详解用Python爬虫获取百度企业信用中企业基本信息
一、背景
希望根据企业名称查询其经纬度,所在的省份、城市等信息。直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确。
百度企业信用提供了企业基本信息查询的功能。希望通过Python爬虫获取企业基本信息。目前已基本实现了这一需求。
本文最后会提供具体的代码。代码仅供学习参考,希望不要恶意爬取数据!
二、分析
以苏宁为例。输入“江苏苏宁”后,查询结果如下:
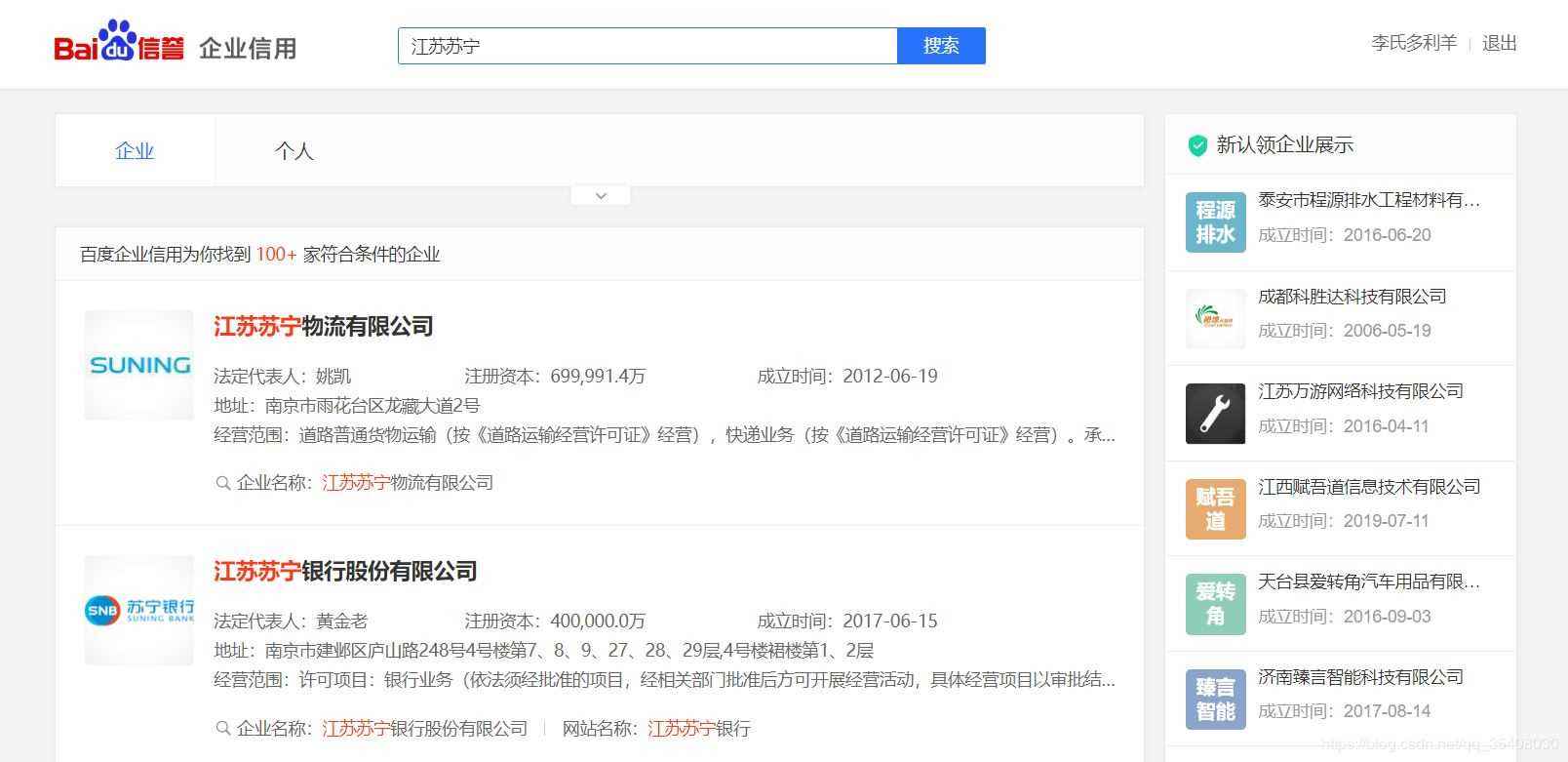
经过分析,这里列示的企业信息是用JavaScript动态生成的。服务器最初传过来的未经渲染的HTML如下:

注意其中标注出来的JS代码。有意思的是,企业基本信息都可以直接从这段JS代码中获取,无需构造复杂的参数。

这是进一步查看的结果,注意那个“resultList”,后面存放的就是页面中的企业信息。显然,利用正则表达式提取需要的字符串,转换成JSON就可以了。
三、源码
以下代码为查询某个企业的基本信息提供了API:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Author: Wild Orange
# @Email: jixuanfan_seu@163.com
# @Date: 2020-06-19 22:38:14
# @Last Modified time: 2020-07-01 17:33:13
import requests
import re
import json
headers={'User-Agent': 'Chrome/76.0.3809.132'}
#正则表达式提取数据
re_get_js=re.compile(r'<script>([\s\S]*?)</script>')
re_resultList=re.compile(r'"resultList":(\[{.+?}\]}])')
def Get_company_info(name):
'''
@func: 通过百度企业信用查询企业基本信息
'''
url='https://xin.baidu.com/s?q=%s'%name
res=requests.get(url,headers=headers)
if res.status_code==200:
html=res.text
retVal=_parse_baidu_company_info(html)
return retVal
else:
