10大HBase常见运维工具整理小结
摘要:HBase自带许多运维工具,为用户提供管理、分析、修复和调试功能。本文将列举一些常用HBase工具,开发人员和运维人员可以参考本文内容,利用这些工具对HBase进行日常管理和运维。
HBase组件介绍
HBase作为当前比较热门和广泛使用的NoSQL数据库,由于本身设计架构和流程上比较复杂,对大数据经验较少的运维人员门槛较高,本文对当前HBase上已有的工具做一些介绍以及总结。

写在前面的说明:
1) 由于HBase不同版本间的差异性较大(如HBase2.x上移走了hbck工具),本文使用的所有命令行运行的环境为MRS_1.9.3,对应的HBase版本为1.3.1,部分命令在HBase2上不支持(有时间的话会对HBase2做单独的介绍)。
2) 本文所涉及的HBase工具均为开源自带工具,不涉及厂商自研的优化和运维工具。
Canary工具
HBase Canary是检测HBase集群当前状态的工具,用简单的查询来检查HBASE上的region是否可用(可读)。它主要分为两种模式
1) region模式(默认),对每个region下每个CF随机查询一条数据,打印是否成功以及查询时延。
#对t1和tsdb-uid表进行检查 hbase org.apache.hadoop.hbase.tool.Canary t1 tsdb-uid #注意:不指定表时扫所有region
2) regionserver模式,对每个regionserver上随机选一个表进行查询,打印是否成功以及查询时延。
#对一个regionserver进行检查 hbase org.apache.hadoop.hbase.tool.Canary -regionserver node-ana-coreQZLQ0002.1432edca-3d6f-4e17-ad52-098f2adde2e6.com #注意:不指定regionserver时扫所有regionserver
Canary还可以指定一些简单的参数,可以参考如下

总结:
- 对集群影响:2星(只是简单的读操作,region个数极多的时候会占用少部分请求吞吐)
- 实用性:2星
HFile工具
HBase HFile查看工具,主要用来检查当前某个具体的HFile的内容/元数据。当业务上发现某个region无法读取,在regionserver上由于文件问题无法打开region或者读取某个文件出现异常时,可用此工具单独来检查HFile是否有问题
#查看t1表下的其中一个HFile的详情,打印KV hbase org.apache.hadoop.hbase.io.hfile.HFile -v -m -p -f /hbase/data/default/t1/4dfafe12b749999fdc1e3325f22794d0/cf1/06e102be436c449693734b222b9e9aab
使用参数如下:

总结:
- 对集群影响:1星(此工具不走HBase通道,只是单纯的读取文件,不影响集群)
- 实用性:4星(可精确判断具体的HFile内容是否有问题)
RowCounter和CellCounter工具
RowCounter 是用MapReduce任务来计算表行数的一个统计工具。而和 RowCounter类似,但会收集和表相关的更细节的统计数据,包括:表的行数、列族数、qualifier数以及对应出现的次数等。两个工具都可以指定row的起止位置和timestamp来进行范围查询
# RowCounter扫描t1 hbase org.apache.hadoop.hbase.mapreduce.RowCounter t1 #用CellCounter扫描t1表并将结果写入HDFS的/tmp/t1.cell目录 hbase org.apache.hadoop.hbase.mapreduce.CellCounter t1 /tmp/t1.cell
使用参数如下:


总结:
对集群影响:3星(需要起MapReduce对表所有region进行scan,占用集群资源)
实用性:3星(HBase统计自身表行数的唯一工具, hbase shell中count效率比较低)
Clean工具
clean命令是用来清除HBase在ZooKeeper合HDFS上数据的工具。当集群想清理或铲除所有数据时,可以让HBase恢复到最初的状态。
#清除HBase下的所有数据 hbase clean --cleanAll使用参数如下:

