SQL实现筛选出连续3天登录用户与窗口函数的示例代码
目录
- 还原试题
- SQL窗口函数
- 一.窗口函数有什么用
- 二.什么是窗口函数
- 三.如何使用
- 1.专用窗口函数rank
- 2.其他专业窗口函数
- 3.聚合函数作为窗口函数
- 4.注意事项
- 四.总结
- 1.窗口函数语法
- 2.窗口函数有以下功能:
- 3.注意事项
- 解题思路
- 代码实现
- 其他解法与延展
还原试题
首先新建一张表来还原一下试题:
CREATE TABLE last_3_day_test_table
(
user_id varchar(300),
login_date date
);
INSERT INTO last_3_day_test_table ( user_id , login_date )
VALUES
('A', '2019/9/2'),
('A', '2019/9/3'),
('A', '2019/9/4'),
('B', '2018/11/25'),
('B', '2018/12/31'),
('C', '2019/1/1'),
('C', '2019/4/4'),
('C', '2019/9/3'),
('C', '2019/9/4'),
('C', '2019/9/5');
表中数据如下所示:
+──────────+─────────────+ | user_id | login_date | +──────────+─────────────+ | A | 2019-09-02 | | A | 2019-09-03 | | A | 2019-09-04 | | B | 2018-11-25 | | B | 2018-12-31 | | C | 2019-01-01 | | C | 2019-04-04 | | C | 2019-09-03 | | C | 2019-09-04 | | C | 2019-09-05 | +──────────+─────────────+
现在需要找出这张表中所有的连续3天登录用户
这个问题虽然说难不难,但说易也不简单,而且,偏受大小厂喜欢。其实,不管是数仓/ETL/BI/数据分析/大数据等方向,都会经常被面试/笔试考察到。而解决这个问题的核心在于窗口函数的使用,因此先来看一下什么是窗口函数
SQL窗口函数
一.窗口函数有什么用
在日常工作中,经常会遇到需要在每组内排名,比如下面的业务需求:
- 排名问题:每个部门按业绩来排名
- topN问题:找出每个部门排名前N的员工进行奖励
- 汇总问题:需要加总每个部门的业绩加总,但是需要按照按照最细的维度呈现而非一张汇总表呈现
面对这类需求,就需要使用sql的高级功能窗口函数了。
二.什么是窗口函数
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
那么语法中的<窗口函数>都有哪些呢?
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
三.如何使用
接下来,就结合实例,给大家介绍几种窗口函数的用法。
1.专用窗口函数rank
例如下图,是班级表中的内容

如果我们想在每个班级内按成绩排名,得到下面的结果。
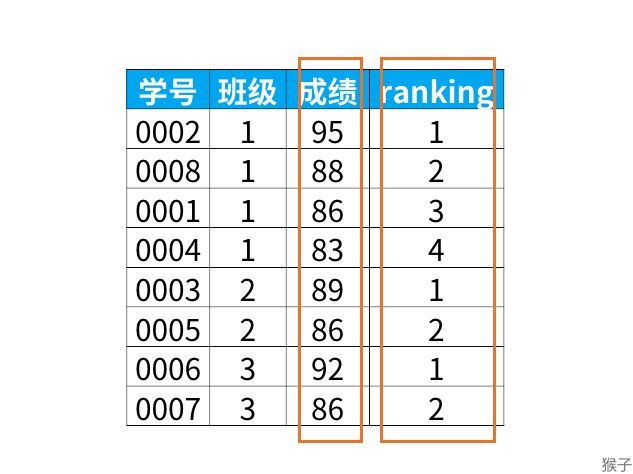
