C++ 浅谈emplace_back及使用误区
今天做c++ primer题目实现标准库vector,emplace_back忽然发现我对其了解甚少,首先,我在网上找到答案的代码,之前有过了解emplace_back是通过移动构造函数实现的,那么问题来了,如果我想实现vector<Base> b这样,我将其移动构造函数显式删除,那么
b.emplace_back(....),还能工作吗? 答案是 : 能
//Base.h
#include<string>
class Base
{
public:
Base() = default;
Base(std::string t,int m):s(t),i(m){}
Base(const Base& b):s(b.s),i(b.i){}
Base(Base&&) = delete;
private:
std::string s;
int i;
};
这似乎符合我们的期望,可当我尝试使用自定义的版本(也就是网上那些"高手"的,还是外国人放在github的,呵呵啦,害我找这么久原因,不是坑吗?) 自定义版本如下:
template<typename T>
template<class ...Args>
void
Vec<T>::emplace_back(Args&& ...args)
{
chk_n_alloc();
alloc.construct(first_free++, std::forward<Args>(args)...);
}
补充知识:C++11新特性,推荐使用emplace_back()替换push_back()的原因
c++11新加入了emplace_back()用来替换push_back():
在平时我们习惯性的尾插用push_back()去完成,但是如果是尾插临时对象的话,push_back()需要先构造临时对象,再将这个对象拷贝到容器的末尾,而emplace_back()则直接在容器的末尾构造对象,这样就省去了拷贝的过程。
分析如下代码:
#include<bits/stdc++.h>
using namespace std;
int i=0,j=0;
class A {
public:
A(int i){
str = to_string(i);
cout << "构造函数" <<++i<< endl;
}
~A(){}
A(const A& a): str(a.str){
cout << "拷贝构造" <<++j<< endl;
}
public:
string str;
};
int main(){
vector<A> vec;
vec.reserve(10);//开辟capacity
for(int i=0;i<10;i++){
vec.push_back(i); //调用了10次构造函数和10次拷贝构造函数,
// vec.emplace_back(i); //调用了10次构造函数一次拷贝构造函数都没有调用过
}
}
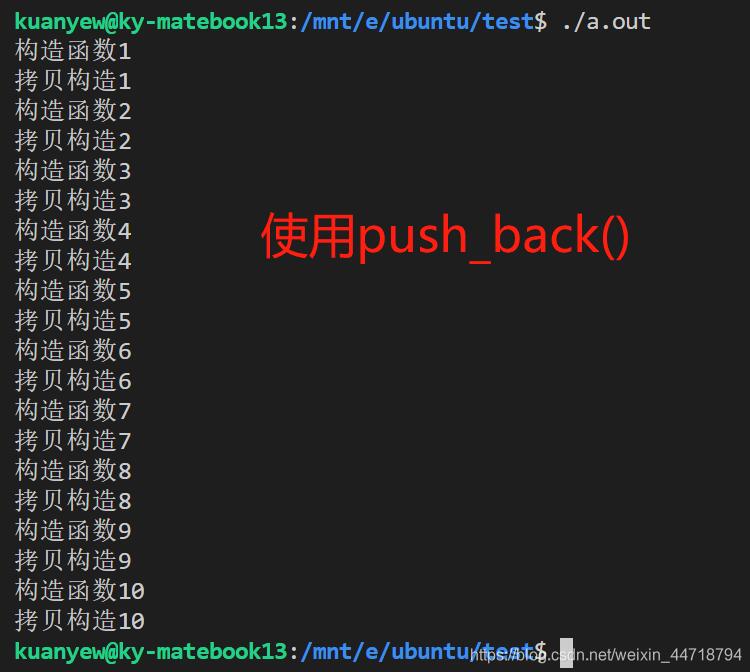

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方欢迎留言讨论,望不吝赐教。
相关推荐
-
C++ 中"emplace_back" 与 "push_back" 的区别
C++ 中"emplace_back" 与 "push_back" 的区别 emplace_back和push_back都是向容器内添加数据. 对于在容器中添加类的对象时, 相比于push_back,emplace_back可以避免额外类的复制和移动操作. "emplace_back avoids the extra copy or move operation required when using push_back." 参见: http:
-
C++ 获取URL内容的实例
我就废话不多说了,大家还是直接看代码吧~ 以下内容摘自StackOverFlow 链接 #ifndef HTTPUTIL_H #define HTTPUTIL_H #include <windows.h> #include <string> #include <stdio.h> using std::string; #pragma comment(lib,"ws2_32.lib") void mParseUrl(char *mUrl, string
