利用pandas进行数据清洗的方法
目录
- 1、完整性
- 1.1 缺失值
- 1.2 空行
- 2、全面性
- 列数据的单位不统一
- 3、合理性
- 非ASCII字符
- 4、唯一性
- 4.1 一列有多个参数
- 4.2 重复数据
我们有下面的一个数据,利用其做简单的数据分析。

这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。
数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”,下面来解释下:
- 完整性:单条数据是否存在空值,统计的字段是否完善。
- 全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
- 合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
- 唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
1、完整性
1.1 缺失值
一般情况下,由于数据量巨大,在采集数据的过程中,会出现有些数据单元没有被采集到,也就是数据存在缺失。通常面对这种情况,我们可以采用以下三种方法:
- 删除:删除数据缺失的记录
- 均值:使用当前列的均值填充
- 高频:使用当前列出现频率最高的数据
比如我们相对data[‘Age']中缺失的数值使用平均年龄进行填充,可以写:
df['Age'].fillna(df['Age'].mean(), inplace=True)
如果我们用最高频的数据进行填充,可以先通过 value_counts 获取 Age 字段最高频次 age_maxf,然后再对 Age 字段中缺失的数据用 age_maxf 进行填充:
age_maxf = train_features['Age'].value_counts().index[0] train_features['Age'].fillna(age_maxf, inplace=True)
1.2 空行
我们发现数据中有一个空行,除了 index 之外,全部的值都是 NaN。Pandas 的 read_csv() 并没有可选参数来忽略空行,这样,我们就需要在数据被读入之后再使用 dropna() 进行处理,删除空行。
# 删除全空的行 df.dropna(how='all',inplace=True)
2、全面性
列数据的单位不统一
如果某一列数据其单位并不统一,比如weight列,有的单位为千克(Kgs),有的单位是磅(Lbs)。
这里我们使用千克作为统一的度量单位,将磅转化为千克:
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
print df[rows_with_lbs]
# 将 lbs转换为 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取从头开始到倒数第三个字符之前,即去掉lbs。
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
3、合理性
非ASCII字符
假设在数据集中 Firstname 和 Lastname 有一些非 ASCII 的字符。我们可以采用删除或者替换的方式来解决非 ASCII 问题,这里我们使用删除方法,也就是用replace方法:
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
4、唯一性
4.1 一列有多个参数
假设姓名(Name)包含了两个参数 Firstname和Lastname。为了达到数据整洁的目的,我们将 Name 列拆分成 Firstname 和 Lastname 两个字段。我们使用 Python 的 split 方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
4.2 重复数据
我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
# 删除重复数据行 df.drop_duplicates(['first_name','last_name'],inplace=True)
这样,我们就将上面案例中中的会员数据进行了清理,来看看清理之后的数据结果。
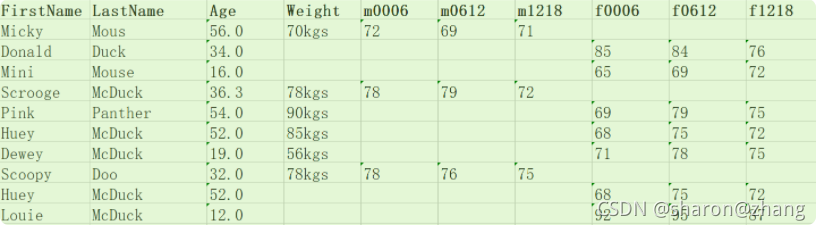
到此这篇关于利用pandas进行数据清洗的方法的文章就介绍到这了,更多相关pandas 数据清洗内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-

利用pandas进行数据清洗的方法
目录 1.完整性 1.1 缺失值 1.2 空行 2.全面性 列数据的单位不统一 3.合理性 非ASCII字符 4.唯一性 4.1 一列有多个参数 4.2 重复数据 我们有下面的一个数据,利用其做简单的数据分析. 这是一家服装店统计的会员数据.最上面的一行是列坐标,最左侧一列是行坐标.列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸. 数据清洗规则总结为以下 4 个关键点
-
Python利用Pandas进行数据分析的方法详解
目录 Series 代码 #1 代码 #2 代码#3 代码 #4 数据框 代码 #1 代码 #2 代码 #3 代码 #4 Pandas是最流行的用于数据分析的 Python 库.它提供高度优化的性能,后端源代码完全用C或Python编写. 我们可以通过以下方式分析 pandas 中的数据: 1.Series 2.数据帧 Series Series 是 pandas 中定义的一维(1-D)数组,可用于存储任何数据类型. 代码 #1 创建 Series # 创建 Series 的程序 # 导入 Pa
-
利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常
-
利用Pandas 创建空的DataFrame方法
平时写pyhton的时候习惯初始化一些list啊,tuple啊,dict啊这样的.一用到Pandas的DataFrame数据结构也就总想着初始化一个空的DataFrame,虽然没什么太大的用处,不过还是记录一下: # 创建一个空的 DataFrame df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D']) 上面创建的DataFrame有4列,每一行没有成员是空的. 输出一下结果: Empty DataFrame Columns: [A, B,
-
python 利用pandas将arff文件转csv文件的方法
直接贴代码啦: #coding=utf-8 import pandas as pd def arff_to_csv(fpath): #读取arff数据 if fpath.find('.arff') <0: print('the file is nott .arff file') return f = open(fpath) lines = f.readlines() content = [] for l in lines: content.append(l) datas = [] for c i
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
python利用pandas将excel文件转换为txt文件的方法
python将数据换为txt的方法有很多,可以用xlrd库实现.本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件. 直接上代码: ''' function:将excel文件转换为text author:Nstock date:2018/3/1 ''' import pandas as pd import re import codecs #将excel转化为txt文件 def exceltotxt(excel_dir, txt_dir): with co
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
利用pandas进行大文件计数处理的方法
Pandas读取大文件 要处理的是由探测器读出的脉冲信号,一组数据为两列,一列为时间,一列为脉冲能量,数据量在千万级,为了有一个直接的认识,先使用Pandas读取一些 import pandas as pd data = pd.read_table('filename.txt', iterator=True) chunk = data.get_chunk(5) 而输出是这样的: Out[4]: 332.977889999979 -0.0164794921875 0 332.97790 -0.02