pytorch VGG11识别cifar10数据集(训练+预测单张输入图片操作)
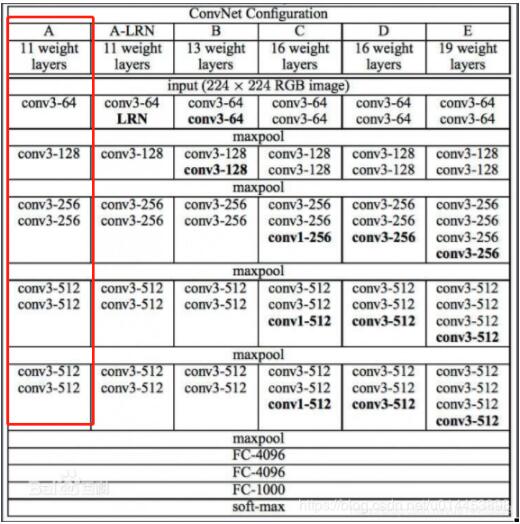
首先这是VGG的结构图,VGG11则是红色框里的结构,共分五个block,如红框中的VGG11第一个block就是一个conv3-64卷积层:
一,写VGG代码时,首先定义一个 vgg_block(n,in,out)方法,用来构建VGG中每个block中的卷积核和池化层:
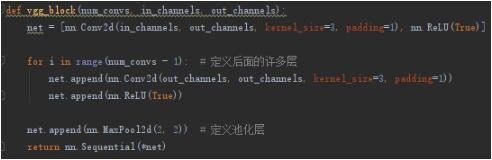
n是这个block中卷积层的数目,in是输入的通道数,out是输出的通道数
有了block以后,我们还需要一个方法把形成的block叠在一起,我们定义这个方法叫vgg_stack:
def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512))) net = [] for n, c in zip(num_convs, channels): in_c = c[0] out_c = c[1] net.append(vgg_block(n, in_c, out_c)) return nn.Sequential(*net)
右边的注释
vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
里,(1, 1, 2, 2, 2)表示五个block里,各自的卷积层数目,((3, 64), (64, 128), (128, 256), (256, 512), (512, 512))表示每个block中的卷积层的类型,如(3,64)表示这个卷积层输入通道数是3,输出通道数是64。vgg_stack方法返回的就是完整的vgg11模型了。
接着定义一个vgg类,包含vgg_stack方法:
#vgg类 class vgg(nn.Module): def __init__(self): super(vgg, self).__init__() self.feature = vgg_net self.fc = nn.Sequential( nn.Linear(512, 100), nn.ReLU(True), nn.Linear(100, 10) ) def forward(self, x): x = self.feature(x) x = x.view(x.shape[0], -1) x = self.fc(x) return x
最后:
net = vgg() #就能获取到vgg网络
那么构建vgg网络完整的pytorch代码是:
def vgg_block(num_convs, in_channels, out_channels): net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)] for i in range(num_convs - 1): # 定义后面的许多层 net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)) net.append(nn.ReLU(True)) net.append(nn.MaxPool2d(2, 2)) # 定义池化层 return nn.Sequential(*net) # 下面我们定义一个函数对这个 vgg block 进行堆叠 def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512))) net = [] for n, c in zip(num_convs, channels): in_c = c[0] out_c = c[1] net.append(vgg_block(n, in_c, out_c)) return nn.Sequential(*net) #确定vgg的类型,是vgg11 还是vgg16还是vgg19 vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512))) #vgg类 class vgg(nn.Module): def __init__(self): super(vgg, self).__init__() self.feature = vgg_net self.fc = nn.Sequential( nn.Linear(512, 100), nn.ReLU(True), nn.Linear(100, 10) ) def forward(self, x): x = self.feature(x) x = x.view(x.shape[0], -1) x = self.fc(x) return x #获取vgg网络 net = vgg()
基于VGG11的cifar10训练代码:
import sys
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
def vgg_block(num_convs, in_channels, out_channels):
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)]
for i in range(num_convs - 1): # 定义后面的许多层
net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
net.append(nn.ReLU(True))
net.append(nn.MaxPool2d(2, 2)) # 定义池化层
return nn.Sequential(*net)
# 下面我们定义一个函数对这个 vgg block 进行堆叠
def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net.append(vgg_block(n, in_c, out_c))
return nn.Sequential(*net)
#vgg类
class vgg(nn.Module):
def __init__(self):
super(vgg, self).__init__()
self.feature = vgg_net
self.fc = nn.Sequential(
nn.Linear(512, 100),
nn.ReLU(True),
nn.Linear(100, 10)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
# 然后我们可以训练我们的模型看看在 cifar10 上的效果
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5
x = x.transpose((2, 0, 1)) ## 将 channel 放到第一维,只是 pytorch 要求的输入方式
x = torch.from_numpy(x)
return x
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / total
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):
if torch.cuda.is_available():
net = net.cuda()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
net = net.train()
for im, label in train_data:
if torch.cuda.is_available():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
im = Variable(im)
label = Variable(label)
# forward
output = net(im)
