Pytorch搭建SRGAN平台提升图片超分辨率
目录
- 网络构建
- 一、什么是SRGAN
- 二、生成网络的构建
- 三、判别网络的构建
- 训练思路
- 一、判别器的训练
- 二、生成器的训练
- 利用SRGAN生成图片
- 一、数据集的准备
- 二、数据集的处理
- 三、模型训练
源码下载地址
网络构建
一、什么是SRGAN
SRGAN出自论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network。
如果将SRGAN看作一个黑匣子,其主要的功能就是输入一张低分辨率图片,生成高分辨率图片。

该文章提到,普通的超分辨率模型训练网络时只用到了均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节。
SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。
二、生成网络的构建

生成网络的构成如上图所示,生成网络的作用是输入一张低分辨率图片,生成高分辨率图片。:
SRGAN的生成网络由三个部分组成。
1、低分辨率图像进入后会经过一个卷积+RELU函数。
2、然后经过B个残差网络结构,每个残差结构都包含两个卷积+标准化+RELU,还有一个残差边。
3、然后进入上采样部分,在经过两次上采样后,原图的高宽变为原来的4倍,实现分辨率的提升。
前两个部分用于特征提取,第三部分用于提高分辨率。
import math
import torch
from torch import nn
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.prelu = nn.PReLU(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
short_cut = x
x = self.conv1(x)
x = self.bn1(x)
x = self.prelu(x)
x = self.conv2(x)
x = self.bn2(x)
return x + short_cut
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)
self.pixel_shuffle = nn.PixelShuffle(up_scale)
self.prelu = nn.PReLU(in_channels)
def forward(self, x):
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
class Generator(nn.Module):
def __init__(self, scale_factor, num_residual=16):
upsample_block_num = int(math.log(scale_factor, 2))
super(Generator, self).__init__()
self.block_in = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=9, padding=4),
nn.PReLU(64)
)
self.blocks = []
for _ in range(num_residual):
self.blocks.append(ResidualBlock(64))
self.blocks = nn.Sequential(*self.blocks)
self.block_out = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64)
)
self.upsample = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)]
self.upsample.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))
self.upsample = nn.Sequential(*self.upsample)
def forward(self, x):
x = self.block_in(x)
short_cut = x
x = self.blocks(x)
x = self.block_out(x)
upsample = self.upsample(x + short_cut)
return torch.tanh(upsample)
三、判别网络的构建
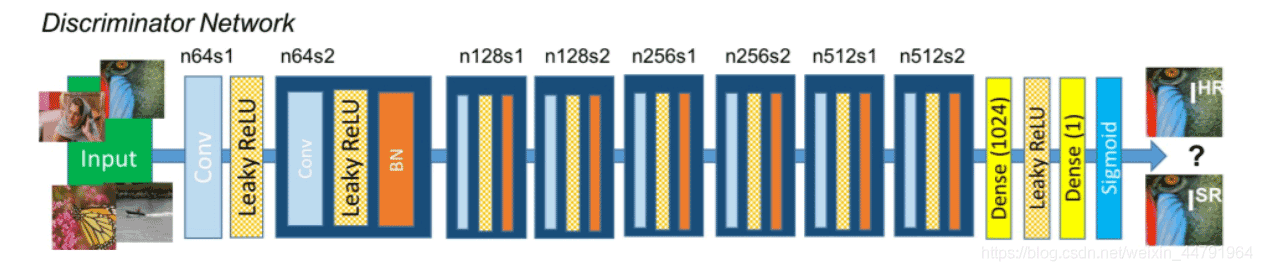
判别网络的构成如上图所示:
SRGAN的判别网络由不断重复的 卷积+LeakyRELU和标准化 组成。
对于判断网络来讲,它的目的是判断输入图片的真假,它的输入是图片,输出是判断结果。
判断结果处于0-1之间,利用接近1代表判断为真图片,接近0代表判断为假图片。
判断网络的构建和普通卷积网络差距不大,都是不断的卷积对图片进行下采用,在多次卷积后,最终接一次全连接判断结果。
实现代码如下:
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, kernel_size=1),
nn.LeakyReLU(0.2),
nn.Conv2d(1024, 1, kernel_size=1)
)
def forward(self, x):
batch_size = x.size(0)
return torch.sigmoid(self.net(x).view(batch_size))
训练思路
SRGAN的训练可以分为生成器训练和判别器训练:
每一个step中一般先训练判别器,然后训练生成器。
一、判别器的训练
在训练判别器的时候我们希望判别器可以判断输入图片的真伪,因此我们的输入就是真图片、假图片和它们对应的标签。
因此判别器的训练步骤如下:
1、随机选取batch_size个真实高分辨率图片。
2、利用resize后的低分辨率图片,传入到Generator中生成batch_size个虚假高分辨率图片。
3、真实图片的label为1,虚假图片的label为0,将真实图片和虚假图片当作训练集传入到Discriminator中进行训练。
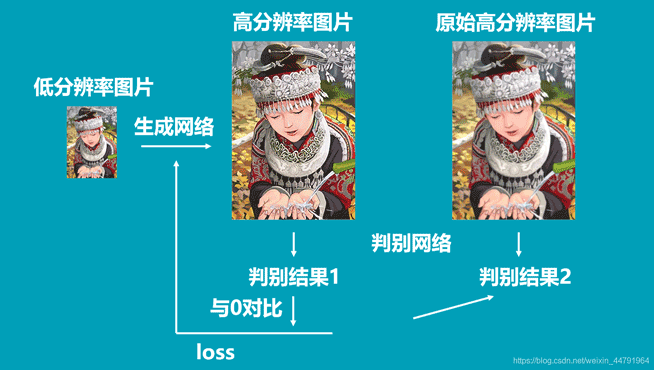
二、生成器的训练
在训练生成器的时候我们希望生成器可以生成极为真实的假图片。因此我们在训练生成器需要知道判别器认为什么图片是真图片。
因此生成器的训练步骤如下:
1、将低分辨率图像传入生成模型,得到虚假高分辨率图像,将虚假高分辨率图像获得判别结果与1进行对比得到loss。(与1对比的意思是,让生成器根据判别器判别的结果进行训练)。
2、将真实高分辨率图像和虚假高分辨率图像传入VGG网络,获得两个图像的特征,通过这两个图像的特征进行比较获得loss

