python 如何使用find和find_all爬虫、找文本的实现
这篇文章我们来讲讲如何在python使用bs4模块返回值中正确使用find和find_all来取值。
我们先来看看find函数在两种场景使用: 一、 find在字符串(str)时可以查找使用。
在字符串(str)是怎么来使用find函数,find函数就是找到的意思。
我们来看看下面案例
#---------案例1-----------
a='0123456789'#因为我们电脑中的字节都是从0开始算第一个位置
b=a.find('0')#这行代码的意思就是我要查找a中0的位置
print(b)
>>0
#这里就是打印出来的内容
应为0在a中的第0个位置
在来试试第二个案例
#---------案例2-----------
a='0123456789'
b=a.find('5')#我要查找a中5的位置
print(b)
>>5
其中你要查找的内容不在a中,则会返回 -1 。在str中的使用方法说到这里。
二、 find在bs4模块返回值中怎么使用
我们在课堂上学过,bs4返回的值是 <class 'bs4.BeautifulSoup'>
假设我把把bs4返回的值赋值给 bs
这时我们就要用 bs.find(class_=‘one')
这个代码就是在bs值中从上往下找,找到第一个类等于one的值。
如果下图
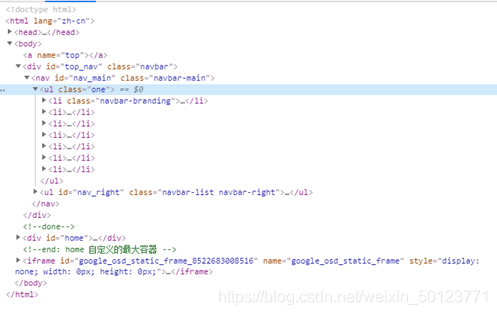
从上到下找是不是我标出来蓝色区域是我要找的类,对的我们把他赋值给one,我们把他打印出来
print('one')
这时候系统就会返回这样一个值给我们,如下图
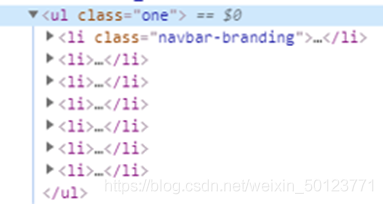
大家看,他返回的是从 class='one'开始到这个类标签ul结束,对的,他不会返回其他值,他只会返回这个类的标签开始到结束。
所以当bs4返回值时,第一步使用find找打包含自己要找的所有值中第一个父类,再赋值给函数,这样这个函数就是我们进行下一步查找的对象。
接下俩我们就还可以使用find(找到)或者find_all(找到全部一样的),来定位函数位置,像图中:

class="navbar-branding"就只有一个,我们像打印出 开发者的网上家园 怎么写
这时候我们假设,上面bs.find(class_='one')赋值给one函数那么我们就从one开始查找
one.find(class="navbar-branding")这样查找出来的内哦让那个就会返回给我们这个区域内容

然后这个区域的文字再title值里面,我们就没办法直接用 .text 取值了,所以我们要接着查找
将one.find(class="navbar-branding")赋值给 one_1
然后用 one_1.find('a')来查找到a标签
后面加一个中括号取值[‘title']这样打印出来内容就是“开发者的网上家园”了。
连起来就是这样写
print(one_1.find('a') ['title'])
下面我们把代码连起来打一遍看图

看代码
one=bs.find(class_='one')
one_1=one.find(class="navbar-branding")
print(one_1.find('a') ['title'])
>>开发者的网上家园
#这就是最后返回的值
就这么简单。
三、 find_all在bs4模块返回值中怎么使用
还是用上图举例

我们可以看到如果我要取下面的 li 标签中的值怎么办
这时候我们就得用到find_al了(查找全部一样的)
先补充代码到这个li标签的父类
one=bs.find(class_='one') one_1=one.find(class="navbar-branding")
然后我们用one_1来取值如下代码
one_1.find_all('li')#这时候我们取值了再one_1区域中所有有li便签的内容
他会返回给我们一个列表
列表时这样的
<li>…</li>,<li>…</li>,<li>…</li>,<li>…</li>,<li>…</li>,<li>…</li>
每一个区域就是一个内容,中间的。。。我时为了图省事,其实都是内容。
竟然得到这样的一个列表我们就可以使用for I in one_1.find_all('li')
这样取遍历出这个列表的东西,然后取值,
或者我只要其中一个就是ne_1.find_all('li')[2] 后面加一个数字,
列表取值大家应该都会把,这样就可以定位到我们想要的东西了。
总结一下find就是查找某一项的第一个数据,find_all就是找所有数据,然后用for遍历就能取出
到此这篇关于python 如何使用find和find_all爬虫、找文本的实现的文章就介绍到这了,更多相关python find和find_all爬虫 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现Linux的find命令实例分享