-
c++ 判断是64位还是32位系统的实例
1.IsWow64Process 确定指定进程是否运行在64位操作系统的32环境(Wow64)下. 语法 BOOL WINAPI IsWow64Process( __in HANDLE hProcess, __out PBOOL Wow64Process ); 参数 hProcess 进程句柄.该句柄必须具有PROCESS_QUERY_INFORMATION 或者 PROCESS_QUERY_LIMITED_INFORMATION 访问权限 Wow64Process 指向一个bool值, 如果该
-
C++ 写的UrlEncode和UrlDecode实例
关于UrlEncode的实现(C++).网上有非常多不同的版本号.对须要编码的字符集的选取并不统一.那么究竟有没有标准呢?答案是有的. 绝对不编码的,仅仅有字母.数字.短横线(-).下划线(_).点(.)和波浪号(~),其它字符要视情况而定.所以一般性的urlencode仅仅需保留上述字符不进行编码. 以下给出实现: unsigned char ToHex(unsigned char x) { return x > 9 ? x + 55 : x + 48; } unsigned char Fro
-

c++仿函数和函数适配器的使用详解
所谓的仿函数(functor),是通过重载()运算符模拟函数形为的类. 因此,这里需要明确两点: 1 仿函数不是函数,它是个类: 2 仿函数重载了()运算符,使得它的对你可以像函数那样子调用(代码的形式好像是在调用函数). for_each 这里的for循环语句有点冗余,想到了std::for_each ,为了使用for_each,我们需要定义一个函数,如下: void print( State* pstate ) { pstate->print(); } 于是就可以简化为下面代码: std::
-
C++ 浅谈emplace_back及使用误区
今天做c++ primer题目实现标准库vector,emplace_back忽然发现我对其了解甚少,首先,我在网上找到答案的代码,之前有过了解emplace_back是通过移动构造函数实现的,那么问题来了,如果我想实现vector<Base> b这样,我将其移动构造函数显式删除,那么 b.emplace_back(....),还能工作吗? 答案是 : 能 //Base.h #include<string> class Base { public: Base() = default
-
浅谈DataFrame和SparkSql取值误区
1.DataFrame返回的不是对象. 2.DataFrame查出来的数据返回的是一个dataframe数据集. 3.DataFrame只有遇见Action的算子才能执行 4.SparkSql查出来的数据返回的是一个dataframe数据集. 原始数据 scala> val parquetDF = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet/part-r-00004.gz.parquet") df: or
-
浅谈JAVA 线程状态中可能存在的一些误区
BLOCKED 和 WAITING 的区别 BLOCKED 和 WAITING 两种状态从结果上来看,都是线程暂停,不会占用 CPU 资源,不过还是有一些区别的 BLOCKED 等待 Monitor 锁的阻塞线程的线程状态,处于阻塞状态的线程正在等待 Monitor 锁进入 synchronized Block 或者 Method ,或者在调用 Object.wait 后重新进入同步块/方法.简单的说,就是线程等待 synchronized 形式的锁时的状态 下面这段代码中, t1 在等待
-
浅谈五大Python Web框架
