python目标检测yolo3详解预测及代码复现
目录
- 学习前言
- 实现思路
- 1、yolo3的预测思路(网络构建思路)
- 2、利用先验框对网络的输出进行解码
- 3、进行得分排序与非极大抑制筛选
- 实现结果
学习前言
对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大
代码下载
本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同。
我保留了预测部分的代码,在实际可以通过执行detect.py运行示例。
链接: https://pan.baidu.com/s/1_xLeytnjBBSL2h2Kj4-YEw
取码:i3hi
实现思路
1、yolo3的预测思路(网络构建思路)
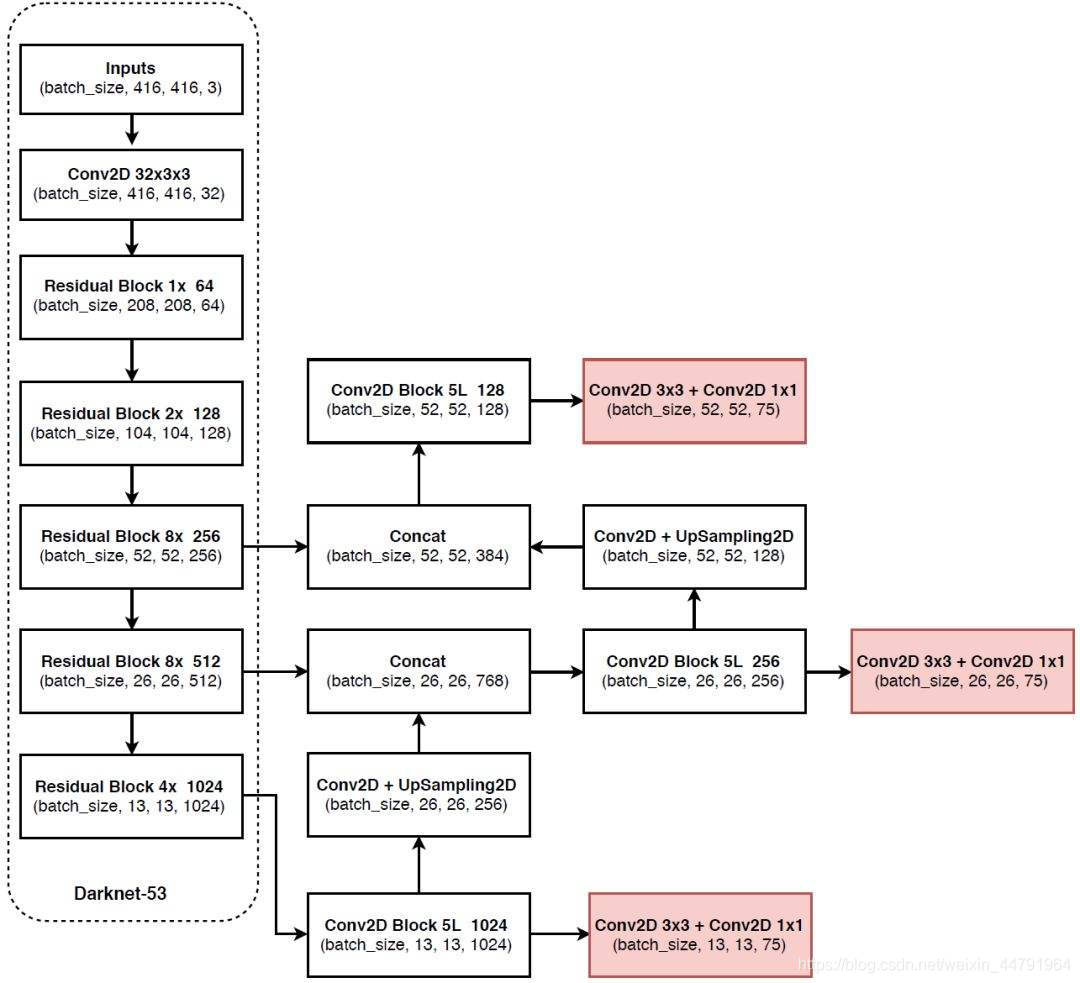
YOLOv3相比于之前的yolo1和yolo2,改进较大,主要改进方向有:
1、使用了残差网络Residual,残差卷积就是进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果, 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2、提取多特征层进行目标检测,一共提取三个特征层,特征层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,yolo3只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
3、其采用反卷积UmSampling2d设计,逆卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算,其可以更多更好的提取出特征。
其实际情况就是,输入N张416x416的图片,在经过多层的运算后,会输出三个shape分别为(N,13,13,255),(N,26,26,255),(N,52,52,255)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
实现代码如下,其在实际调用时,会调用其中的yolo_inference函数,此时获得三个特征层的内容。
def _darknet53(self, inputs, conv_index, training = True, norm_decay = 0.99, norm_epsilon = 1e-3):
"""
Introduction
------------
构建yolo3使用的darknet53网络结构
Parameters
----------
inputs: 模型输入变量
conv_index: 卷积层数序号,方便根据名字加载预训练权重
weights_dict: 预训练权重
training: 是否为训练
norm_decay: 在预测时计算moving average时的衰减率
norm_epsilon: 方差加上极小的数,防止除以0的情况
Returns
-------
conv: 经过52层卷积计算之后的结果, 输入图片为416x416x3,则此时输出的结果shape为13x13x1024
route1: 返回第26层卷积计算结果52x52x256, 供后续使用
route2: 返回第43层卷积计算结果26x26x512, 供后续使用
conv_index: 卷积层计数,方便在加载预训练模型时使用
"""
with tf.variable_scope('darknet53'):
# 416,416,3 -> 416,416,32
conv = self._conv2d_layer(inputs, filters_num = 32, kernel_size = 3, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
# 416,416,32 -> 208,208,64
conv, conv_index = self._Residual_block(conv, conv_index = conv_index, filters_num = 64, blocks_num = 1, training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
# 208,208,64 -> 104,104,128
conv, conv_index = self._Residual_block(conv, conv_index = conv_index, filters_num = 128, blocks_num = 2, training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
# 104,104,128 -> 52,52,256
conv, conv_index = self._Residual_block(conv, conv_index = conv_index, filters_num = 256, blocks_num = 8, training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
# route1 = 52,52,256
route1 = conv
# 52,52,256 -> 26,26,512
conv, conv_index = self._Residual_block(conv, conv_index = conv_index, filters_num = 512, blocks_num = 8, training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
# route2 = 26,26,512
route2 = conv
# 26,26,512 -> 13,13,1024
conv, conv_index = self._Residual_block(conv, conv_index = conv_index, filters_num = 1024, blocks_num = 4, training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
# route3 = 13,13,1024
return route1, route2, conv, conv_index
