云计算实验:Java MapReduce编程
目录
- 【实验作业】简单流量统计
- 【实验作业】索引倒排输出行号
实验题目:
MapReduce:编程
实验内容:
本实验利用 Hadoop 提供的 Java API 进行编程进行 MapReduce 编程。
实验目标:
- 掌握
MapReduce编程。 - 理解
MapReduce原理
【实验作业】简单流量统计
有如下这样的日志文件:
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230513 00-FD-07-A4-72-B8:CMCC 120.196.40.8 i02.c.aliimg.com 248 0 200
13826230523 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230533 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230543 00-FD-07-A4-72-B8:CMCC 120.196.100.82 Video website 1527 2106 200
13926230553 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13826230563 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13926230573 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
18912688533 00-FD-07-A4-72-B8:CMCC 220.196.100.82 Integrated portal 1938 2910 200
18912688533 00-FD-07-A4-72-B8:CMCC 220.196.100.82 i02.c.aliimg.com 3333 21321 200
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 Search Engines 9531 9531 200
13826230523 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
该日志文件记录了每个手机用户在一段时间内的网络流量信息,具体字段含义为:
手机号码 MAC地址 IP地址 域名 上行流量(字节数) 下行流量(字节数) 套餐类型
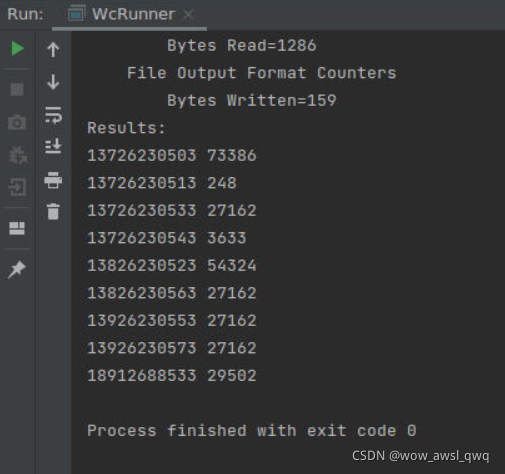
根据以上日志,统计出每个手机用户在该时间段内的总流量(上行流量+下行流量),统计结果的格式为:
手机号码 字节数量
实验结果:
实验代码:
WcMap.java
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String str = value.toString();
String[] words = StringUtils.split(str," ",10);
int i=0;
for(String word : words){
if(i==words.length-2||i==words.length-3)
context.write(new Text(words[0]), new LongWritable(Integer.parseInt(word)));
i++;
}
}
}
WcReduce.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long count = 0;
for(LongWritable value : values){
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
WcRunner.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
public class WcRunner{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WcRunner.class);
job.setMapperClass(WcMap.class);
job.setReducerClass(WcReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
Scanner sc = new Scanner(System.in);
System.out.print("inputPath:");
String inputPath = sc.next();
System.out.print("outputPath:");
String outputPath = sc.next();
try {
FileSystem fs0 = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path hdfsPath = new Path(outputPath);
fs0.copyFromLocalFile(new Path("/headless/Desktop/workspace/mapreduce/WordCount/data/1.txt"),new Path("/mapreduce/WordCount/input/1.txt"));
if(fs0.delete(hdfsPath,true)){
System.out.println("Directory "+ outputPath +" has been deleted successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));
job.waitForCompletion(true);
try {
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path srcPath = new Path(outputPath+"/part-r-00000");
FSDataInputStream is = fs.open(srcPath);
System.out.println("Results:");
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
【实验作业】索引倒排输出行号
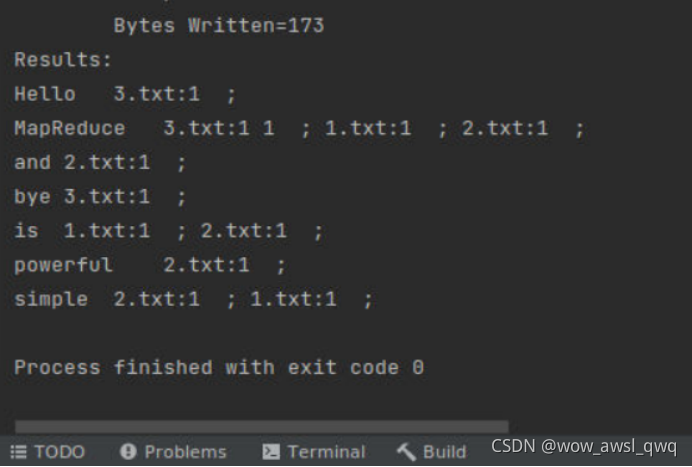
在索引倒排实验中,我们可以得到每个单词分布在哪些文件中,以及在每个文件中出现的次数,修改以上实现,在输出的倒排索引结果中可以得到每个单词在每个文件中的具体行号信息。输出结果的格式如下:
单词 文件名:行号,文件名:行号,文件名:行号
实验结果:
MapReduce在3.txt的第一行出现了两次所以有两个1
import java.io.*;
import java.util.StringTokenizer;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class MyMapper extends Mapper<Object,Text,Text,Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