说到Web Framework,Ruby的世界Rails一统江湖,而Python则是一个百花齐放的世界,各种micro-framework.framework不可胜数,不完全列表见: http://wiki.python.org/moin/WebFrameworks 虽然另一大脚本语言PHP也有不少框架,但远没有Python这么夸张,也正是因为Python Web Framework(Python Web开发框架,以下简称Python框架)太多,所以在Python社区总有关于Python框架孰优
-
浅谈jQuery为哪般去掉了浏览器检测
由于做HTML5相关的项目,许多前卫时髦的前端技术就需要考虑一下IE是否支持.要是在以前,可以很方便地调用jQuery的jQuery.browser来实现. If(jQuery.browser.msie) alert("DIE IE!") 但这一便利在jQuery 1.9之后就不复存在了.突然觉得像失去了一个最亲密的战友,一个我一搞开发就离不开的好基友,一个我离开了就 无法写出跨浏览器的前端代码的好工具.一下子我竟不知道该如何是好. 然后每次需要考虑IE的时候,我就会去google一下
-
浅谈Java向下转型的意义
一开始学习 Java 时不重视向下转型.一直搞不清楚向下转型的意义和用途,不清楚其实就是不会,那开发的过程肯定也想不到用向下转型. 其实向上转型和向下转型都是很重要的,可能我们平时见向上转型多一点,向上转型也比较好理解. 但是向下转型,会不会觉得很傻,我是要用子类实例对象,先是生成子类实例赋值给父类引用,在将父类引用向下强转给子类 引用,这不是多此一举吗?我不向上转型也不向下转型,直接用子类实例就行了. 我开始学习Java时也是这么想的,这误区导致我觉得向下转型就是没用的. 随着技术的提升,我在
-
浅谈keras 模型用于预测时的注意事项
为什么训练误差比测试误差高很多? 一个Keras的模型有两个模式:训练模式和测试模式.一些正则机制,如Dropout,L1/L2正则项在测试模式下将不被启用. 另外,训练误差是训练数据每个batch的误差的平均.在训练过程中,每个epoch起始时的batch的误差要大一些,而后面的batch的误差要小一些.另一方面,每个epoch结束时计算的测试误差是由模型在epoch结束时的状态决定的,这时候的网络将产生较小的误差. [Tips]可以通过定义回调函数将每个epoch的训练误差和测试误差并作图,
-
浅谈Java中向上造型向下造型和接口回调中的问题
最近回顾了一下java继承中的问题,下面贴代码: public class Base { protected String temp = "base"; public void fun(){ System.out.print("BASE fun()"); } public static void main(String[] args) { Base b =new Base();//实例化Base对象 b.fun(); //调用父类中fun()的方法 System.o
-
浅谈C++11中的几种锁
目录 互斥锁(mutex) 条件锁(condition_variable) 自旋锁(不推荐使用) 递归锁(recursive_mutex) 互斥锁(mutex) 可以避免多个线程在某一时刻同时操作一个共享资源,标准C++库提供了std::unique_lock类模板,实现了互斥锁的RAII惯用语法:eg: std::unique_lock<std::mutex> lk(mtx_sync_); 条件锁(condition_variable) 条件锁就是所谓的条件变量,某一个线程因为某个条件未满足
-
浅谈MySQL聚簇索引
目录 1. 什么是聚簇索引 2. 聚簇索引和主键 3. 聚簇索引优缺点 4. 最佳实践 1. 什么是聚簇索引 数据库的索引从不同的角度可以划分成不同的类型,聚簇索引便是其中一种. 聚簇索引英文是 Clustered Index,有时候小伙伴们可能也会看到有人将之称为聚集索引等,与之相对的是非聚簇索引或者二级索引. 聚簇索引并不是一种单独的索引类型,而是一种数据的存储方式.在 MySQL 的 InnoDB 存储引擎中,所谓的聚簇索引实际上就是在同一个 B+Tree 中保存了索引和数据行:此时,数据