以班级“1”为例,这个班级的成绩“95”排在第1位,这个班级的“83”排在第4位。上面这个结果确实按我们的要求在每个班级内,按成绩排名了。
得到上面结果的sql语句代码如下:
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
我们来解释下这个sql语句里的select子句。rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
1)每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
2)按成绩排名
order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列。在本例中(order by 成绩 desc)是按成绩这一列排序,加了desc关键词表示降序排列。
通过下图,我们就可以理解partiition by(分组)和order by(在组内排序)的作用了。
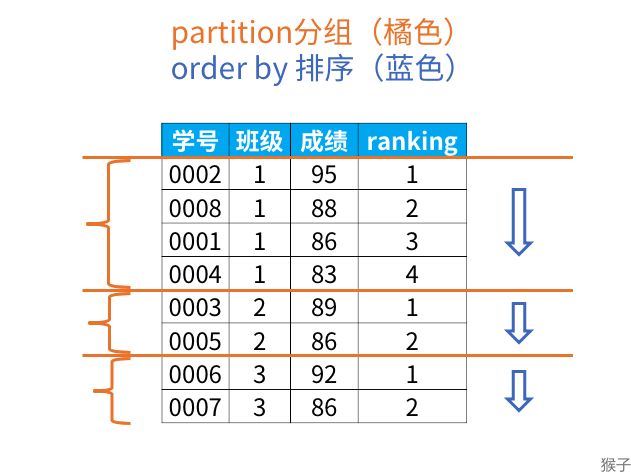
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。例如下面统计每个班级的人数。
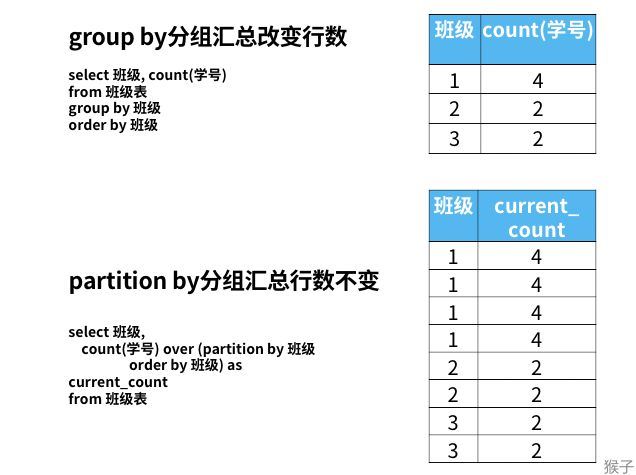
相信通过这个例子,你已经明白了这个窗口函数的使用:
现在我们说回来,为什么叫“窗口”函数呢?这是因为partition by分组后的结果称为“窗口”,这里的窗口不是我们家里的门窗,而是表示“范围”的意思。
简单来说,窗口函数有以下功能:
- 同时具有分组和排序的功能
- 不减少原表的行数
- 语法如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
2.其他专业窗口函数
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *, rank() over (order by 成绩 desc) as ranking, dense_rank() over (order by 成绩 desc) as dese_rank, row_number() over (order by 成绩 desc) as row_num from 班级表
得到结果:
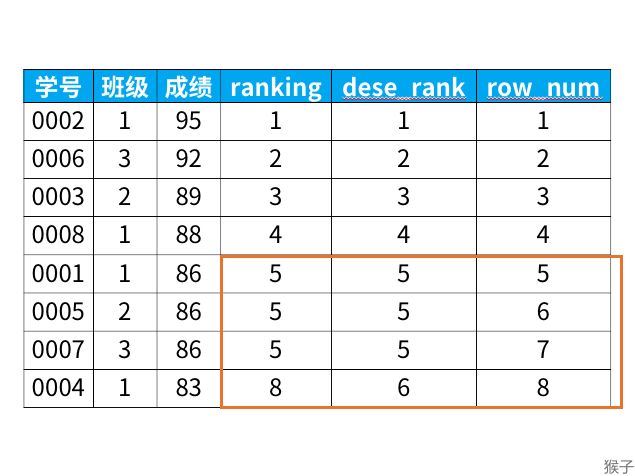
从上面的结果可以看出:
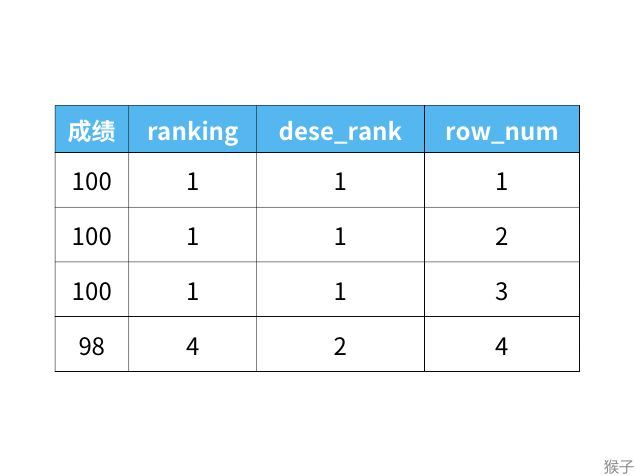
rank函数: 这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数: 这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数: 这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
这三个函数的区别如下:
最后,需要强调的一点是:在上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以。
现在,大家对窗口函数有一个基本了解了吗?