loss = criterion(output, label)
# forward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += get_acc(output, label)
if valid_data is not None:
valid_loss = 0
valid_acc = 0
net = net.eval()
for im, label in valid_data:
if torch.cuda.is_available():
with torch.no_grad():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
with torch.no_grad():
im = Variable(im)
label = Variable(label)
output = net(im)
loss = criterion(output, label)
valid_loss += loss.item()
valid_acc += get_acc(output, label)
epoch_str = (
"Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "
% (epoch, train_loss / len(train_data),
train_acc / len(train_data), valid_loss / len(valid_data),
valid_acc / len(valid_data)))
else:
epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %
(epoch, train_loss / len(train_data),
train_acc / len(train_data)))
# prev_time = cur_time
print(epoch_str)
if __name__ == '__main__':
# 作为实例,我们定义一个稍微简单一点的 vgg11 结构,其中有 8 个卷积层
vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
print(vgg_net)
train_set = CIFAR10('./data', train=True, transform=transform, download=True)
train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_set = CIFAR10('./data', train=False, transform=transform, download=True)
test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)
net = vgg()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1)
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵
train(net, train_data, test_data, 50, optimizer, criterion)
torch.save(net, 'vgg_model.pth')
结束后,会出现一个模型文件vgg_model.pth
二,然后网上找张图片,把图片缩成32x32,放到预测代码中,即可有预测结果出现,预测代码如下:
import torch
import cv2
import torch.nn.functional as F
from vgg2 import vgg ##重要,虽然显示灰色(即在次代码中没用到),但若没有引入这个模型代码,加载模型时会找不到模型
from torch.autograd import Variable
from torchvision import datasets, transforms
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('vgg_model.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("horse.jpg") # 读取要预测的图片
trans = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
# 扩展后,为[1,1,28,28]
output = model(img)
prob = F.softmax(output,dim=1) #prob是10个分类的概率
print(prob)
value, predicted = torch.max(output.data, 1)
print(predicted.item())
print(value)
pred_class = classes[predicted.item()]
print(pred_class)
# prob = F.softmax(output, dim=1)
# prob = Variable(prob)
# prob = prob.cpu().numpy() # 用GPU的数据训练的模型保存的参数都是gpu形式的,要显示则先要转回cpu,再转回numpy模式
# print(prob) # prob是10个分类的概率
# pred = np.argmax(prob) # 选出概率最大的一个
# # print(pred)
# # print(pred.item())
# pred_class = classes[pred]
# print(pred_class)
缩成32x32的图片:

运行结果:

以上这篇pytorch VGG11识别cifar10数据集(训练+预测单张输入图片操作)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch预训练的实现
前言 最近使用PyTorch感觉妙不可言,有种当初使用Keras的快感,而且速度还不慢.各种设计直接简洁,方便研究,比tensorflow的臃肿好多了.今天让我们来谈谈PyTorch的预训练,主要是自己写代码的经验以及论坛PyTorch Forums上的一些回答的总结整理. 直接加载预训练模型 如果我们使用的模型和原模型完全一样,那么我们可以直接加载别人训练好的模型: my_resnet = MyResNet(*args, **kwargs) my_resnet.load_state_dict(
-
简单易懂Pytorch实战实例VGG深度网络
简单易懂Pytorch实战实例VGG深度网络 模型VGG,数据集cifar.对照这份代码走一遍,大概就知道整个pytorch的运行机制. 来源 定义模型: '''VGG11/13/16/19 in Pytorch.''' import torch import torch.nn as nn from torch.autograd import Variable cfg = { 'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M
-
Tensorflow模型实现预测或识别单张图片
利用Tensorflow训练好的模型,图片进行预测和识别,并输出相应的标签和预测概率. 如果想要多张图片,可以进行批次加载和预测,这里仅用单张图片进行演示. 模型文件: 预测图片: 这里直接贴代码,都有注释,应该很好理解 import tensorflow as tf import inference image_size = 128 # 输入层图片大小 # 模型保存的路径和文件名 MODEL_SAVE_PATH = "model/" MODEL_NAME = "model.