# 输出两个网络结果
# 第一个是进行5次卷积后,用于下一次逆卷积的,卷积过程是1X1,3X3,1X1,3X3,1X1
# 第二个是进行5+2次卷积,作为一个特征层的,卷积过程是1X1,3X3,1X1,3X3,1X1,3X3,1X1
def _yolo_block(self, inputs, filters_num, out_filters, conv_index, training = True, norm_decay = 0.99, norm_epsilon = 1e-3):
"""
Introduction
------------
yolo3在Darknet53提取的特征层基础上,又加了针对3种不同比例的feature map的block,这样来提高对小物体的检测率
Parameters
----------
inputs: 输入特征
filters_num: 卷积核数量
out_filters: 最后输出层的卷积核数量
conv_index: 卷积层数序号,方便根据名字加载预训练权重
training: 是否为训练
norm_decay: 在预测时计算moving average时的衰减率
norm_epsilon: 方差加上极小的数,防止除以0的情况
Returns
-------
route: 返回最后一层卷积的前一层结果
conv: 返回最后一层卷积的结果
conv_index: conv层计数
"""
conv = self._conv2d_layer(inputs, filters_num = filters_num, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
conv = self._conv2d_layer(conv, filters_num = filters_num * 2, kernel_size = 3, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
conv = self._conv2d_layer(conv, filters_num = filters_num, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
conv = self._conv2d_layer(conv, filters_num = filters_num * 2, kernel_size = 3, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
conv = self._conv2d_layer(conv, filters_num = filters_num, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
route = conv
conv = self._conv2d_layer(conv, filters_num = filters_num * 2, kernel_size = 3, strides = 1, name = "conv2d_" + str(conv_index))
conv = self._batch_normalization_layer(conv, name = "batch_normalization_" + str(conv_index), training = training, norm_decay = norm_decay, norm_epsilon = norm_epsilon)
conv_index += 1
conv = self._conv2d_layer(conv, filters_num = out_filters, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index), use_bias = True)
conv_index += 1
return route, conv, conv_index
# 返回三个特征层的内容
def yolo_inference(self, inputs, num_anchors, num_classes, training = True):
"""
Introduction
------------
构建yolo模型结构
Parameters
----------
inputs: 模型的输入变量
num_anchors: 每个grid cell负责检测的anchor数量
num_classes: 类别数量
training: 是否为训练模式
"""
conv_index = 1
# route1 = 52,52,256、route2 = 26,26,512、route3 = 13,13,1024
conv2d_26, conv2d_43, conv, conv_index = self._darknet53(inputs, conv_index, training = training, norm_decay = self.norm_decay, norm_epsilon = self.norm_epsilon)
with tf.variable_scope('yolo'):
#--------------------------------------#
# 获得第一个特征层
#--------------------------------------#
# conv2d_57 = 13,13,512,conv2d_59 = 13,13,255(3x(80+5))
conv2d_57, conv2d_59, conv_index = self._yolo_block(conv, 512, num_anchors * (num_classes + 5), conv_index = conv_index, training = training, norm_decay = self.norm_decay, norm_epsilon = self.norm_epsilon)
#--------------------------------------#
# 获得第二个特征层
#--------------------------------------#
conv2d_60 = self._conv2d_layer(conv2d_57, filters_num = 256, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index))