使用Python实现简单Linux的find命令 代码如下: #!/usr/bin/python #*-*coding:utf8*-* from optparse import OptionParser import os import sys #使用选项帮助信息可以使用中文 reload(sys) sys.setdefaultencoding("utf-8") #定义选项以及命令使用帮助信息 usage = sys.argv[0] + " Directory Options
-
详解python中index()、find()方法
python中index().find()方法,具体内容如下: index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常.影响后面程序执行 index()方法语法:str.index(str, beg=0, end=len(string)) str -- 指定检索的字符串 beg -- 开始索引,默认为0. end --
-
python re模块findall()函数实例解析
本文研究的是re模块findall()函数的相关内容,首先看看实例代码: >>> import re >>> s = "adfad asdfasdf asdfas asdfawef asd adsfas " >>> reObj1 = re.compile('((\w+)\s+\w+)') >>> reObj1.findall(s) [('adfad asdfasdf', 'adfad'), ('asdfas asd
-
详解Python中find()方法的使用
find()方法判断字符串str,如果起始索引beg和结束end索引能找到在字符串或字符串的一个子串中. 语法 以下是find()方法的语法: str.find(str, beg=0 end=len(string)) 参数 str -- 此选项指定要搜索的字符串. beg -- 这是开始索引,默认情况下为 0. end -- 这是结束索引,默认情况下它等于字符串的长度. 返回值 如果找到此方法返回的索引,否则返回-1. 例子 下面的例子显示了find()方法的使用. #!/usr/bin/pyt
-
python里使用正则的findall函数的实例详解
python里使用正则的findall函数的实例详解 在前面学习了正则的search()函数,这个函数可以找到一个匹配的字符串返回,但是想找到所有匹配的字符串返回,怎么办呢?其实得使用findall()函数.如下例子: #python 3. 6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'abbaaabbbbaaaaa' pattern = 'ab' for match in r
-
关于Python正则表达式 findall函数问题详解
在写正则表达式的时候总会遇到不少的问题, 特别是在表达式有多个元组的时候.下面看下re模块下的findall()函数和多个表达式元组相遇的时候会出现什么样的坑. 代码如下: import re str="a b c d" regex0=re.compile("((\w+)\s+\w+)") print(regex0.findall(str)) regex1=re.compile("(\w+)\s+\w+") print(regex1.findal
-
Python中的rfind()方法使用详解
rfind()方法返回所在子str 被找到的最后一个索引,或者-1,如果没有这样的索引不存在,可选择限制搜索字符串string[beg:end]. 语法 以下是rfind()方法的语法: str.rfind(str, beg=0 end=len(string)) 参数 str -- 此选项指定要搜索的字符串 beg -- 这是开始索引,默认情况下为 0 end -- 这是结束索引,默认情况下它等于该字符串的长度 返回值 此方法如果找到返回最后一个索引,否则返回-1 例子 下面的例子显示了rfin
-
python中正则表达式 re.findall 用法
Python 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. 本文主要给大家介绍
-
python 如何使用find和find_all爬虫、找文本的实现
这篇文章我们来讲讲如何在python使用bs4模块返回值中正确使用find和find_all来取值. 我们先来看看find函数在两种场景使用: 一. find在字符串(str)时可以查找使用. 在字符串(str)是怎么来使用find函数,find函数就是找到的意思. 我们来看看下面案例 #---------案例1----------- a='0123456789'#因为我们电脑中的字节都是从0开始算第一个位置 b=a.find('0')#这行代码的意思就是我要查找a中0的位置 print(b)
-
Python使用requests及BeautifulSoup构建爬虫实例代码
本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下. 功能说明 在Python下面可使用requests模块请求某个url获取响应的html文件,接着使用BeautifulSoup解析某个html. 案例 假设我要http://maoyan.com/board/4猫眼电影的top100电影的相关信息,如下截图: 获取电影的标题及url. 安装requests和BeautifulSoup 使用pip工具安装这两个工具. pip install