-
pytorch 准备、训练和测试自己的图片数据的方法
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试.如果我们是自己的图片数据,又该怎么做呢? 一.我的数据 我在学习的时候,使用的是fashion-mnist.这个数据比较小,我的电脑没有GPU,还能吃得消.关于fashion-mnist数据,可以百度,也可以点此 了解一下,数据就像这个样子: 下载地址:https://github.com/zalandoresearch/fashion-mnist 但是下载下来是一种二进制文件,并不是图片,因此我先转换成了图
-
pytorch VGG11识别cifar10数据集(训练+预测单张输入图片操作)
首先这是VGG的结构图,VGG11则是红色框里的结构,共分五个block,如红框中的VGG11第一个block就是一个conv3-64卷积层: 一,写VGG代码时,首先定义一个 vgg_block(n,in,out)方法,用来构建VGG中每个block中的卷积核和池化层: n是这个block中卷积层的数目,in是输入的通道数,out是输出的通道数 有了block以后,我们还需要一个方法把形成的block叠在一起,我们定义这个方法叫vgg_stack: def vgg_stack(num_conv
-
利用pytorch实现对CIFAR-10数据集的分类
步骤如下: 1.使用torchvision加载并预处理CIFAR-10数据集. 2.定义网络 3.定义损失函数和优化器 4.训练网络并更新网络参数 5.测试网络 运行环境: windows+python3.6.3+pycharm+pytorch0.3.0 import torchvision as tv import torchvision.transforms as transforms import torch as t from torchvision.transforms import
-
python中关于CIFAR10数据集的使用
目录 关于CIFAR10数据集的使用 CIFAR10的官方解释 实战操作 CIFAR-10 数据集简介 数据集版本 数据集布置 总结 关于CIFAR10数据集的使用 主要解决了如何把数据集与transforms结合在一起的问题. CIFAR10的官方解释 torchvision.datasets.CIFAR10( root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Opt
-
Pytorch自己加载单通道图片用作数据集训练的实例
pytorch 在torchvision包里面有很多的的打包好的数据集,例如minist,Imagenet-12,CIFAR10 和CIFAR100.在torchvision的dataset包里面,用的时候直接调用就行了.具体的调用格式可以去看文档(目前好像只有英文的).网上也有很多源代码. 不过,当我们想利用自己制作的数据集来训练网络模型时,就要有自己的方法了.pytorch在torchvision.dataset包里面封装过一个函数ImageFolder().这个函数功能很强大,只要你直接将
-
运用PyTorch动手搭建一个共享单车预测器
本文摘自 <深度学习原理与PyTorch实战> 我们将从预测某地的共享单车数量这个实际问题出发,带领读者走进神经网络的殿堂,运用PyTorch动手搭建一个共享单车预测器,在实战过程中掌握神经元.神经网络.激活函数.机器学习等基本概念,以及数据预处理的方法.此外,还会揭秘神经网络这个"黑箱",看看它如何工作,哪个神经元起到了关键作用,从而让读者对神经网络的运作原理有更深入的了解. 3.1 共享单车的烦恼 大约从2016年起,我们的身边出现了很多共享单车.五颜六色.各式各样的共
-
keras实现VGG16 CIFAR10数据集方式
我就废话不多说了,大家还是直接看代码吧! import keras from keras.datasets import cifar10 from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Co
-

PyTorch搭建ANN实现时间序列风速预测
目录 数据集 特征构造 数据处理 1.数据预处理 2.数据集构造 ANN模型 1.模型训练 2.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将简单搭建来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 数据处理 1.数据预处理 数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一
-
PyTorch搭建LSTM实现时间序列负荷预测
目录 I. 前言 II. 数据处理 III. LSTM模型 IV. 训练 V. 测试 VI. 源码及数据 I. 前言 在上一篇文章深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中,我详细地解释了如何利用PyTorch来搭建一个LSTM模型,本篇文章的主要目的是搭建一个LSTM模型用于时间序列预测. 系列文章: PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch深度学习LSTM从input输入
-
pytorch cnn 识别手写的字实现自建图片数据
本文主要介绍了pytorch cnn 识别手写的字实现自建图片数据,分享给大家,具体如下: # library # standard library import os # third-party library import torch import torch.nn as nn from torch.autograd import Variable from torch.utils.data import Dataset, DataLoader import torchvision impo
-
PyTorch手写数字数据集进行多分类
目录 一.实现过程 0.导包 1.准备数据 2.设计模型 3.构造损失函数和优化器 4.训练和测试 二.参考文献 一.实现过程 本文对经典手写数字数据集进行多分类,损失函数采用交叉熵,激活函数采用ReLU,优化器采用带有动量的mini-batchSGD算法. 所有代码如下: 0.导包 import torch from torchvision import transforms,datasets from torch.utils.data import DataLoader import tor