3.聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
我们来看一下窗口函数是聚合函数时,会出来什么结果:
select *, sum(成绩) over (order by 学号) as current_sum, avg(成绩) over (order by 学号) as current_avg, count(成绩) over (order by 学号) as current_count, max(成绩) over (order by 学号) as current_max, min(成绩) over (order by 学号) as current_min from 班级表
得到结果:

有发现什么吗?我单独用sum举个例子:
如上图,聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算,现在再结合刚才得到的结果(下图),是不是理解起来容易多了?
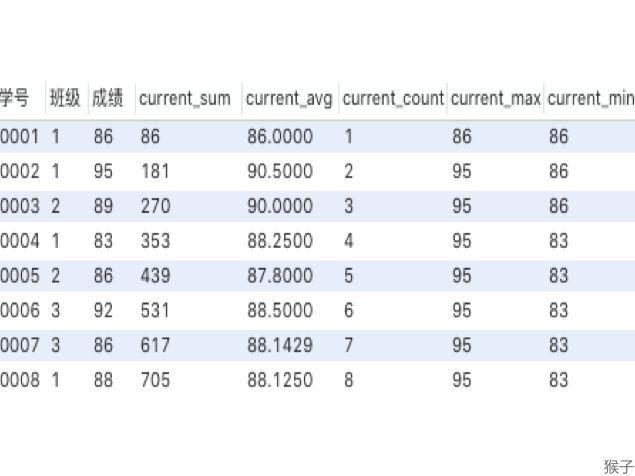
比如0005号后面的聚合窗口函数结果是:学号0001~0005五人成绩的总和、平均、计数及最大最小值。
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
这样使用窗口函数有什么用呢?
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
4.注意事项
partition子句可是省略,省略就是不指定分组,结果如下,只是按成绩由高到低进行了排序:
select *, rank() over (order by 成绩 desc) as ranking from 班级表
得到结果:

但是,这就失去了窗口函数的功能,所以一般不要这么使用。
四.总结
1.窗口函数语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,比如rank, dense_rank, row_number等
2) 聚合函数,如sum. avg, count, max, min等
2.窗口函数有以下功能:
1)同时具有分组(partition by)和排序(order by)的功能
2)不减少原表的行数,所以经常用来在每组内排名
3.注意事项
窗口函数原则上只能写在select子句中
解题思路
通过上述解释,我们知道了什么是窗口函数,接下来就是如何利用窗口函数来解决这个问题.解决问题的关键是:如何判断每个用户连续
思路是先通过窗口函数对user_id分组排序后(rn),用登录日期减去序号m,如果连续的话,则得到的这个日期(flag_date)会相同
即: flag_date=login_date-rn
+──────────+─────────────+─────+────────────+ | user_id | login_date | rn | flag_date | +──────────+─────────────+─────+────────────+ | A | 2019-09-02 | 1 | 2019-09-01 | | A | 2019-09-03 | 2 | 2019-09-01 | | A | 2019-09-04 | 3 | 2019-09-01 | | B | 2018-11-25 | 1 | 2018-11-24 | | B | 2018-12-31 | 2 | 2018-12-29 | | C | 2019-01-01 | 1 | 2018-12-31 | | C | 2019-04-04 | 2 | 2019-04-02 | | C | 2019-09-03 | 3 | 2019-08-31 | | C | 2019-09-04 | 4 | 2019-08-31 | | C | 2019-09-05 | 5 | 2019-08-31 | +──────────+─────────────+─────+────────────+
然后我们只需要通过筛选出所有相同flag_date个数大于3即可得到结果。如果实现筛选出连续n天登录用户,这里相应的改成n就可以了
代码实现
在SQL Server中:
select user_id
from (
select user_id,login_date,
row_number() over(partition by user_id order by login_date) as
rn
from last_3_day_test_table
) t
