PyTorch使用GPU训练的两种方法实例
目录
- Pytorch 使用GPU训练
- 方法一 .cuda()
- 方法二 .to(device)
- 附:一些和GPU有关的基本操作汇总
- 总结
Pytorch 使用GPU训练
使用 GPU 训练只需要在原来的代码中修改几处就可以了。
我们有两种方式实现代码在 GPU 上进行训练
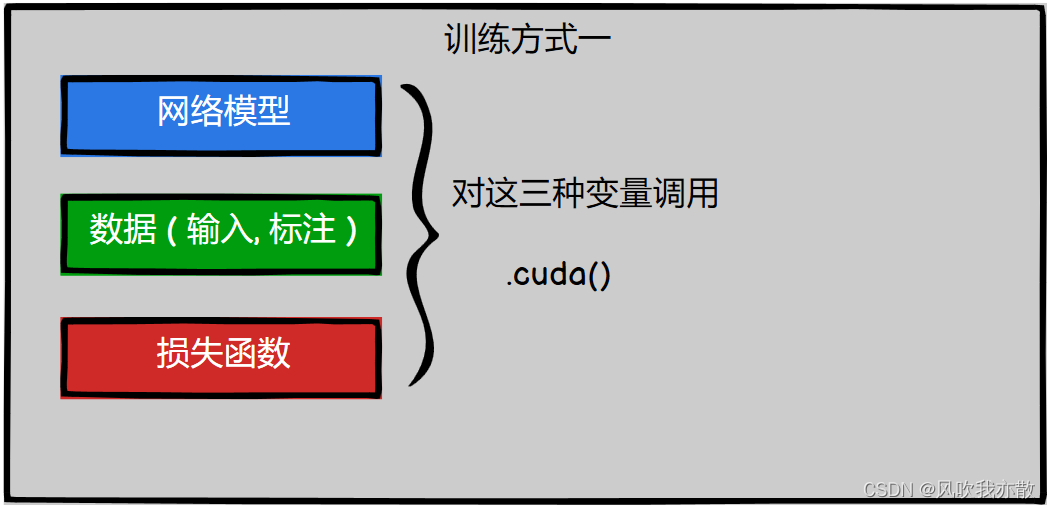
方法一 .cuda()
我们可以通过对网络模型,数据,损失函数这三种变量调用 .cuda() 来在GPU上进行训练
# 将网络模型在gpu上训练 model = Model() model = model.cuda() # 损失函数在gpu上训练 loss_fn = nn.CrossEntropyLoss() loss_fn = loss_fn.cuda() # 数据在gpu上训练 for data in dataloader: imgs, targets = data imgs = imgs.cuda() targets = targets.cuda()
但是如果电脑没有 GPU 就会报错,更好的写法是先判断 cuda 是否可用:
# 将网络模型在gpu上训练
model = Model()
if torch.cuda.is_available():
model = model.cuda()
# 损失函数在gpu上训练
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 数据在gpu上训练
for data in dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
代码案例:
# 以 CIFAR10 数据集为例,展示一下完整的模型训练套路,完成对数据集的分类问题
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 获得数据集的长度 len(), 即length
train_data_size = len(train_data)
test_data_size = len(test_data)
# 格式化字符串, format() 中的数据会替换 {}
print("训练数据集及的长度为: {}".format(train_data_size))
print("测试数据集及的长度为: {}".format(test_data_size))
# 利用DataLoader 来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, input):
input = self.model(input)
return input
model = Model()
if torch.cuda.is_available():
model = model.cuda() # 在 GPU 上进行训练
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 在 GPU 上进行训练
# 优化器
learning_rate = 1e-2 # 1e-2 = 1 * (10)^(-2) = 1 / 100 = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time() # 开始训练的时间
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda() # 在gpu上训练
outputs = model(imgs) # 将训练的数据放入
loss = loss_fn(outputs, targets) # 得到损失值
optimizer.zero_grad() # 优化过程中首先要使用优化器进行梯度清零
loss.backward() # 调用得到的损失,利用反向传播,得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1 # 上面就是进行了一次训练,训练次数 +1
# 只有训练步骤是100 倍数的时候才打印数据,可以减少一些没有用的数据,方便我们找到其他数据
if total_train_step % 100 == 0:
end_time = time.time() # 训练结束时间
print("训练时间: {}".format(end_time - start_time))
print("训练次数: {}, Loss: {}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 如何知道模型有没有训练好,即有咩有达到自己想要的需求
# 我们可以在每次训练完一轮后,进行一次测试,在测试数据集上跑一遍,以测试数据集上的损失或正确率评估我们的模型有没有训练好
# 顾名思义,下面的代码没有梯度,即我们不会利用进行调优
total_test_loss = 0
total_accuracy = 0 # 准确率
with torch.no_grad():
for data in test_dataloader: # 测试数据集中取数据
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 在 GPU 上进行训练
targets = targets.cuda()
outputs = model(imgs)
loss = loss_fn(outputs, targets) # 这里的 loss 只是一部分数据(data) 在网络模型上的损失
total_test_loss = total_test_loss + loss # 整个测试集的loss
accuracy = (outputs.argmax(1) == targets).sum() # 分类正确个数
total_accuracy += accuracy # 相加
print("整体测试集上的loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_loss += 1 # 测试完了之后要 +1
torch.save(model, "model_{}.pth".format(i))
print("模型已保存")
writer.close()
方法二 .to(device)
指定 训练的设备
device = torch.device("cpu") # 使用cpu训练
device = torch.device("cuda") # 使用gpu训练
device = torch.device("cuda:0") # 当电脑中有多张显卡时,使用第一张显卡
