基于云服务MRS构建DolphinScheduler2调度系统
目录
- 为什么写这篇文章?
- 环境准备
- 安装MRS 客户端
- 安装MySQL服务
- 1. 创建ECS用户
- 2.解压安装包
- 3. 配置文件初始化
- 4. 启动数据库
- 5.登陆,修改密码,预置dolphinscheduler的用户
- 安装dolphinscheduler服务
- 1. 建立本机id免密
- 2. 修改配置参数
- 3. 将mysql 驱动包放入lib下
- 5. 服务安装、启停
- 6. 登录系统
- 3. 创建任务
为什么写这篇文章?
- 网上关于DolphinScheduler的介绍很多但是都缺少了与实际大数据平台结合的案例指导。
- DolphinScheduler1.x版本,2.x重构了内核实现,性能提升20倍!但是因为重构导致2.x与1.x部署过程存在差异,按照1.x部署2.x版本存在不少坑。
- 选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建DolphinScheduler再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
环境准备
- dolphinscheduler2.0.3安装包
- MRS 3.1.0普通集群
- Mysql安装包 5.7.35
- ECS centos7.6
安装MRS 客户端
MRS客户端提供java、python开发环境,也提供开通集群中各组件的环境变量:Hadoop、hive、hbase、flink等。
参见登录ECS安装集群外客户端
安装MySQL服务
1. 创建ECS用户
为了方便数据库管理,对于安装的MySQL数据库,生产上建立了一个mysql用户和mysql用户组:
# 添加mysql用户组 groupadd mysql # 添加mysql用户 useradd -g mysql mysql -d /home/mysql # 修改mysql用户的登陆密码 passwd ****
2.解压安装包
``` cd /usr/local/ tar -xzvf mysql-5.7.13-linux-glibc2.5-x86_64.tar.gz # 改名为mysql mv mysql-5.7.13-linux-glibc2.5-x86_64 mysql ```
赋予用户读写权限
chown -R mysql:mysql mysql/
3. 配置文件初始化
1. 创建配置文件my.cnf
``` vim /etc/my.cnf [client] port = 3306 socket = /tmp/mysql.sock [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' basedir=/usr/local/mysql datadir=/usr/local/mysql/data socket=/tmp/mysql.sock log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid #不区分大小写 lower_case_table_names = 1 sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION max_connections=5000 default-time_zone = '+8:00' ```
2. 初始化log文件,防止没有权限
``` #手动编辑一下日志文件,什么也不用写,直接保存退出 cd /var/log/ vim mysqld.log :wq 退出保存 chmod 777 mysqld.log chown mysql:mysql mysqld.log ```
3. 初始化pid文件,防止没有权限
``` cd /var/run/ mkdir mysqld cd mysqld vi mysqld.pid :wq保存退出 # 赋权 cd .. chmod 777 mysqld chown -R mysql:mysql /mysqld ```
4. 初始化数据库
初始化数据库,并指定启动mysql的用户,否则就会在启动MySQL时出现权限不足的问题
/usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --lc_messages_dir=/usr/local/mysql/share --lc_messages=en_US
初始化完成后,在my.cnf中配置的datadir目录(/var/log/mysqld.log)下生成一个error.log文件,里面记录了root用户的随机密码。
cat /var/log/mysqld.log
执行后记录最后一行:root@localhost: xxxxx 。 这里的xxxxx就是初始密码。后面登入数据库要用到。
4. 启动数据库
#源目录启动: /usr/local/mysql/support-files/mysql.server start
设置开机自启动服务
# 复制启动脚本到资源目录 cp /usr/local/mysql/support-files/mysql.server /etc/rc.d/init.d/mysqld # 增加mysqld服务控制脚本执行权限 chmod +x /etc/rc.d/init.d/mysqld # 将mysqld服务加入到系统服务 chkconfig --add mysqld # 检查mysqld服务是否已经生效 chkconfig --list mysqld # 切换至mysql用户,启动mysql,或者稍后下一步再启动。 service mysqld start # 从此就可以使用service mysqld命令启动/停止服务 su mysql service mysqld start service mysqld stop service mysqld restart
5.登陆,修改密码,预置dolphinscheduler的用户
1. 修改密码
```
# 系统默认会查找/usr/bin下的命令;建立一个链接文件。
ln -s /usr/local/mysql/bin/mysql /usr/bin
# 登陆mysql的root用户
mysql -uroot -p
# 输入上面的默认初始密码(root@localhost: xxxxx)
# 修改root用户密码为XXXXXX
set password for root@localhost=password("XXXXXX");
```
2. 预置dolphinscheduler的用户
```
mysql -uroot -p
mysql>CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 修改 {user} 和 {password} 为你希望的用户名和密码,192.168.56.201是我的主机ID
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'192.168.56.201' IDENTIFIED BY 'dolphinscheduler';
#刷新权限
mysql> flush privileges;
#检查是否创建用户成功
mysql> show databases;
#出现dolphinscheduler,查看创建的用户
mysql> use mysql;
mysql> select User,authentication_string,Host from user;
```
安装dolphinscheduler服务
1. 建立本机id免密
在任意文件夹下进行这一步均可,为防止误会,我在dolphinscheduler203进行这一步,创建用户dolphinscheduler,后面所有操作都是再这个用户下做的。设置root免密登录该用户:
# 创建用户需使用 root 登录 useradd dolphinscheduler # 添加密码 echo "dolphinscheduler" | passwd --stdin dolphinscheduler # 配置 sudo 免密 sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers # 修改目录权限,在这一步前将jdbcDriver(我的mysql版本5.6.1,driver版本8.0.16)放入lib里,一并修改权限 chown -R dolphinscheduler:dolphinscheduler dolphinscheduler203 #进入新用户 su dolphinscheduler ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys
2. 修改配置参数
修改install-config.conf文件
[dolphinscheduler@km1 dolphinscheduler203]$ vi conf/config/install-config.conf 修改: ips="192.168.56.201" masters="192.168.56.201" workers="192.168.56.201:default" alertServer="192.168.56.201" apiServers="192.168.56.201" pythonGatewayServers="192.168.56.201" # DolphinScheduler安装路径,如果不存在会创建,这里不能放你解压后的ds路径,放置后在运行代码时同名文件、文件夹会冲突导致消失 installPath="/opt/dolphinscheduler203" # 部署用户,填写在 **配置用户免密及权限** 中创建的用户 deployUser="dolphinscheduler" # --------------------------------------------------------- # DolphinScheduler ENV # --------------------------------------------------------- # 安装的JDK中 JAVA_HOME 所在的位置 javaHome="/opt/hadoopclient/JDK/jdk1.8.0_272" # --------------------------------------------------------- # Database # --------------------------------------------------------- # 数据库的类型,用户名,密码,IP,端口,元数据库db。其中 DATABASE_TYPE 目前支持 mysql, postgresql, H2 # 请确保配置的值使用双引号引用,否则配置可能不生效 DATABASE_TYPE="mysql" SPRING_DATASOURCE_URL="jdbc:mysql://192.168.56.201:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8" # 如果你不是以 dolphinscheduler/dolphinscheduler 作为用户名和密码的,需要进行修改 SPRING_DATASOURCE_USERNAME="dolphinscheduler" SPRING_DATASOURCE_PASSWORD="dolphinscheduler" # --------------------------------------------------------- # Registry Server # --------------------------------------------------------- # 注册中心地址,zookeeper服务的地址 registryServers="192.168.56.201:2181"
zk地址获取方式:
登录manager,访问zookeeper服务,copy管理ip即可(前提ECS与MRS集群网络已打通):