group by user_id,DATEADD(D,-t.rn,login_date)
having count(1)>=3;
在Mysql中(注意需要在Mysql 8.0及以上版本才支持开窗函数,低版本无法运行):
select user_id from ( select user_id,login_date, 1 as rn from last_3_day_test_table ) as t group by user_id,date_sub(login_date,interval t.rn day) having count(1)>=3
两者的区别就是在计算login_date-t.rn时,SQL Server中要使用DATEADD函数,且语法为:DATEADD(D,-t.rn,login_date),而Mysql中直接使用date_sub 即可实现日期减去指定的时间间隔
其他解法与延展
附上另外的一种解法供参考,基于SQL server:
select
b.user_id
from
(
select
user_id,login_date,lead(login_date,2,'1900/1/1') over(partition by user_id order by login_date desc) as date1
from
last_3_day_test_table a
group by
user_id,login_date
) as b
where
DATEADD(D,-2,cast(b.login_date as date))
=cast(b.date1 as date);
在这个解法中使用了另一个窗口函数: LEAD()函数。它提供对当前行之后的指定物理偏移量的行的访问。简单来说就是通过使用LEAD()函数,可以返回当前行的下一行的数据或下n行的数据。
LEAD()函数对于将当前行的值与后续行的值进行比较非常有用。
LEAD()函数的语法为:
LEAD(return_value ,offset [,default])
over (partition by <用于分组的列名>
order by <用于排序的列名>)
在上面语法中,
return_value: 基于指定偏移量的后续行的返回值,返回值必须求值为单个值。简单来说就是偏移行后去哪一列的值返回
offset: 是从当前行所需偏移的行数,用于访问数据。offset可以是表达式,子查询或列,其值为正整数。如果未明确指定,则offset的默认值为1。如果offset超出分区范围,则该函数返回default。
default: 偏移超出分区范围后的默认值,如果未指定,则默认为NULL。
本文参考文章:https://zhuanlan.zhihu.com/p/92654574
到此这篇关于SQL实现筛选出连续3天登录用户与窗口函数的示例代码的文章就介绍到这了,更多相关SQL筛选登录用户与窗口函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SQL窗口函数之取值窗口函数的使用
目录 案例分析 1.环比分析 2.同比分析 3.复合增长率 4.不同产品最高和最低销售额 示例表和脚本 关于窗口函数的基础,请看文章SQL窗口函数 取值窗口函数可以用于返回窗口内指定位置的数据行.常见的取值窗口函数如下: LAG函数可以返回窗口内当前行之前的第N行数据. LEAD函数可以返回窗口内当前行之后的第N行数据. FIRST_VALUE函数可以返回窗口内第一行数据. LAST_VALUE函数可以返回窗口内最后一行数据. NTH_VALUE函数可以返回窗口内第N行数据. 其中,LAG函数和
-
SQL窗口函数之排名窗口函数的使用
目录 案例分析 案例使用的示例表 1.环比分析 2.同比分析 3.复合增长率 4.不同产品最高和最低销售额 示例表和脚本 关于窗口函数的基础,请看文章SQL窗口函数 取值窗口函数可以用于返回窗口内指定位置的数据行.常见的取值窗口函数如下: LAG函数可以返回窗口内当前行之前的第N行数据.LEAD函数可以返回窗口内当前行之后的第N行数据.FIRST_VALUE函数可以返回窗口内第一行数据.LAST_VALUE函数可以返回窗口内最后一行数据.NTH_VALUE函数可以返回窗口内第N行数据. 其中,L
-
Mysql8.0使用窗口函数解决排序问题