总结:
对集群影响:5星(删除HBase集群上所有数据)
实用性:2星(除开需要重新设置HBase数据的场景如要切换到HBase on OBS,平时很少会用到)
HBCK工具
HBase的hbck工具是日常运维过程中使用最多的工具,它可以检查集群上region的一致性。由于HBase的RIT状态较复杂也最容易出现问题,日常运维过程中经常会遇到region不在线/不一致等问题,此时就可以根据hbck不同的检查结果使用相应的命令进行修复。
#检查t1表的region状态 hbase hbck t1 #修复t1表的meta并重新assign分配 hbase hbck -fixMeta -fixAssignments t1
由于该工具使用的场景太多太细,此处就不作展开介绍了,可以查看参数的描述来对各种异常场景进行修复。注意:在不清楚异常原因的情况下,千万不要乱使用修复命令病急乱投医,很有可能会使问题本身更糟糕。
使用参数如下:
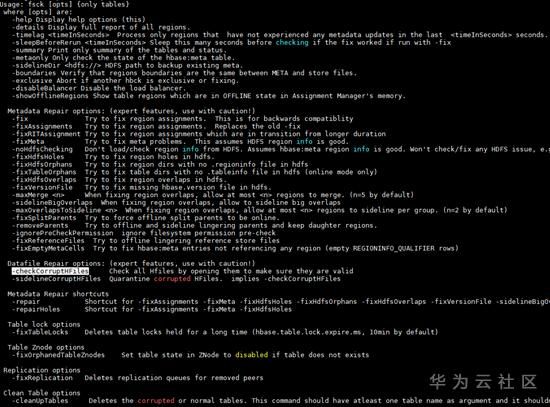
总结:
- 对集群影响:4星(个别meta相关命令对集群影响极大)
- 实用性:5星(hbck是HBase运维人员的最基本运维工具)
RegionSplitter工具
RegionSplitter是HBase的Pre-splitting工具,在table初始化的时候如果不配置pre-split的话,HBase不知道如何去split region,这就很大可能会造成后续的region/regionserver的热点,最好的办法就是首先预测split的切分点,在建表的时候做pre-splitting,保证一开始的业务访问总体负载均衡。RegionSplitter能够通过具体的split算法在建表的时候进行pre-split,自带了两种算法:
HexStringSplit
使用8个16进制字符来进行split,适合row key是十六进制的字符串(ASCII)作为前缀的时候
UniformSplit
使用一个长度为8的byte数组进行split,按照原始byte值(从0x00~0xFF)右边以00填充。以这种方式分区的表在Put数据的时候需要对rowkey做一定的修饰, 比如原来的rowkey为rawStr,则需要对其取hashCode,然后进行按照byte位反转后放在最初rowkey串的前面
#创建test_table表,并使用HexStringSplit算法预分区10个
hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f f1
#Tips:此操作等价于在hbase shell中create ' test_table ', { NAME => 'f1'},{NUMREGIONS => 10, SPLITALGO => 'HexStringSplit'}
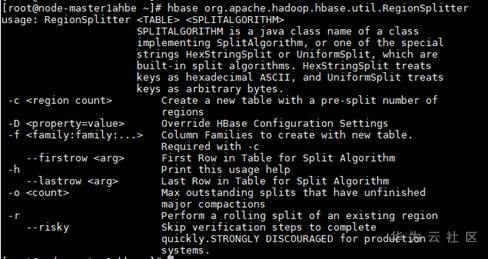
总结:
不管是HBase自带的哪一种pre-split算法,都是建立在表数据本身的rowkey符合它约定格式的条件下,实际用户还是需要按业务来设计rowkey,并实现自己的pre-split算法(实现SplitAlgorithm接口)
对集群影响:1星(创建表操作,不影响其他集群业务)
实用性:3星(实际pre-split都是按实际业务来的,对于测试来说可以使用HBase默认的split算法来构造rowkey格式)
FSHLog工具
FSHLog是HBase自带的一个WALs文件检查和split工具,它主要分为两部分功能
dump
将某个WAL文件中的内容dump出来具体的内容
split
触发某个WAL文件夹的WAL split操作
#dump出某个当前的WALs文件中的内容 hbase org.apache.hadoop.hbase.regionserver.wal.FSHLog --dump /hbase/WALs/node-ana-coreqzlq0002.1432edca-3d6f-4e17-ad52-098f2adde2e6.com,16020,1591846214733/node-ana-coreqzlq0002.1432edca-3d6f-4e17-ad52-098f2adde2e6.com%2C16020%2C1591846214733.1592184625801
相关参数