2. 修改 conf/env 目录下的 dolphinscheduler_env.sh
以相关用到的软件都安装在/opt/Bigdata/client下为例:
• export HADOOP_HOME=/opt/Bigdata/client/HDFS/Hadoop • export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/Hadoop • export SPARK_HOME2=/opt/Bigdata/client/Spark2x/spark • export PYTHON_HOME=/usr/bin/pytho • export JAVA_HOME=/opt/Bigdata/client/JDK/jdk1.8.0_272 • export HIVE_HOME=/opt/Bigdata/client/Hive/Beeline • export FLINK_HOME=/opt/Bigdata/client/Flink/flink • export DATAX_HOME=/xxx/datax/bin/datax.py • export PATH=$HADOOP_HOME/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$DATAX_HOME:$PATH
说明
- 这一步非常重要,例如 JAVA_HOME 和 PATH 是必须要配置的,没有用到的可以忽略或者注释掉
- 环境变量查找方式说明:假设MRS客户端安装在/opt/Bigdata/client
source /opt/client/bigdata_env HADOOP_HOME环境地址:通过echo $HADOOP_HOME获得 /opt/Bigdata/client/HDFS/Hadoop HADOOP_CONF_DIR:/opt/Bigdata/client/HDFS/Hadoop SPARK_HOME: 通过echo $SPARK_HOME获得/opt/Bigdata/client/Spark2x/spark JAVA_HOME: 通过echo $JAVA_HOME获得/opt/Bigdata/client/JDK/jdk1.8.0_272 HIVE_HOME:通过echo $HIVE_HOME获得/opt/Bigdata/client/Hive/Beeline FLINK_HOME:通过echo $FLINK_HOME 获得/opt/Bigdata/client/Flink/flink
3. 将mysql 驱动包放入lib下