MySQL窗口函数简介 MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数. 什么叫窗口? 窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数.对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口:有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口. 窗口函数和普通聚合函数也很容易混淆,二者区别如下: 聚合函数是将多条记录聚合为一条:
-
SQL窗口函数的使用方法
目录 什么是窗口函数 窗口函数组成部分 1.创建数据分区 2.分区内的排序 3.指定窗口大小 窗口函数分类 1.聚合窗口函数 2.排名窗口函数 3.取值窗口函数 什么是窗口函数 SQL窗口函数为在线分析处理(OLAP)和商业智能(BI)提供了复杂分析和报表统计的功能,例如产品的累计销售额统计.分类排名.同比/环比分析等.这些功能通常很难通过聚合函数和分组操作来实现. 窗口函数(Window Function)可以像聚合函数一样对一组数据进行分析并返回结果,二者的不同之处在于,窗口函数不是将一组数
-
SQL窗口函数之聚合窗口函数的使用(count,max,min,sum)
目录 案例分析 1.移动平均值 2.累计求和(ROW) 3.累计求和(RANGE) 示例表和脚本 关于窗口函数的基础,请看文章SQL窗口函数 许多常见的聚合函数也可以作为窗口函数使用,包括AVG().SUM().COUNT().MAX()以及MIN()等函数. 案例分析 案例使用的示例表 下面的查询中会用到两个表,其中sales_monthly表中存储了不同产品(苹果.香蕉.橘子)每个月的销售额情况.以下是该表中的部分数据: transfer_log表中记录了一些银行账户的交易日志.以下是该表中
-
带你快速了解SQL窗口函数
目录 底表 分组排序 各分组排序函数的差异 累计聚合 与 GROUP BY 组合使用 总结 窗口函数形如: 表达式 OVER (PARTITION BY 分组字段 ORDER BY 排序字段) 有两个能力: 当表达式为 rank() dense_rank() row_number() 时,拥有分组排序能力. 当表达式为 sum() 等聚合函数时,拥有累计聚合能力. 无论何种能力,窗口函数都不会影响数据行数,而是将计算平摊在每一行. 这两种能力需要区分理解. 底表 以上是示例底表,共有 8 条数据
-
MySQL8.0窗口函数入门实践及总结
前言 MySQL8.0之前,做数据排名统计等相当痛苦,因为没有像Oracle.SQL SERVER .PostgreSQL等其他数据库那样的窗口函数.但随着MySQL8.0中新增了窗口函数之后,针对这类统计就再也不是事了,本文就以常用的排序实例介绍MySQL的窗口函数. 1.准备工作 创建表及测试数据 mysql> use testdb; Database changed /* 创建表 */ mysql> create table tb_score(id int primary key aut
-
SQL实现筛选出连续3天登录用户与窗口函数的示例代码
目录 还原试题 SQL窗口函数 一.窗口函数有什么用 二.什么是窗口函数 三.如何使用 1.专用窗口函数rank 2.其他专业窗口函数 3.聚合函数作为窗口函数 4.注意事项 四.总结 1.窗口函数语法 2.窗口函数有以下功能: 3.注意事项 解题思路 代码实现 其他解法与延展 还原试题 首先新建一张表来还原一下试题: CREATE TABLE last_3_day_test_table ( user_id varchar(300), login_date date ); INSERT INTO
-
Spring Security实现统一登录与权限控制的示例代码
目录 项目介绍 统一认证中心 配置授权服务器 配置WebSecurity 登录 菜单 鉴权 资源访问的一些配置 有用的文档 项目介绍 最开始是一个单体应用,所有功能模块都写在一个项目里,后来觉得项目越来越大,于是决定把一些功能拆分出去,形成一个一个独立的微服务,于是就有个问题了,登录.退出.权限控制这些东西怎么办呢?总不能每个服务都复制一套吧,最好的方式是将认证与鉴权也单独抽离出来作为公共的服务,业务系统只专心做业务接口开发即可,完全不用理会权限这些与之不相关的东西了.于是,便有了下面的架构图:
-
微信小程序连续签到7天积分获得功能的示例代码