-
利用Python写一个爬妹子的爬虫
前言 最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据.解析数据.保存数据.下面一一来讲. 1.下载数据 首先打开要爬的网站,分析URL,每打开一个网页看URL有什么变化,有可能带上上个网页的某个数据,例如xxID之类,那么我们就需要在上一个页面分析HTML,找到对应的数据.如果网页源码找不到,可能是ajax异步加载,去xhr里去找. 有的网站做了反爬的处理,可以添加User-Agent :判断浏览器 se
-
Python selenium模拟网页点击爬虫交管12123违章数据
在上一篇文章<Python教程-模拟网页点击爬虫定位系统>讲解怎么通过模拟点击方式爬取车辆定位数据,本次介绍怎么以模拟点击方式进入交管12123爬取车辆违章数据,本文直接讲解过程,使用的命令解释见上一篇文章.本文同<Python教程-模拟网页点击爬虫定位系统>同样为企业中实际的爬虫案例,如果之后想进入车企行业可以做个了解. 准备工具:spyder.selenium库.google浏览器及对应版本的chromedriver.exe 效果 注:分享此案例目的是为了帮助同行解放双手,更好
-
python 实现一个贴吧图片爬虫的示例
今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开发环境是Python2,因为大学时自学的是python2 第一步:就是打开cmd命令,输入pip install lxml 如图 第二步:下载一个chrome插件:专门用来将html文件转为xml用xpth技术定位 在页面按下Ctrl+Shift+X即可打开插件进行页面分析 如下图 图中的黑色方框左边填写xpth
-
php与python实现的线程池多线程爬虫功能示例
本文实例讲述了php与python实现的线程池多线程爬虫功能.分享给大家供大家参考,具体如下: 多线程爬虫可以用于抓取内容了这个可以提升性能了,这里我们来看php与python 线程池多线程爬虫的例子,代码如下: php例子 <?php class Connect extends Worker //worker模式 { public function __construct() { } public function getConnection() { if (!self::$ch) { sel
-
Python实现简单的获取图片爬虫功能示例
本文实例讲述了Python实现简单的获取图片爬虫功能.分享给大家供大家参考,具体如下: 简单Python爬虫,获得网页上的照片 #coding=utf-8 import urllib import re def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getImg(html): reg = r'src="(.+?\.jpg)" pic_ext' imgre = re.comp
-
Python实现的文轩网爬虫完整示例
本文实例讲述了Python实现的文轩网爬虫.分享给大家供大家参考,具体如下: encoding=utf8 import pymysql import time import sys import requests import os #捕获错误 import traceback import types #将html实体化 import cgi import warnings reload(sys) sys.setdefaultencoding('utf-8') from pyquery imp
-
Python实现的爬取小说爬虫功能示例
本文实例讲述了Python实现的爬取小说爬虫功能.分享给大家供大家参考,具体如下: 想把顶点小说网上的一篇持续更新的小说下下来,就写了一个简单的爬虫,可以爬取爬取各个章节的内容,保存到txt文档中,支持持续更新保存.需要配置一些信息,设置文档保存路径,书名等.写着玩,可能不大规范. # coding=utf-8 import requests from lxml import etree from urllib.parse import urljoin import re import os #
-
解决python调用自己文件函数/执行函数找不到包问题
写python程序的时候很多人习惯创建一个utils.py文件,存放一些经常使用的函数,方便其他文件调用,同时也更好的管理一些通用函数,方便今后使用.或是两个文件之间的class或是函数调用情况. 就像下面的工程目录一样: 工程目录 Project\ ... src\ main.py utils.py test.py ... python调用其他文件中的函数 在main.py文件中加入一下语句即可调用utils.py下面的函数:'' import src.utils as utils X, y