python中导入 train_test_split提示错误的解决
如下所示:

原因:
在python3.6中sklearn已弃用train_test_split,导致导入报错
解决方式,用model_selection模块导入:
from sklearn.model_selection import train_test_split

经测试,在python2中也是使用该方式导入train_test_split模块
补充知识:from sklearn.model_selection import train_test_split找不到模块
解决方案:
pip uninstall numpy
pip install numpy==1.16(或pip install numpy==1.14.5)
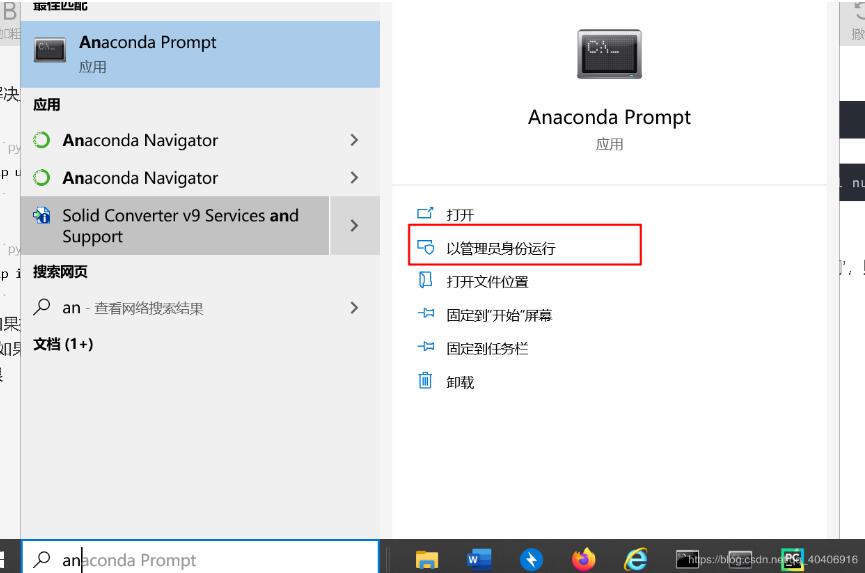
如果提示权限不够,‘[WinError 5]拒绝访问',则需打开管理员权限
以上这篇python中导入 train_test_split提示错误的解决就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在keras中model.fit_generator()和model.fit()的区别说明
首先Keras中的fit()函数传入的x_train和y_train是被完整的加载进内存的,当然用起来很方便,但是如果我们数据量很大,那么是不可能将所有数据载入内存的,必将导致内存泄漏,这时候我们可以用fit_generator函数来进行训练. keras中文文档 fit fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=N
-
浅谈keras通过model.fit_generator训练模型(节省内存)
前言 前段时间在训练模型的时候,发现当训练集的数量过大,并且输入的图片维度过大时,很容易就超内存了,举个简单例子,如果我们有20000个样本,输入图片的维度是224x224x3,用float32存储,那么如果我们一次性将全部数据载入内存的话,总共就需要20000x224x224x3x32bit/8=11.2GB 这么大的内存,所以如果一次性要加载全部数据集的话是需要很大内存的. 如果我们直接用keras的fit函数来训练模型的话,是需要传入全部训练数据,但是好在提供了fit_generator,
-
使用Keras中的ImageDataGenerator进行批次读图方式
ImageDataGenerator位于keras.preprocessing.image模块当中,可用于做数据增强,或者仅仅用于一个批次一个批次的读进图片数据.一开始以为ImageDataGenerator是用来做数据增强的,但我的目的只是想一个batch一个batch的读进图片而已,所以一开始没用它,后来发现它是有这个功能的,而且使用起来很方便. ImageDataGenerator类包含了如下参数:(keras中文教程) ImageDataGenerator(featurewise_cen
-
浅谈keras2 predict和fit_generator的坑
1.使用predict时,必须设置batch_size,否则效率奇低. 查看keras文档中,predict函数原型: predict(self, x, batch_size=32, verbose=0) 说明: 只使用batch_size=32,也就是说每次将batch_size=32的数据通过PCI总线传到GPU,然后进行预测.在一些问题中,batch_size=32明显是非常小的.而通过PCI传数据是非常耗时的. 所以,使用的时候会发现预测数据时效率奇低,其原因就是batch_size太小
-
python中导入 train_test_split提示错误的解决
如下所示: 原因: 在python3.6中sklearn已弃用train_test_split,导致导入报错 解决方式,用model_selection模块导入: from sklearn.model_selection import train_test_split 经测试,在python2中也是使用该方式导入train_test_split模块 补充知识:from sklearn.model_selection import train_test_split找不到模块 解决方案: pip u
-
解决Python中导入自己写的类,被划红线,但不影响执行的问题
1. 错误描述 之前在学习Python的过程中,导入自己写的包文件时,与之相关的方法等都会被划红线,但并不影响代码执行,如图: 看着红线确实有点强迫症,并且在这个过程当时,当使用该文件里的方法时不会自动提示方法名,只能靠手全部输入,这种容易造成手误,对于小白特别容易降低编写效率 2. 原因分析 pycharm中,source root概念非常重要,当你在代码中写相对路径的时候,就是以source root为起点进行查询. 而pycharm中,当前的项目文件夹 是默认的source root,当你
-
解决python中导入win32com.client出错的问题
准备写一个操作Excel脚本却在导入包的时候出现了一个小问题 导入包 from Tkinter import Tk from time import sleep, ctime from tkMessageBox import showwarning from urllib import urlopen import win32com.client as win32 报错提示 Traceback (most recent call last): File "estock.pyw", li