利用SRGAN生成图片
SRGAN的库整体结构如下:

一、数据集的准备
在训练前需要准备好数据集,数据集保存在datasets文件夹里面。

二、数据集的处理
打开txt_annotation.py,默认指向根目录下的datasets。运行txt_annotation.py。
此时生成根目录下面的train_lines.txt。

三、模型训练
在完成数据集处理后,运行train.py即可开始训练。

训练过程中,可在results文件夹内查看训练效果:

以上就是Pytorch搭建SRGAN平台提升图片超分辨率的详细内容,更多关于Pytorch搭建SRGAN图片超分辨率的资料请关注我们其它相关文章!
相关推荐
-

Pytorch搭建SRGAN平台提升图片超分辨率
目录 网络构建 一.什么是SRGAN 二.生成网络的构建 三.判别网络的构建 训练思路 一.判别器的训练 二.生成器的训练 利用SRGAN生成图片 一.数据集的准备 二.数据集的处理 三.模型训练 源码下载地址 网络构建 一.什么是SRGAN SRGAN出自论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. 如果将SRGAN看作一个黑匣子,其主要的功能就是输入一张低分辨率图
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol
-
Pytorch搭建yolo3目标检测平台实现源码
目录 yolo3实现思路 一.预测部分 1.主题网络darknet53介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.计算loss所需参数 2.pred是什么 3.target是什么. 4.loss的计算过程 训练自己的YoloV3模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 yolo3实现思路 一起来看看yolo3的Pytorch实现吧,顺便训练一下自己的数据. 源码下载 一.预测部分 1.主题网络darknet53介绍
-
pytorch 搭建神经网路的实现
目录 1 数据 (1)导入数据 (2)数据集可视化 (3)为自己制作的数据集创建类 (4)数据集批处理 (5)数据预处理 2 神经网络 (1)定义神经网络类 (3)模型参数 3 最优化模型参数 (1)超参数 (2)损失函数 (3)优化方法 4 模型的训练与测试 (1)训练循环与测试循环 (2)禁用梯度跟踪 5 模型的保存.导入与GPU加速 (1)模型的保存与导入 (2)GPU加速 总结 1 数据 (1)导入数据 我们以Fashion-MNIST数据集为例,介绍一下关于pytorch的数据集导入.
-
PyTorch搭建CNN实现风速预测
目录 数据集 特征构造 一维卷积 数据处理 1.数据预处理 2.数据集构造 CNN模型 1.模型搭建 2.模型训练 3.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将利用CNN来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 一维卷积 我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部
-
鼠标移入移出事件改变图片的分辨率的两种方法
最近在做一个鼠标移入移出图片事件,有几种方法大家可以试一下 首先是改变分辨率的两种方法,鼠标移入图片和移出图片的分辨率不同 方法一 复制代码 代码如下: <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title
-
PyTorch搭建一维线性回归模型(二)
PyTorch基础入门二:PyTorch搭建一维线性回归模型 1)一维线性回归模型的理论基础 给定数据集,线性回归希望能够优化出一个好的函数,使得能够和尽可能接近. 如何才能学习到参数和呢?很简单,只需要确定如何衡量与之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:.取平方是因为距离有正有负,我们于是将它们变为全是正的.这就是著名的均方误差.我们要做的事情就是希望能够找到和,使得: 均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离.现在要求解这个连续函数的最小
-
PyTorch搭建多项式回归模型(三)
PyTorch基础入门三:PyTorch搭建多项式回归模型 1)理论简介 对于一般的线性回归模型,由于该函数拟合出来的是一条直线,所以精度欠佳,我们可以考虑多项式回归来拟合更多的模型.所谓多项式回归,其本质也是线性回归.也就是说,我们采取的方法是,提高每个属性的次数来增加维度数.比如,请看下面这样的例子: 如果我们想要拟合方程: 对于输入变量和输出值,我们只需要增加其平方项.三次方项系数即可.所以,我们可以设置如下参数方程: 可以看到,上述方程与线性回归方程并没有本质区别.所以我们可以采用线性回
-
pytorch 实现将自己的图片数据处理成可以训练的图片类型
为了使用自己的图像数据,需要仿照pytorch数据输入创建新的类,其中数据格式为numpy.ndarray. 将自己的图片保存到numpy.ndarray中,然后创建类 from torch.utils.data import Dataset import numpy as np class Dataset(Dataset): def __init__(self, path_img, path_target, transforms=None): self.train = path_img sel