tar -zxvf mysql-connector-java-5.1.47.tar.gz

cp mysql-connector-java-5.1.47.jar /opt/dolphinscheduler203/lib/
执行sh script/create-dolphinscheduler.sh
5. 服务安装、启停
每次启停都可以重新部署一次:sh install.sh
启停命令
# 一键停止集群所有服务 sh ./bin/stop-all.sh # 一键开启集群所有服务 sh ./bin/start-all.sh # 启停 Master sh ./bin/dolphinscheduler-daemon.sh stop master-server sh ./bin/dolphinscheduler-daemon.sh start master-server # 启停 Worker sh ./bin/dolphinscheduler-daemon.sh start worker-server sh ./bin/dolphinscheduler-daemon.sh stop worker-server # 启停 Api sh ./bin/dolphinscheduler-daemon.sh start api-server sh ./bin/dolphinscheduler-daemon.sh stop api-server # 启停 Logger sh ./bin/dolphinscheduler-daemon.sh start logger-server sh ./bin/dolphinscheduler-daemon.sh stop logger-server # 启停 Alert sh ./bin/dolphinscheduler-daemon.sh start alert-server sh ./bin/dolphinscheduler-daemon.sh stop alert-server # 启停 Python Gateway sh ./bin/dolphinscheduler-daemon.sh start python-gateway-server sh ./bin/dolphinscheduler-daemon.sh stop python-gateway-server
6. 登录系统
访问前端页面地址:http://xxx:12345/dolphinscheduler
用户名密码:admin/dolphinscheduler123

提交MRS任务1.登录进入dolphinscheduler webui

2. 配置MRS-hive连接
登录mrs manager查看hiveserver ip:

创建Hive数据连接,普通集群没有权限可以使用默认用户hive,如有需要可以使用在MRS里面已经创建的用户:

3. 创建任务
1、创建项目

2、创建工作流

3、在工作流编辑任务
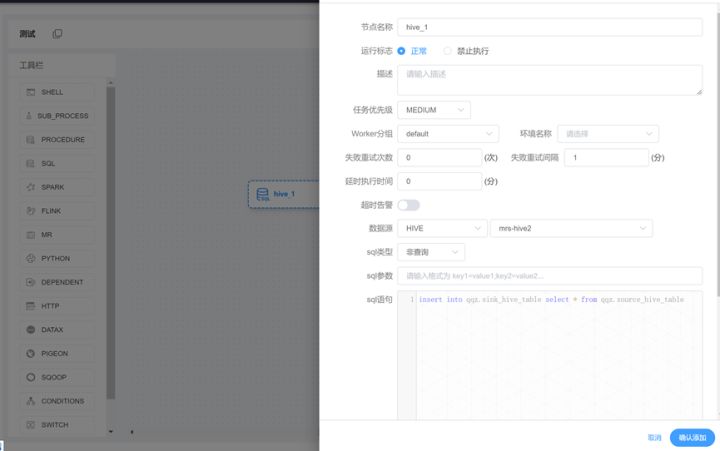
4、任务上线

5、启动任务流之后可以查询工作流实例和任务实例


6、登录Manager页面,选择“集群 > 服务 > Yarn > 概览”
7、单击“ResourceManager WebUI”后面对应的链接,进入Yarn的WebUI页面,查看Spark任务是否运行

