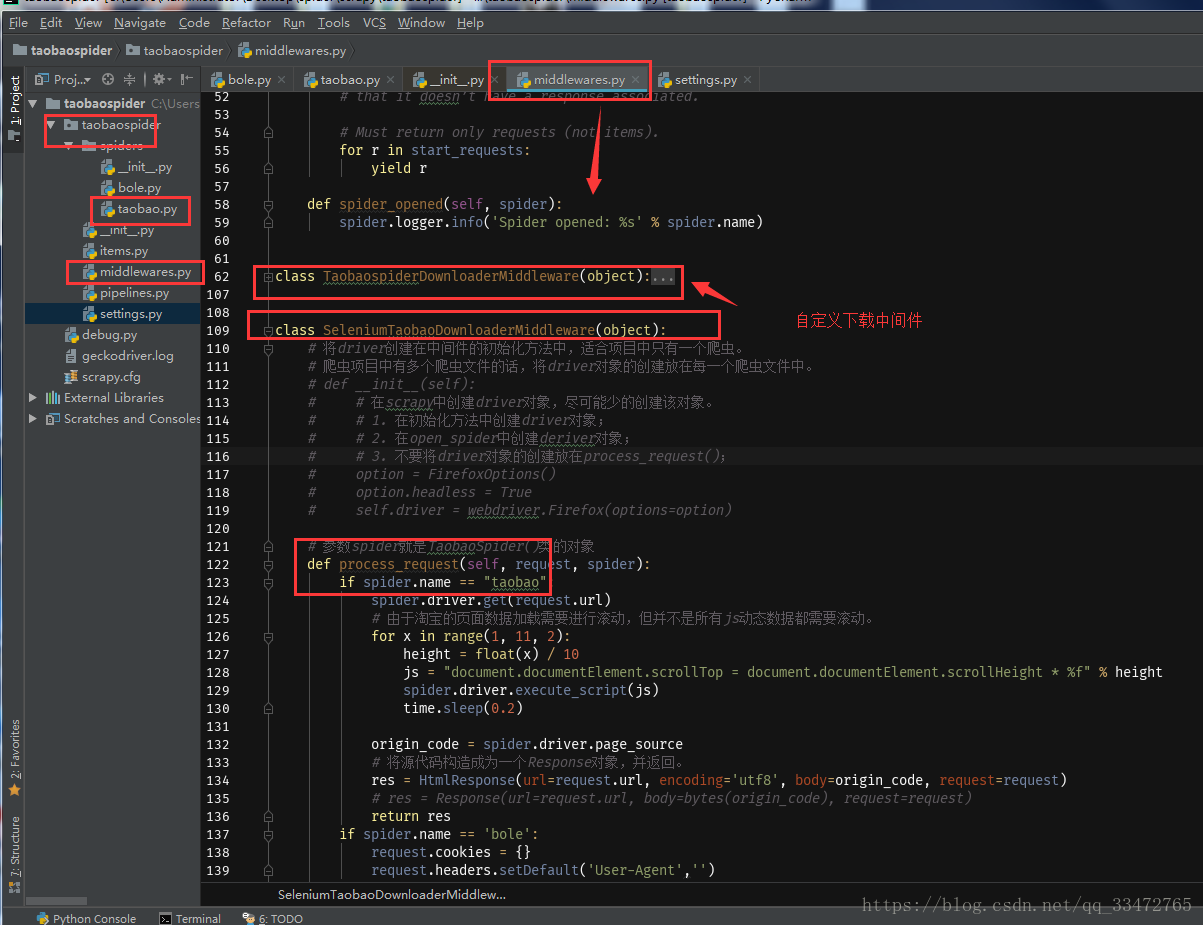
代码如下
middlewares.py代码:
注意:自定义下载中间件,采用selenium的方式!!