int num=0;
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
num++;
split = (FileSplit)context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
keyInfo.set(itr.nextToken()+" "+split.getPath().getName().toString());
valueInfo.set(num+"");
context.write(keyInfo,valueInfo);
}
}
}
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
public class MyCombiner extends Reducer<Text,Text,Text,Text>{
private Text info = new Text();
public void reduce(Text key,Iterable<Text>values,Context context)
throws IOException, InterruptedException{
String sum = "";
for(Text value:values){
sum += value.toString()+" ";
}
String record = key.toString();
String[] str = record.split(" ");
key.set(str[0]);
info.set(str[1]+":"+sum);
context.write(key,info);
}
}
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
public void reduce(Text key,Iterable<Text>values,Context context) throws
IOException, InterruptedException{
String value =new String();
for(Text value1:values){
value += value1.toString()+" ; ";
}
result.set(value);
context.write(key,result);
}
}
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
public class MyRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MyRunner.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setCombinerClass(MyCombiner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
Scanner sc = new Scanner(System.in);
System.out.print("inputPath:");
String inputPath = sc.next();
System.out.print("outputPath:");
String outputPath = sc.next();
try {
FileSystem fs0 = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path hdfsPath = new Path(outputPath);
if(fs0.delete(hdfsPath,true)){
System.out.println("Directory "+ outputPath +" has been deleted successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));
job.waitForCompletion(true);
try {
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path srcPath = new Path(outputPath+"/part-r-00000");
FSDataInputStream is = fs.open(srcPath);
System.out.println("Results:");
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
到此这篇关于云计算实验:Java MapReduce编程的文章就介绍到这了,更多相关Java MapReduce编程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java函数式编程(七):MapReduce
译注:map(映射)和reduce(归约,化简)是数学上两个很基础的概念,它们很早就出现在各类的函数编程语言里了,直到2003年Google将其发扬光大,运用到分布式系统中进行并行计算后,这个组合的名字才开始在计算机界大放异彩(那些函数式粉可能并不这么认为).本文我们会看到Java 8在摇身一变支持函数式编程后,map和reduce组合的首次亮相(这里只是初步介绍,后续还会有针对它们的专题). 对集合进行归约 现在为止我们已经介绍了几个操作集合的新技巧了:查找匹配元素,查找单个元素,集合转化.这
-
java 矩阵乘法的mapreduce程序实现
java 矩阵乘法的mapreduce程序实现 map函数:对于矩阵M中的每个元素m(ij),产生一系列的key-value对<(i,k),(M,j,m(ij))> 其中k=1,2.....知道矩阵N的总列数;对于矩阵N中的每个元素n(jk),产生一系列的key-value对<(i , k) , (N , j ,n(jk)>, 其中i=1,2.......直到i=1,2.......直到矩阵M的总列数. map package com.cb.matrix; import stati
-

Java基础之MapReduce框架总结与扩展知识点
一.MapTask工作机制 MapTask就是Map阶段的job,它的数量由切片决定 二.MapTask工作流程: 1.Read阶段:读取文件,此时进行对文件数据进行切片(InputFormat进行切片),通过切片,从而确定MapTask的数量,切片中包含数据和key(偏移量) 2.Map阶段:这个阶段是针对数据进行map方法的计算操作,通过该方法,可以对切片中的key和value进行处理 3.Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputColle
-
java连接hdfs ha和调用mapreduce jar示例