device = torch.device("cuda:1") # 当电脑中有多张显卡时,使用第二张显卡
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
使用 GPU 训练
model = model.to(device)
loss_fn = loss_fn.to(device)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
代码示例:
# 以 CIFAR10 数据集为例,展示一下完整的模型训练套路,完成对数据集的分类问题
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 定义训练的设备
device = torch.device("cuda")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 获得数据集的长度 len(), 即length
train_data_size = len(train_data)
test_data_size = len(test_data)
# 格式化字符串, format() 中的数据会替换 {}
print("训练数据集及的长度为: {}".format(train_data_size))
print("测试数据集及的长度为: {}".format(test_data_size))
# 利用DataLoader 来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, input):
input = self.model(input)
return input
model = Model()
model = model.to(device) # 在 GPU 上进行训练
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # 在 GPU 上进行训练
# 优化器
learning_rate = 1e-2 # 1e-2 = 1 * (10)^(-2) = 1 / 100 = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time() # 开始训练的时间
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs) # 将训练的数据放入
loss = loss_fn(outputs, targets) # 得到损失值
optimizer.zero_grad() # 优化过程中首先要使用优化器进行梯度清零
loss.backward() # 调用得到的损失,利用反向传播,得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1 # 上面就是进行了一次训练,训练次数 +1
# 只有训练步骤是100 倍数的时候才打印数据,可以减少一些没有用的数据,方便我们找到其他数据
if total_train_step % 100 == 0:
end_time = time.time() # 训练结束时间
print("训练时间: {}".format(end_time - start_time))
print("训练次数: {}, Loss: {}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 如何知道模型有没有训练好,即有咩有达到自己想要的需求
# 我们可以在每次训练完一轮后,进行一次测试,在测试数据集上跑一遍,以测试数据集上的损失或正确率评估我们的模型有没有训练好
# 顾名思义,下面的代码没有梯度,即我们不会利用进行调优
total_test_loss = 0
total_accuracy = 0 # 准确率
with torch.no_grad():
for data in test_dataloader: # 测试数据集中取数据
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, targets) # 这里的 loss 只是一部分数据(data) 在网络模型上的损失
total_test_loss = total_test_loss + loss # 整个测试集的loss
accuracy = (outputs.argmax(1) == targets).sum() # 分类正确个数
total_accuracy += accuracy # 相加
print("整体测试集上的loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_loss += 1 # 测试完了之后要 +1
torch.save(model, "model_{}.pth".format(i))
print("模型已保存")
writer.close()
【注】对于网络模型和损失函数,直接调用 .cuda() 或者 .to() 即可。但是数据和标注需要返回变量
为了方便记忆,最好都返回变量
使用Google colab进行训练
附:一些和GPU有关的基本操作汇总
# 1,查看gpu信息
if_cuda = torch.cuda.is_available()
print("if_cuda=",if_cuda)
# GPU 的数量
gpu_count = torch.cuda.device_count()
print("gpu_count=",gpu_count)
# 2,将张量在gpu和cpu间移动
tensor = torch.rand((100,100))
tensor_gpu = tensor.to("cuda:0") # 或者 tensor_gpu = tensor.cuda()
print(tensor_gpu.device)
print(tensor_gpu.is_cuda)
tensor_cpu = tensor_gpu.to("cpu") # 或者 tensor_cpu = tensor_gpu.cpu()
print(tensor_cpu.device)
# 3,将模型中的全部张量移动到gpu上
net = nn.Linear(2,1)
print(next(net.parameters()).is_cuda)
net.to("cuda:0") # 将模型中的全部参数张量依次到GPU上,注意,无需重新赋值为 net = net.to("cuda:0")
print(next(net.parameters()).is_cuda)
print(next(net.parameters()).device)