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium import webdriver
from selenium.webdriver import FirefoxOptions
from scrapy.http import HtmlResponse, Response
import time
class TaobaospiderSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn't have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class TaobaospiderDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
*********************下面是相应是自定义的下载中间件的替换代码**************************
class SeleniumTaobaoDownloaderMiddleware(object):
# 将driver创建在中间件的初始化方法中,适合项目中只有一个爬虫。
# 爬虫项目中有多个爬虫文件的话,将driver对象的创建放在每一个爬虫文件中。
# def __init__(self):
# # 在scrapy中创建driver对象,尽可能少的创建该对象。
# # 1. 在初始化方法中创建driver对象;
# # 2. 在open_spider中创建deriver对象;
# # 3. 不要将driver对象的创建放在process_request();
# option = FirefoxOptions()
# option.headless = True
# self.driver = webdriver.Firefox(options=option)
# 参数spider就是TaobaoSpider()类的对象
def process_request(self, request, spider):
if spider.name == "taobao":
spider.driver.get(request.url)
# 由于淘宝的页面数据加载需要进行滚动,但并不是所有js动态数据都需要滚动。
for x in range(1, 11, 2):
height = float(x) / 10
js = "document.documentElement.scrollTop = document.documentElement.scrollHeight * %f" % height
spider.driver.execute_script(js)
time.sleep(0.2)
origin_code = spider.driver.page_source
# 将源代码构造成为一个Response对象,并返回。
res = HtmlResponse(url=request.url, encoding='utf8', body=origin_code, request=request)
# res = Response(url=request.url, body=bytes(origin_code), request=request)
return res
if spider.name == 'bole':
request.cookies = {}
request.headers.setDefault('User-Agent','')
return None
def process_response(self, request, response, spider):
print(response.url, response.status)
return response
taobao.py 代码如下:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver import FirefoxOptions
class TaobaoSpider(scrapy.Spider):
"""
scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。
如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?
方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将源代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的process_request()以及Downloader都跳过了。
"""
name = 'taobao'
allowed_domains = ['taobao.com']
start_urls = ['https://s.taobao.com/search?q=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306']
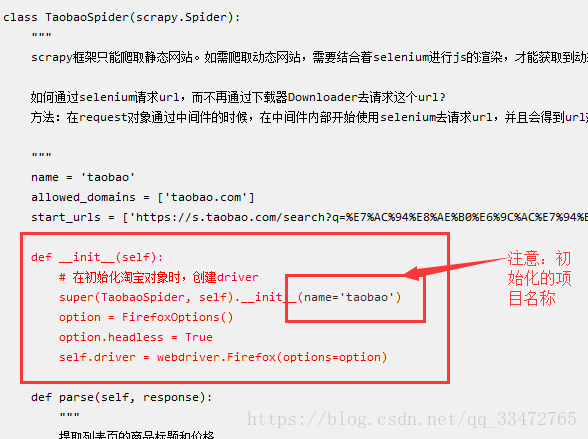
def __init__(self):
# 在初始化淘宝对象时,创建driver
super(TaobaoSpider, self).__init__(name='taobao')
option = FirefoxOptions()
option.headless = True
self.driver = webdriver.Firefox(options=option)
def parse(self, response):
"""
提取列表页的商品标题和价格
:param response:
:return:
"""
info_divs = response.xpath('//div[@class="info-cont"]')
print(len(info_divs))
for div in info_divs:
title = div.xpath('.//a[@class="product-title"]/@title').extract_first('')
price = div.xpath('.//span[contains(@class, "g_price")]/strong/text()').extract_first('')
print(title, price)
settings.py代码如下图:

关于代码中提到的初始化driver的位置有以下两种情况:
1、只存在一个爬虫文件的话,driver初始化函数可以定义在middlewares.py的自定义中间件中(如上述代码注释初始化部分)也可以在爬虫文件中自定义(如上述代码在爬虫文件中初始化)。
注意:如果只有一个爬虫文件就不需要在自定义的process_requsests中判断是哪一个爬虫项目然后分别请求!
2、如果存在两个或两个以上爬虫项目(如下图项目结构)的时候,需要将driver的初始化函数定义在各自的爬虫项目文件下(如上述代码),同时需要在process_requsests判断是那个爬虫项目的请求!!