Java API 连接 HDFS HA 复制代码 代码如下: public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop2cluster"); conf.set("dfs.nameservices", "hadoop2cluster");
-
Java/Web调用Hadoop进行MapReduce示例代码
Hadoop环境搭建详见此文章http://www.jb51.net/article/33649.htm. 我们已经知道Hadoop能够通过Hadoop jar ***.jar input output的形式通过命令行来调用,那么如何将其封装成一个服务,让Java/Web来调用它?使得用户可以用方便的方式上传文件到Hadoop并进行处理,获得结果.首先,***.jar是一个Hadoop任务类的封装,我们可以在没有jar的情况下运行该类的main方法,将必要的参数传递给它.input 和outpu
-
云计算实验:Java MapReduce编程
目录 [实验作业]简单流量统计 [实验作业]索引倒排输出行号 实验题目: MapReduce:编程 实验内容: 本实验利用 Hadoop 提供的 Java API 进行编程进行 MapReduce 编程. 实验目标: 掌握MapReduce编程. 理解MapReduce原理 [实验作业]简单流量统计 有如下这样的日志文件: 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200 13726
-
云计算实验:Java MapReduce编程
目录 [实验作业]简单流量统计 [实验作业]索引倒排输出行号 实验题目: MapReduce:编程 实验内容: 本实验利用 Hadoop 提供的 Java API 进行编程进行 MapReduce 编程. 实验目标: 掌握MapReduce编程. 理解MapReduce原理 [实验作业]简单流量统计 有如下这样的日志文件: 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200137262
-
Java并发编程Semaphore计数信号量详解
Semaphore 是一个计数信号量,它的本质是一个共享锁.信号量维护了一个信号量许可集.线程可以通过调用acquire()来获取信号量的许可:当信号量中有可用的许可时,线程能获取该许可:否则线程必须等待,直到有可用的许可为止. 线程可以通过release()来释放它所持有的信号量许可(用完信号量之后必须释放,不然其他线程可能会无法获取信号量). 简单示例: package me.socketthread; import java.util.concurrent.ExecutorService;
-
JAVA并发编程有界缓存的实现详解
JAVA并发编程有界缓存的实现 1.有界缓存的基类 package cn.xf.cp.ch14; /** * *功能:有界缓存实现基类 *时间:下午2:20:00 *文件:BaseBoundedBuffer.java *@author Administrator * * @param <V> */ public class BaseBoundedBuffer<V> { private final V[] buf; private int tail; private int head
-
Java 并发编程:volatile的使用及其原理解析
Java并发编程系列[未完]: •Java 并发编程:核心理论 •Java并发编程:Synchronized及其实现原理 •Java并发编程:Synchronized底层优化(轻量级锁.偏向锁) •Java 并发编程:线程间的协作(wait/notify/sleep/yield/join) •Java 并发编程:volatile的使用及其原理 一.volatile的作用 在<Java并发编程:核心理论>一文中,我们已经提到过可见性.有序性及原子性问题,通常情况下我们可以通过Synchroniz
-
Java多线程编程小实例模拟停车场系统
下面分享的是一个Java多线程模拟停车场系统的小实例(Java的应用还是很广泛的,哈哈),具体代码如下: Park类 public class Park { boolean []park=new boolean[3]; public boolean equals() { return true; } } Car: public class Car { private String number; private int position=0; public Car(String number)
-
Java并发编程之重入锁与读写锁
重入锁 重入锁,顾名思义,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁.重进入是指任意线程在获取到锁之后能够再次获取该锁而不会被锁阻塞,该特性的实现需要解决以下两个问题. 1.线程再次获取锁.锁需要去识别获取锁的线程是否为当前占据锁的线程,如果是,则再次成功获取. 2.锁的最终释放.线程重复n次获取了锁,随后在第n次释放该锁后,其他线程能够获取到该锁.锁的最终释放要求锁对于获取进行计数自增,计数表示当前锁被重复获取的次数,而锁被释放时,计数自减,当计数等于0时表示锁已经成功释放
-
Java多线程编程安全退出线程方法介绍
线程停止 Thread提供了一个stop()方法,但是stop()方法是一个被废弃的方法.为什么stop()方法被废弃而不被使用呢?原因是stop()方法太过于暴力,会强行把执行一半的线程终止.这样会就不会保证线程的资源正确释放,通常是没有给与线程完成资源释放工作的机会,因此会导致程序工作在不确定的状态下 那我们该使用什么来停止线程呢 Thread.interrupt(),我们可以用他来停止线程,他是安全的,可是使用他的时候并不会真的停止了线程,只是会给线程打上了一个记号,至于这个记号有什么用呢
-
Java Socket编程笔记_动力节点Java学院整理
对于即时类应用或者即时类的游戏,HTTP协议很多时候无法满足于我们的需求.这会,Socket对于我们来说就非常实用了.下面是本次学习的笔记.主要分异常类型.交互原理.Socket.ServerSocket.多线程这几个方面阐述. 异常类型 在了解Socket的内容之前,先要了解一下涉及到的一些异常类型.以下四种类型都是继承于IOException,所以很多之后直接弹出IOException即可. UnkownHostException: 主机名字或IP错误 ConnectException
-
Java并发编程:CountDownLatch与CyclicBarrier和Semaphore的实例详解
Java并发编程:CountDownLatch与CyclicBarrier和Semaphore的实例详解 在java 1.5中,提供了一些非常有用的辅助类来帮助我们进行并发编程,比如CountDownLatch,CyclicBarrier和Semaphore,今天我们就来学习一下这三个辅助类的用法. 以下是本文目录大纲: 一.CountDownLatch用法 二.CyclicBarrier用法 三.Semaphore用法 若有不正之处请多多谅解,并欢迎批评指正. 一.CountDownLatch