# 4,创建支持多个gpu数据并行的模型
linear = nn.Linear(2,1)
print(next(linear.parameters()).device)
model = nn.DataParallel(linear)
print(model.device_ids)
print(next(model.module.parameters()).device)
#注意保存参数时要指定保存model.module的参数
torch.save(model.module.state_dict(), "./data/model_parameter.pkl")
linear = nn.Linear(2,1)
linear.load_state_dict(torch.load("./data/model_parameter.pkl"))
# 5,清空cuda缓存
# 该方在cuda超内存时十分有用
torch.cuda.empty_cache()
总结
到此这篇关于PyTorch使用GPU训练的两种方法的文章就介绍到这了,更多相关PyTorch使用GPU训练内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验. 多GPU训练 cifar10_97.23 使用 run.sh 文件开始训练 cifar10_97.50 使用 run.4GPU.sh 开始训练 在集群中改变GPU调用个数修改 run.sh 文件 nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU & 修改 –gres=gpu:
-
用Pytorch训练CNN(数据集MNIST,使用GPU的方法)
听说pytorch使用比TensorFlow简单,加之pytorch现已支持windows,所以今天装了pytorch玩玩,第一件事还是写了个简单的CNN在MNIST上实验,初步体验的确比TensorFlow方便. 参考代码(在莫烦python的教程代码基础上修改)如下: import torch import torch.nn as nn from torch.autograd import Variable import torch.utils.data as Data import tor
-
pytorch使用指定GPU训练的实例
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练. 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误. 解决方案如下: 指定环境变量,屏蔽第0块gpu CUDA_VISIBLE_DEVICES = 1 main.py 这句话表示只有第1块
-
pytorch使用horovod多gpu训练的实现
pytorch在Horovod上训练步骤分为以下几步: import torch import horovod.torch as hvd # Initialize Horovod 初始化horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) 分配到每个gpu上 torch.cuda.set_device(hvd.local_rank()) # Define dataset... 定义d
-
pytorch 如何在GPU上训练
1.网络模型转移到CUDA上 net = AlexNet() net.cuda()#转移到CUDA上 2.将loss转移到CUDA上 criterion = nn.CrossEntropyLoss() criterion = criterion.cuda() 这一步不做也可以,因为loss是根据out.label算出来的 loss = criterion(out, label) 只要out.label在CUDA上,loss自然也在CUDA上了,但是发现不转移到CUDA上准确率竟然降低了1% 3.
-
解决pytorch多GPU训练保存的模型,在单GPU环境下加载出错问题
背景 在公司用多卡训练模型,得到权值文件后保存,然后回到实验室,没有多卡的环境,用单卡训练,加载模型时出错,因为单卡机器上,没有使用DataParallel来加载模型,所以会出现加载错误. 原因 DataParallel包装的模型在保存时,权值参数前面会带有module字符,然而自己在单卡环境下,没有用DataParallel包装的模型权值参数不带module.本质上保存的权值文件是一个有序字典. 解决方法 1.在单卡环境下,用DataParallel包装模型. 2.自己重写Load函数,灵活.
-
pytorch 使用单个GPU与多个GPU进行训练与测试的方法
如下所示: device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#第一行代码 model.to(device)#第二行代码 首先是上面两行代码放在读取数据之前. mytensor = my_tensor.to(device)#第三行代码 然后是第三行代码.这句代码的意思是将所有最开始读取数据时的tersor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上
-
pytorch 指定gpu训练与多gpu并行训练示例
一. 指定一个gpu训练的两种方法: 1.代码中指定 import torch torch.cuda.set_device(id) 2.终端中指定 CUDA_VISIBLE_DEVICES=1 python 你的程序 其中id就是你的gpu编号 二. 多gpu并行训练: torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) 该函数实现了在module级别上的数据并行使用,注意batch size要大于G
-

详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个
-
pytorch 两个GPU同时训练的解决方案
使用场景 我有两个GPU卡.我希望我两个GPU能并行运行两个网络模型. 代码 错误代码1: #对于0号GPU os.environ['CUDA_VISIBLE_DEVICES']='0,1' device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #对于1号GPU os.environ['CUDA_VISIBLE_DEVICES']='0,1' device = torch.de