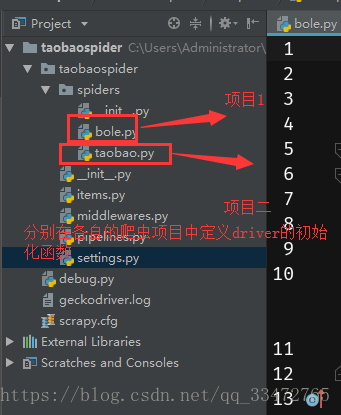
到此这篇关于scrapy与selenium结合爬取数据的示例代码的文章就介绍到这了,更多相关scrapy selenium爬取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Scrapy基于selenium结合爬取淘宝的实例讲解
在对于淘宝,京东这类网站爬取数据时,通常直接使用发送请求拿回response数据,在解析获取想要的数据时比较难的,因为数据只有在浏览网页的时候才会动态加载,所以要想爬取淘宝京东上的数据,可以使用selenium来进行模拟操作 对于scrapy框架,下载器来说已经没多大用,因为获取的response源码里面没有想要的数据,因为没有加载出来,所以要在请求发给下载中间件的时候直接使用selenium对请求解析,获得完整response直接返回,不经过下载器下载,上代码 from selenium im
-
scrapy利用selenium爬取豆瓣阅读的全步骤
首先创建scrapy项目 命令:scrapy startproject douban_read 创建spider 命令:scrapy genspider douban_spider url 网址:https://read.douban.com/charts 关键注释代码中有,若有不足,请多指教 scrapy项目目录结构如下 douban_spider.py文件代码 爬虫文件 import scrapy import re, json from ..items import DoubanReadI
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-

python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
一.CrawlSpider类介绍 1.1 引入 使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类.基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康 scrapy基于CrawlSpider类的全站数据爬取 1.2 介绍和使用 1.2.1 介绍 CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是 LinkExtractor()和rules
-
Python实现抓取腾讯视频所有电影的示例代码
目录 运行环境 实现目的与思路 目的 思路 完整代码 视频缓存ts文件 实现效果 运行环境 IDE丨pycharm 版本丨Python3.6 系统丨Windows 实现目的与思路 目的 实现对腾讯视频目标url的解析与下载,由于第三方vip解析,只提供在线观看,隐藏想实现对目标视频的下载 思路 首先拿到想要看的腾讯电影url,通过第三方vip视频解析网站进行解析,通过抓包,模拟浏览器发送正常请求,通过拿到缓存ts文件,下载视频ts文件,最后通过转换为mp4文件,即可实现正常播放 完整代码 imp
-
C++实现将数据写入Excel工作表的示例代码
目录 安装Spire.XLS for C++ 在 C++ 中将文本或数字值写入单元格 完整代码 效果图 在 C++ 中将数组写入指定的单元格范围 完整代码 效果图 直观的界面.出色的计算功能和图表工具,使Excel成为最流行的个人计算机数据处理软件.在独立的数据包含的信息量太少,而过多的数据又难以理清头绪时,制作成表格是数据管理的最有效手段之一.这样不仅可以方便整理数据,还可以方便我们查找和应用数据.后期我们还可以对具有相似表格框架,相同性质的数据进行合并汇总工作.在本文中,您将学习如何使用 S
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
大数据 java hive udf函数的示例代码(手机号码脱敏)
Hive UDFHive UDF 函数1 POM 文件2.UDF 函数3 利用idea打包4 添加hive udf函数4.1 上传jar包到集群4.2 修改集群hdfs文件权限4.3 注册UDF4.4 使用UDF Hive UDF 函数 1 POM 文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0"
-
Python 数据的累加与统计的示例代码
问题 你需要处理一个很大的数据集并需要计算数据总和或其他统计量. 解决方案 对于任何涉及到统计.时间序列以及其他相关技术的数据分析问题,都可以考虑使用 Pandas库 . 为了让你先体验下,下面是一个使用Pandas来分析芝加哥城市的 老鼠和啮齿类动物数据库 的例子. 在我写这篇文章的时候,这个数据库是一个拥有大概74,000行数据的CSV文件. >>> import pandas >>> # Read a CSV file, skipping last line &g
-
vue.js通过自定义指令实现数据拉取更新的实现方法
前言 这篇文章的代码片段位于 vue 的单文件组件中,即以 .vue 结尾的文件中,本文说明的只是一种实现方法,既不是唯一的方法也不是最好的方法,如果大家有更好的方法可以留言,大家进行讨论. 第一步 首先,一定要先定义变量: // app.vue <script> data () { return { // 定义 getData getData:{}, // 定义自定义指令的绑定值 ifUpdate:true } } 第二步 然后要使用 ajax 的话,要在 index.html 里引入 jq
-
python DataFrame中loc与iloc取数据的基本方法实例
目录 1.准备一组DataFrame数据 2.loc标签索引 2.1loc获取行 2.1.1loc获取一行 2.1.2loc获取多行 2.1.3loc获取多行(切片) 2.2loc获取指定数据(行&列) 3.iloc位置索引 3.1iloc获取行 3.1.1iloc获取单行 3.1.2iloc获取多行 3.2iloc获取指定数据(行&列)获取所有行,指定列 总结 关于python数据分析常用库pandas中的DataFrame的loc和iloc取数据 基本方法总结归纳及示例如下: 1.准备