-
解决IDEA和CMD中java命令提示错误: 找不到或无法加载主类的问题
一 概述 CMD D:\Project\Computer-Science-And-Technology\writeExam\farben\src\com\GC>java CommandLineParameter 错误: 找不到或无法加载主类 CommandLineParameter IDEA D:\Project\Computer-Science-And-Technology\writeExam\farben\src\com\GC>java CommandLineParamete
-
element 结合vue 在表单验证时有值却提示错误的解决办法
绑定的值与规则指定的值一定要相同------- 第一步: <el-form :model="ruleForm" :rules="rules" ref="ruleForm" label-width="100px" class="demo-ruleForm"> 加上rules ref 第二部: <el-form-item label="活动名称" prop="na
-
Python pip安装模块提示错误解决方案
问题如下 python pip安装模块提示错误failed to create process 原因: 报这个错误的原因,是因为python的目录名称或位置发生改动. 解决办法: 1.找到修改python所在的目录,打开scripts目录,如下图找到修改python所在的目录,打开scripts目录,找到pip3-script.py文件.如下图: 2.找到pip-script.py文件,并打开,在第一行替换以下代码,路径为你修改的python.exe的路径: 新: #!F:\cxm\venv\S
-
如何在python 中导入 package
package 在 python 中,是一种有效组织代码,module 可以是一个文件,可以通过 import 来导入一个 module 单个文件,而 package 则是作为一个目录来导入.随后我们还会看一看多层嵌套是如何导入的. >>> import collections,socket >>> print(collections.__path__) ['/anaconda3/envs/py38/lib/python3.8/collections'] >>
-
如何在Python中导入EXCEL数据
目录 一.前期准备 二.编写代码基本思路 三.编写代码读取数据 3.1 3.2 四.结语 一.前期准备 此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的. 首先需要安装两个模块,一个是pandas,另一个是xlrd. 在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号. 然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd. 选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中. 需要注意的是,
-
Python 中导入csv数据的三种方法
Python 中导入csv数据的三种方法,具体内容如下所示: 1.通过标准的Python库导入CSV文件: Python提供了一个标准的类库CSV文件.这个类库中的reader()函数用来导入CSV文件.当CSV文件被读入后,可以利用这些数据生成一个NumPy数组,用来训练算法模型.: from csv importreader import numpy as np filename=input("请输入文件名: ") withopen(filename,'rt',encoding='
-
在python中logger setlevel没有生效的解决
在logging中,Logger's level 的默认等级为warning 所以虽然在handler中setlervel了,Logger's level 和Handler's Level 但是level取较高的那个(待校验) 所以日志的level 为warning 解决此问题可以采用 logging.root.setLevel(logging.NOTSET) 完整源码如下图: import logging class loggerr(object): def __init__(self,log
随机推荐
- Angularjs分页查询的实现
- 基于angular中的重要指令详解($eval,$parse和$compile)
- jquery实现的网页自动播放声音
- 了解VUE的render函数的使用
- 基于Java内存溢出的解决方法详解
- 微信小程序使用第三方库Immutable.js实例详解
- php实现兼容2038年后Unix时间戳转换函数
- php过滤所有恶意字符(批量过滤post,get敏感数据)
- android LinearLayout 布局实例代码
- Python外星人入侵游戏编程完整版
- DirectInfo.GetFiles返回数组的默认排序示例
- MySQL中对表连接查询的简单优化教程
- java读取解析xml文件实例
- Winform窗体效果实例分析
- Linux中获取某个进程的系统调用以及参数(故障排查案例)
- jQuery老黄历完整实现方法
- asp.net(C#)清除全部Session与单个Session的方法
- MFC中exe图标修改的方法
- C语言接口与实现方法实例详解
- 三层交换机的智能流处理技术