总结:
- 对集群影响:2星(触发的WAL split操作会对相应的Worker节点增加少量的负载,当需要split的WAL极大时,会对region级别的业务有影响)
- 实用性:4星(可以很好的检查WAL内容的准确性,以及适用于WAL搬迁的场景)
WALPlayer工具
WALPlayer是一个将WAL文件中的log回放到HBase的工具。可以通过对某个表或者所有表进行数据回放,也可以指定相应的时间区间等条件进数据回放。
#回放一个WAL文件的数据到表t1 hbase org.apache.hadoop.hbase.mapreduce.WALPlayer /tmp/node-ana-coreqzlq0002.1432edca-3d6f-4e17-ad52-098f2adde2e6.com%2C16020%2C1591846214733.1592184625801 t1
Q&A:FSHLog和WALPlayer都能将WAL文件中的数据恢复到HBase中,有什么差异区别?
FSHLog是触发WAL split请求到HMaster中,会对WAL中的所有数据恢复到HBase,走的是HBase自己的WAL split流程。而WALPlayer是本身起MR任务来扫WAL文件中的数据,对符合条件的数据put到特定的表中或输出HFile到特定目录
相关参数:

总结:
- 对集群影响:3星(起MR任务会占用部分集群资源)
- 实用性:4星(在某些特定的场景下实用性很高,如replication预同步,表数据恢复)
OfflineMetaRepair工具
OfflineMetaRepair工具由于修复HBase的元数据。它会基于HBase在HDFS上的region/table元数据,重建HBase元数据。
#重新建立hbase的元数据 hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair
Q&A:hbck的fixMeta同样可以修复HBase的元数据,还能指定具体的表使用更加灵活,还有必要使用OfflineMetaRepair?
hbck工具是HBase的在线修复工具,如果HBase没有启动是无法使用的。OfflineMetaRepair是在离线状态修复HBase元数据
相关参数:

总结:
- 对集群影响:5星(备份原始元数据表后,会重建HBase元数据)
- 实用性:4星(当HBase由于元数据原因无法启动时,此工具可以恢复HBase)
Sweeper工具
Sweeper工具(HBASE-11644)可以合并HBase集群中小的MOB文件并删除冗余的MOB文件。它会基于Column Family起相应的SweepJob任务来对相应的MOB文件进行合并。注意,此工具不能与MOB的major compaction同时运行,并且同一个Column Family的Sweeper任务不能同时有多个一起运行。
#对t1表执行Sweeper hbase org.apache.hadoop.hbase.mob.mapreduce.Sweeper t1 cf1
相关参数:

总结:
- 对集群影响:5星(合并MOB任务会占用大量的Yarn资源和IO,对业务影响很大)
- 实用性:2星(只适合MOB场景,使用MOB会存在HMaster上compact的瓶颈暂不推荐(社区HBASE3上才支持,相关jira HBASE-22749))
以上就是此次介绍的所有HBase运维工具,其他的如Bulkload批量导入,数据迁移,测试相关的pe等暂不描述。如果有写的不对的请指正,多谢。
官方文档:https://hbase.apache.org/book.html
到此这篇关于10大HBase常见运维工具整理小结的文章就介绍到这了,更多相关HBase 运维工具内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
集群运维自动化工具ansible之使用playbook安装zabbix客户端
之前介绍了关于ansible的安装与使用(包括模块与playbook使用,地址是http://www.jb51.net/article/52154.htm),今天介绍一下如何使用playbook来部署zabbix客户端. ansible服务端的环境为centos 6.5 x86_64系统 ansible客户端环境为centos 6.3 x86_64系统 目前我的playbook只允许centos或redhat 6系列系统来安装zabbix客户端,并且客户端的版本是2.0.6. 下面是playbo
-
Python自动化运维和部署项目工具Fabric使用实例
Fabric 是使用 Python 开发的一个自动化运维和部署项目的一个好工具,可以通过 SSH 的方式与远程服务器进行自动化交互,例如将本地文件传到服务器,在服务器上执行shell 命令. 下面给出一个自动化部署 Django 项目的例子 # -*- coding: utf-8 -*- # 文件名要保存为 fabfile.py from __future__ import unicode_literals from fabric.api import * # 登录用户和主机名: env.use
-