每周每天签到获得积分的案例 功能设计:计算每天签到得1分,显示得到的签到积分,连续签到3天[周一二三]即得+多3分,连续签到7天[周一二三四五六日]+多7分,没有连续即不显示多余的3分或7分的提示- wxml结构: <!--pages/signIn2/signIn2.wxml--> <view class='sign-new'> <view class='in'> <view class='new-head'> <view class='sig-tl'
-
Vue+Flask实现简单的登录验证跳转的示例代码
本文介绍了Vue+Flask实现简单的登录验证跳转,分享给大家,具体如下: 文件位置: login.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Login</title> <script type="text/javascript" src="../sta
-
Laravel框架基于中间件实现禁止未登录用户访问页面功能示例
本文实例讲述了Laravel框架基于中间件实现禁止未登录用户访问页面功能.分享给大家供大家参考,具体如下: 1.生成中间件 [root@localhost MRedis]# php artisan make:middleware CheckLogin Middleware created successfully. 2.实现中间件,在app\http\middleware\CheckLogin.php public function handle($request, Closure $next)
-
ASP.NET Core中实现用户登录验证的最低配置示例代码
前言 本文主要给大家介绍了关于ASP.NET Core用户登录验证的最低配置的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: 背景是在一个项目中增加临时登录功能,只需验证用户是否登录即可,所需的最低配置与实现代码如下. 方法如下: 在 Startup 的 ConfigureServices() 方法中添加 Authentication 的配置: services.AddAuthentication(options => { options.DefaultAuthenti
-
SpringMVC拦截器——实现登录验证拦截器的示例代码
本例实现登陆时的验证拦截,采用SpringMVC拦截器来实现 当用户点击到网站主页时要进行拦截,用户登录了才能进入网站主页,否则进入登陆页面 核心代码 首先是index.jsp,显示链接 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <% String path = request.getContextPath(); String bas
-
Vue+Express实现登录状态权限验证的示例代码
前提 对Vue全家桶有基本的认知. 用有node环境 了解express 另外本篇只是介绍登录状态的权限验证,以及登录,注销的前后端交互.具体流程(例如:前端布局,后端密码验证等).以后有时间再对这些边边角角进行补充 一丶业务分析 1.什么情况下进行权限验证? 访问敏感接口 前端向后端敏感接口发送ajax 后端进行session验证,并返回信息 前端axios拦截返回信息,根据返回信息进行操作 进行页面切换 页面切换,触发vue-router的路由守卫 路由守卫根据跳转地址进行验证,如需权限,则
-
Bootstrap告警框(alert)实现弹出效果和短暂显示后上浮消失的示例代码
最近用到bootstrap的告警框时发现只有html的说明,就自己写了一个弹出告警框和弹出短暂显示后上浮消失的告警框. 使用效果 移入时停止上浮的效果 直接上JS代码了,可以copy过去直接用(使用bootstrap的UI框架的情况下) var commonUtil = { /** * 弹出消息框 * @param msg 消息内容 * @param type 消息框类型(参考bootstrap的alert) */ alert: function(msg, type){ if(typeof(ty
-
Hive-SQL查询连续活跃登录用户思路详解
连续活跃登陆的用户指至少连续2天都活跃登录的用户 解决类似场景的问题 创建数据 CREATE TABLE test5active( dt string, user_id string, age int) ROW format delimited fields terminated BY ','; INSERT INTO TABLE test5active VALUES ('2019-02-11','user_1',23),('2019-02-11','user_2',19), ('2019-02