到此这篇关于基于云服务MRS构建DolphinScheduler2调度系统的文章就介绍到这了,更多相关DolphinScheduler调度系统内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
阿里云服务器新建用户具体方法
一. 新建服务器用户: 用户管理,主要的工作就是建立一个合法的用户帐户.设置和管理用户的密码.修改用户帐户的属性以及在必要时删除已经废弃的用户帐号. 1)增加一个新用户 在Linux系统中,只有root用户才能够创建一个新用户,如下的命令将新建一个登录名user1的用户. #useradd user1 但是,这个用户还不能够登录,因为还没给它设置初始密码,而没有密码的用户是不能够登录系统的.在默认情况下,将会在/home目录下新建一个与用户名相同的用户主目录. 在Linux中,新增一个用户的同时
-

浅谈云服务器下如何选择操作系统
目录 Windows操作系统和Linux操作系统有何区别? Windows系统和Linux系统哪个更好,应该怎么选择? 华为云提供哪些版本的操作系统? 如果选错了云服务器的操作系统,怎么切换? Windows操作系统和Linux操作系统有何区别? Windows操作系统:需支付版权费用,(华为云已购买正版版权,在华为云购买云服务器的用户安装系统时无需额外付费),界面化的操作系统对用户使用习惯来说可能更容易上手:目前华为云提供的版本有2008版.2012版.2016版和2019版,并有英文和中文版
-
腾讯云服务器搭建Jenkins详细介绍
目录 一.连接腾讯云服务器 第二步:安装Tomcat 三.Jenkins部署 四.Jenkins安装 一.连接腾讯云服务器 1.Mac:(以ssh连接为例) 注意:IP地址为公网地址 ssh 用户名@IP地址 2.Windonws连接:详细说明 二.环境准备 第一步:安装Java 选择需要的java版本 yum list | grep openjdk 下载对应版本的java yum install java-1.8.0-openjdk.x86_64 第二步:安装Tomcat 可以选择要下载的版本
-
基于云服务MRS构建DolphinScheduler2调度系统
目录 为什么写这篇文章? 环境准备 安装MRS 客户端 安装MySQL服务 1. 创建ECS用户 2.解压安装包 3. 配置文件初始化 4. 启动数据库 5.登陆,修改密码,预置dolphinscheduler的用户 安装dolphinscheduler服务 1. 建立本机id免密 2. 修改配置参数 3. 将mysql 驱动包放入lib下 5. 服务安装.启停 6. 登录系统 3. 创建任务 为什么写这篇文章? 网上关于DolphinScheduler的介绍很多但是都缺少了与实际大数据平台结合
-
javaWeb项目部署到阿里云服务Linux系统的详细步骤
目录 项目部署到阿里云Linux系统 1.在虚拟机中创建一个指定安装软件的目录 2.安装项目部署的java1.8环境 2.1.上传文件 2.2.解压文件 1.运行前置目录查看是否有安装的jdk 2.运行命令进行解压并删除原来文件 2.3.配置JDK环境变量 3.RPM安装MySQL8.0.29数据库 3.1.官网下载地址 3.2.上传到Linux系统目录 1.解压文件 2.查看解压后的文件 3.3.执行安装操作 1.进行安装install 2.删除mariadb 3.执行安装rpm安装包(有先后
-
玩客云折腾记录之编译 ArmBian 系统
目录 写在前面 为什么选择搭载 Amlogic S805 的玩客云 系统选择及“源码溯源“ Armbian 官方代码 来自战斗民族的 Armbian TV 分支 来自阿拉伯网友 moham96 的分支 来自国内网友 leo357449107 的分支 来自国内网友 witallwang 的分支 品尝最新版本的 Armbian 整理“硬分叉”的代码 编译过程记录 构建不同代码分支.版本.内核的镜像 刷机前的准备 拆机过程细节记录 刷机过程细节记录 常见问题:刷入引导失败 常见问题:为什么要刷两次机
-
清平云 betweb云服务完美版虚拟主机自动化套件使用介绍