print('无法获取%s的企业信息'%name)
def _parse_baidu_company_info(html):
'''
@function:解析百度企业信用提供的企业基本信息
@output: list of dict, [{},{},...]
pid: 跳转到具体企业页面的参数
bid: 具体企业页面URL中的参数
name: 企业名称
type: 企业类型
date: 成立日期
address: 地址
person: 法人代表
status: 存续状态
regCap: 注册资本
scope: 经营范围
'''
js=re_get_js.findall(html)[1]
data=re_resultList.search(js)
if not data:
return
compant_list=json.loads(data.group(1))
retVal=[]
for x in compant_list:
regCap=x['regCap'].replace(',','')
if regCap[-1]=='万':
regCap=regCap[:-1]
regCap=float(regCap)
address=x['domicile'].replace('<em>','').replace('</em>','')
temp_v={'pid':x['pid'],'bid':x['bid'],'name':x['titleName'],'type':x['entType'],'date':x['validityFrom'],\
'address':address,'person':x['legalPerson'],'status':x['openStatus'],'regCap':regCap,\
'scope':x['scope']}
retVal.append(temp_v)
return retVal
四、使用方法
直接将需要查询的企业名称传入Get_company_info:
res=Get_company_info('江苏苏宁')
print(res)
结果:

需要注意的是:
返回的是字典构成的数组,每个字典元素代表一家企业的信息。顺序与浏览器中显示的顺序相同。字典中参数的含义已在_parse_baidu_company_info函数的注释中说明。程序仅获取第一页的信息。如果要查询多页,可以修改源码。程序仅获取企业的基本信息,没有进入企业的具体页面,如:苏宁物流具体页面。不过返回结果中的pid或bid应该能用于构造查询页面的URL。
最后再次强调:代码仅供学习参考,希望不要恶意爬取数据!