linux 自动化运维工具ansible的使用详细教程
一.ansible简介 1.ansible ansible是新出现的自动化运维工具,基于Python研发.糅合了众多老牌运维工具的优点实现了批量操作系统配置.批量程序的部署.批量运行命令等功能.仅需在管理工作站上安装ansible程序配置被管控主机的IP信息,被管控的主机无客户端.ansible应用程序存在于epel(第三方社区)源,依赖于很多python组件.主要包括: (1).连接插件connection plugins:负责和被监控端实现通信: (2).host inventory:指定操
-
开发、运维不可不看的Linux调测工具【推荐】
系统性能专家 Brendan D. Gregg 在 LinuxCon NA 2014 大会上更新了他那个有名的关于Linux 性能方面的 talk (Linux Performance Tools) 和幻灯片.分别从监控.测试.优化.配置的角度总结了Linux日常所用到的工具.下面是其中的主要图片资料,希望对您有所帮助. 性能工具(Linux Performance Tools-full) 这张图是集合了监测.测试.调优的高分辨率版本.后面会根据不同的分类单独展示. 基准测试工具(Linux P
-
集群运维自动化工具ansible的安装与使用(包括模块与playbook使用)第1/2页
我使用过puppet与salt,但这2个软件都需要安装客户端,并且更新很快,每次更新都是令人蛋疼的事,尤其是salt,喜欢他的命令功能,但bug太多,不敢在公司线上使用,puppet虽然稳定,但弄命令执行的时候,需要mco配置,非常麻烦,我公司由于跟多家公司合作,很多业务没办法安装客户端,所以没办法使用puppet与salt(虽然salt有ssh,但不太好使),最后找到了ansible,他既有命令执行也有配置管理,关键开发它的语言是python,paramiko进行ssh连接,跟我之前开发的自动
-
集群运维自动化工具ansible使用playbook安装mysql
上次介绍了如何使用ansible playbook安装zabbix客户端(http://www.jb51.net/article/52158.htm),这次介绍一下如何使用playbook安装mysql. 下面是安装mysql的信息: mysql_basedir: /data/mysql/basedir 源码目录 mysql_datadir: /data/mysql/datadir 数据目录 mysql_user: mysql mysql用户 mysql_database_user: root
-
Linux运维工具Supervisor的安装使用(进程管理工具)
一.介绍 Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启.目前Supervisor可以运行在大多数Unix系统上,但不支持在Windows系统上运行.Supervisor需要Python2.4及以上版本,但任何Python 3版本都不支持. 二.自带Web管理程序 Supervisor有四个组件: 1. supervisord 运行Supervisor的后台服务,它用来启动和管理那些你需要Sup
-
深入浅析Linux轻量级自动运维工具-Ansible
转自 Linux轻量级自动运维工具-Ansible浅析 - ~微风~ - 51CTO技术博客 http://weiweidefeng.blog.51cto.com/1957995/1895261 Ansible是什么? ansible架构图 ansible特性 模块化:调用特定的模块,完成特定的任务: 基于Python语言研发,由Paramiko, PyYAML和Jinja2三个核心库实现: 部署简单:agentless: 支持自定义模块,使用任意编程语言: 强大的playbook机制: 幂等性
-
10大HBase常见运维工具整理小结
摘要:HBase自带许多运维工具,为用户提供管理.分析.修复和调试功能.本文将列举一些常用HBase工具,开发人员和运维人员可以参考本文内容,利用这些工具对HBase进行日常管理和运维. HBase组件介绍 HBase作为当前比较热门和广泛使用的NoSQL数据库,由于本身设计架构和流程上比较复杂,对大数据经验较少的运维人员门槛较高,本文对当前HBase上已有的工具做一些介绍以及总结. 写在前面的说明: 1) 由于HBase不同版本间的差异性较大(如HBase2.x上移走了hbck工具),本文使用
-
python ansible自动化运维工具执行流程
ansible 简介 ansible 是什么? ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.chef.func.fabric)的优点,实现了批量系统配置.批量程序部署.批量运行命令等功能. ansible是基于 paramiko 开发的,并且基于模块化工作,本身没有批量部署的能力.真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架.ansible不需要在远程主机上安装client/agents,因为它们是基于ssh来
-
python开发的自动化运维工具ansible详解
目录 ansible 简介 ansible 是什么? ansible 特点 ansible 架构图 ansible 任务执行 ansible 任务执行模式 ansible 执行流程 ansible 命令执行过程 ansible 配置详解 ansible 安装方式 使用 pip(python的包管理模块)安装 使用 yum 安装 ansible 程序结构 ansible配置文件查找顺序 ansible配置文件 ansuble主机清单 ansible 常用命令 ansible 命令集 ansible
-
linux系列之常用运维命令整理笔录(小结)
本博客记录工作中需要的linux运维命令,大学时候开始接触linux,会一些基本操作,可是都没有整理起来,加上是做开发,不做运维,有些命令忘记了,所以现在整理成博客,当然vi,文件操作等就不介绍了,慢慢积累一些其它拓展的命令,博客不定时更新 一.系统监控 1.free命令 free 命令能够显示系统中物理上的空闲和已用内存,还有交换内存,同时,也能显示被内核使用的缓冲和缓存 语法:free [param] param可以为: -b:以Byte为单位显示内存使用情况: -k:以KB为单位显示内存使
-
python常用运维脚本实例小结
一.ps 可以查看进程的内存占用大小,写一个脚本计算一下所有进程所占用内存大小的和. (提示,使用ps aux 列出所有进程,过滤出RSS那列,然后求和) 注:ps -ef 与 ps aux 效果一样使用随意 import os list = [] sum = 0 str1 = os.popen('ps aux','r').readlines() for i in str1: str2 = i.split() new_rss = str2[5] list.append(new_rss) for
-
运维的85条规则
1.容量第一,优化第二--这条规则在故障发生时生效.在宕机的时候别研究什么优化,先恢复设备. 2.保留所有可以捕获的记录--以 PostgresQL 为例,包括有 WAL 文件,Slony 复制,快照技术,基于硬盘的 DB 版本(快照附带的) 3.不要因为优化引入更多问题.通常我们解决问题时做出来的东西都会转变成之后运维工作的负担.请确认为运维工作开发的那些工具已经完全交付使用.这些东西经常无法正常运行结果要返回开发组重来.更重要的,这种变更请求通常会打破团队原本安排好的工作计划. 4.保持简单
-
linux系统Ansible自动化运维部署方法
ansible是新出现的 自动化 运维工具 , 基于Python研发 . 整合了众多老牌运维工具的优点实现了批量操作系统配置.批量程序的部署.批量运行命令等功能,下面就看一下如何部署 在命令行,提取Ansible源代码,git clone git://github.com/ansible/ansible.git --recursive 如下图所示 进入安装目录 cd ./ansible 目录下, 执行安装source ./hacking/env-setup -q 如果系统没有安装过pip,先安装