BET 是一套基于win平台上的web服务器 整合套件.BET 是一套快速部署web的软件.部署一台服务器快到只要30秒.BET 是一套全功能脚本环境.他可以支持php所有版本及aspx asp.不依赖任何3方软件.BET 是一套全平台软件,他包含了所有服务器(ftp,mysql,sqlserver,memcache,wincha,Zend所有组建)所以你无需再安装其他软件,直接启动就可以配置好所有服务及安全,运行环境配置最低可到 512m内存. betweb 云服务完美版(windows一键部
-
Django实现静态文件缓存到云服务的操作方法
一般与页面有关的系统都会有大量的静态文件,包括js.css以及图标图片等,这些文件一般是项目的相对路径,在加载的时候会从本地读取再转发出去.由于这类文件一般比较大,导致接口响应变长,但是这些文件一般很少改动,所以非常适合通过Nginx或者云服务来缓存.一般云服务与cdn无缝集成,能够更快下发到客户端.我们后台系统很多使用的是基于python的Django框架,该怎么来实现静态文件缓存呢? 这个过程简单的让人惊讶,但是开始一直搞不清楚关系,前前后后耽误了不少时间. 1.collectstatic命
-
基于MongoDB数据库索引构建情况全面分析
前面的话 本文将详细介绍MongoDB数据库索引构建情况分析 概述 创建索引可以加快索引相关的查询,但是会增加磁盘空间的消耗,降低写入性能.这时,就需要评判当前索引的构建情况是否合理.有4种方法可以使用 1.mongostat工具 2.profile集合介绍 3.日志 4.explain分析 mongostat mongostat是mongodb自带的状态检测工具,在命令行下使用.它会间隔固定时间获取mongodb的当前运行状态,并输出.如果发现数据库突然变慢或者有其他问题的话,首先就要考虑采用
-
基于Bootstrap和jQuery构建前端分页工具实例代码
前言 为啥名字叫[前端分页工具]?因为我实在想不到什么好名字,如果想要更加贴切的理解这个工具,应该从业务来看 业务是这样的,有一个数据从后台传到前台,因为数据量不大,因此传过来之后直接显示即可,但是=.=所谓的数据量不大,最多也达到成百上千条,不可能全部显示出来,那么就需要分页 常规的分页是利用Ajax,通过传页偏移量到后台,后台查询数据库再返回数据,可以实现无刷新分页,拿到的数据也是最新的 前端分页 优点:一次传输数据,避免用户反复请求服务器,减少网络带宽.服务器调度压力.数据库查询.缓存查询
-
asp.net基于windows服务实现定时发送邮件的方法
本文实例讲述了asp.net基于windows服务实现定时发送邮件的方法.分享给大家供大家参考,具体如下: //定义组件 private System.Timers.Timer time; public int nowhour; public int minutes; public string sendTime; public Thread th; public string isOpen;//是否启用定时发送 public string strToEUser; public static i
-
基于Vue2的独立构建与运行时构建的差别(详解)
其实这个问题在你使用vue-cli构建项目的时候是不会出现的,因为你在创建项目的构建过程中已经让你勾选了,然后会写入webpack.config.js中. 这就在这,会让你选择Vue的构建方式. 如果你勾选Runtime + Compiler就会出现如上的配置. 其实这里涉及到一个概念: 独立构建:含义是,拥有完整的模版编译功能和运行时调用功能 运行时构建:含义是,只拥有完整的运行时调用功能 为什么会有这种区分呢? 第一,因为Vue使用/运行过程分为两个阶段,第一阶段是将模版进行编译(如单个vu
-
基于Python实现简单的人脸识别系统
目录 前言 基本原理 代码实现 创建虚拟环境 安装必要的库 前言 最近又多了不少朋友关注,先在这里谢谢大家.关注我的朋友大多数都是大学生,而且我简单看了一下,低年级的大学生居多,大多数都是为了完成课程设计,作为一个过来人,还是希望大家平时能多抽出点时间学习一下,这种临时抱佛脚的策略要少用嗷.今天我们来python实现一个人脸识别系统,主要是借助了dlib这个库,相当于我们直接调用现成的库来进行人脸识别,就省去了之前教程中的数据收集和模型训练的步骤了. B站视频:用300行代码实现人脸识别系统_哔