到此这篇关于详解用Python爬虫获取百度企业信用中企业基本信息的文章就介绍到这了,更多相关Python爬虫获取百度企业信用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫实例_利用百度地图API批量获取城市所有的POI点
上篇关于爬虫的文章,我们讲解了如何运用Python的requests及BeautifuiSoup模块来完成静态网页的爬取,总结过程,网页爬虫本质就两步: 1.设置请求参数(url,headers,cookies,post或get验证等)访问目标站点的服务器: 2.解析服务器返回的文档,提取需要的信息. 而API的工作机制与爬虫的两步类似,但也有些许不同: 1.API一般只需要设置url即可,且请求方式一般为"get"方式 2.API服务器返回的通常是json或xml格式的数据,解析更简
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
Python爬虫获取图片并下载保存至本地的实例
1.抓取煎蛋网上的图片. 2.代码如下: import urllib.request import os #to open the url def url_open(url): req=urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0') response=urllib.request.u
-
python爬虫获取淘宝天猫商品详细参数
首先我是从淘宝进去,爬取了按销量排序的所有(100页)女装的列表信息按综合.销量分别爬取淘宝女装列表信息,然后导出前100商品的 link,爬取其详细信息.这些商品有淘宝的,也有天猫的,这两个平台有些区别,处理的时候要注意.比如,有的说"面料".有的说"材质成分",其实是一个意思,等等.可以取不同的链接做一下测试. import re from collections import OrderedDict from bs4 import BeautifulSoup
-

使用python爬虫获取黄金价格的核心代码
继续练手,根据之前获取汽油价格的方式获取了金价,暂时没钱投资,看看而已 #!/usr/bin/env python # -*- coding: utf-8 -*- """ 获取每天黄金价格 @author: yufei @site: http://www.antuan.com 2017-05-11 """ import re import urllib2,urllib import random import threading import t
-
Python爬虫学习之获取指定网页源码
本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1.任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方法,只有将网页源码抓取下来才能从中提取我们需要的数据. 2.任务代码 Python获取指定网页源码的方法较为简单,我在Java中使用了38行代码才获取了网页源码(大概是学艺不精),而Python中只用了6行就达到了效果. Python中获取网页
-
python3爬虫获取html内容及各属性值的方法
今天用到BeautifulSoup解析爬下来的网页数据 首先导入包from bs4 import BeautifulSoup 然后可以利用urllib请求数据 记得要导包 import urllib.request 然后调用urlopen,读取数据 f=urllib.request.urlopen('http://jingyan.baidu.com/article/455a9950bc94b8a166277898.html') response=f.read() 这里我们就不请求数据了,直接用本
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
python爬虫获取百度首页内容教学
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它.现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首页信息. 1.首先我们创建一个urllib2_test01.py,然后输入以下代码: 2.最简单的获取一个url的信息代码居然只需要4行,执行写的python代码: 3.之后我们会看到一下的结果 4. 实际上,如果我们在浏览器上打开网页主页的话,右键选择"查看源代码",你会发现,跟我们刚打印出来的是一模
-
详解用Python调用百度地图正/逆地理编码API
一.背景 (正)地理编码指的是:将地理位置名称转换成经纬度: 逆地理编码指的是:将经纬度转换成地理位置信息,如地名.所在的省份或城市等 百度地图提供了相应的API,可以方便调用.相应的说明文档如下: 正地理编码 逆地理编码 具体API的参数可以查看相应的"服务文档": 不过首次使用时需要申请,具体在控制台.申请AK的方式可参见其他文章. 二.源码 废话不多说,直接放源码.这里提供了Python调用这两个API的方法. #!/usr/bin/env python # -*- coding
-
Python爬虫获取页面所有URL链接过程详解
如何获取一个页面内所有URL链接?在Python中可以使用urllib对网页进行爬取,然后利用Beautiful Soup对爬取的页面进行解析,提取出所有的URL. 什么是Beautiful Soup? Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换
-
Python爬虫实现百度图片自动下载
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载. 搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看: 随便搜索几个关键字,可以看到已经搜索出来很多张图片: 分析网页 我们点击右键,查看源代码: 打开源代码之后,发现一堆源代码比较难找出我们想要的资源. 这个时候,就
-
Python爬虫获取整个站点中的所有外部链接代码示例
收集所有外部链接的网站爬虫程序流程图 下例是爬取本站python绘制条形图方法代码详解的实例,大家可以参考下. 完整代码: #! /usr/bin/env python #coding=utf-8 import urllib2 from bs4 import BeautifulSoup import re import datetime import random pages=set() random.seed(datetime.datetime.now()) #Retrieves a list
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测
-
详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
python爬虫之百度API调用方法
调用百度API获取经纬度信息. import requests import json address = input('请输入地点:') par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'} url = 'http://restapi.amap.com/v3/geocode/geo' res = requests.get(url, par) json_data = json.loads(res.text) g