conv2d_60 = self._batch_normalization_layer(conv2d_60, name = "batch_normalization_" + str(conv_index),training = training, norm_decay = self.norm_decay, norm_epsilon = self.norm_epsilon)
conv_index += 1
# unSample_0 = 26,26,256
unSample_0 = tf.image.resize_nearest_neighbor(conv2d_60, [2 * tf.shape(conv2d_60)[1], 2 * tf.shape(conv2d_60)[1]], name='upSample_0')
# route0 = 26,26,768
route0 = tf.concat([unSample_0, conv2d_43], axis = -1, name = 'route_0')
# conv2d_65 = 52,52,256,conv2d_67 = 26,26,255
conv2d_65, conv2d_67, conv_index = self._yolo_block(route0, 256, num_anchors * (num_classes + 5), conv_index = conv_index, training = training, norm_decay = self.norm_decay, norm_epsilon = self.norm_epsilon)
#--------------------------------------#
# 获得第三个特征层
#--------------------------------------#
conv2d_68 = self._conv2d_layer(conv2d_65, filters_num = 128, kernel_size = 1, strides = 1, name = "conv2d_" + str(conv_index))
conv2d_68 = self._batch_normalization_layer(conv2d_68, name = "batch_normalization_" + str(conv_index), training=training, norm_decay=self.norm_decay, norm_epsilon = self.norm_epsilon)
conv_index += 1
# unSample_1 = 52,52,128
unSample_1 = tf.image.resize_nearest_neighbor(conv2d_68, [2 * tf.shape(conv2d_68)[1], 2 * tf.shape(conv2d_68)[1]], name='upSample_1')
# route1= 52,52,384
route1 = tf.concat([unSample_1, conv2d_26], axis = -1, name = 'route_1')
# conv2d_75 = 52,52,255
_, conv2d_75, _ = self._yolo_block(route1, 128, num_anchors * (num_classes + 5), conv_index = conv_index, training = training, norm_decay = self.norm_decay, norm_epsilon = self.norm_epsilon)
return [conv2d_59, conv2d_67, conv2d_75]
2、利用先验框对网络的输出进行解码
yolo3的先验框生成与yolo2的类似,如果不明白先验框是如何生成的,可以看我的上一篇博文
python目标检测yolo2详解及其预测代码复现
其实yolo3的解码与yolo2的解码过程一样,只是对于yolo3而言,其需要对三个特征层进行解码,三个特征层的shape分别为(N,13,13,255),(N,26,26,255),(N,52,52,255)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
此处需要用到一个循环。
1、将第一个特征层reshape成[-1, 13, 13, 3, 80 + 5],代表169个中心点每个中心点的3个先验框的情况。
2、将80+5的5中的xywh分离出来,0、1是xy相对中心点的偏移量;2、3是宽和高的情况;4是置信度。
3、建立13x13的网格,代表图片进行13x13处理后网格的中心点。
4、利用计算公式计算实际的bbox的位置 。
5、置信度乘上80+5中的80(这里的80指的是类别概率)得到得分。
6、将第二个特征层reshape成[-1, 26, 26, 3, 80 + 5],重复2到5步。将第三个特征层reshape成[-1, 52, 52, 3, 80 + 5],重复2到5步。
单个特征层的解码部分代码如下:
# 获得单个特征层框的位置和得分
def boxes_and_scores(self, feats, anchors, classes_num, input_shape, image_shape):
"""
Introduction
------------
将预测出的box坐标转换为对应原图的坐标,然后计算每个box的分数
Parameters
----------
feats: yolo输出的feature map
anchors: anchor的位置
class_num: 类别数目
input_shape: 输入大小
image_shape: 图片大小
Returns
-------
boxes: 物体框的位置
boxes_scores: 物体框的分数,为置信度和类别概率的乘积
"""
# 获得特征
box_xy, box_wh, box_confidence, box_class_probs = self._get_feats(feats, anchors, classes_num, input_shape)
# 寻找在原图上的位置
boxes = self.correct_boxes(box_xy, box_wh, input_shape, image_shape)
boxes = tf.reshape(boxes, [-1, 4])
# 获得置信度box_confidence * box_class_probs
box_scores = box_confidence * box_class_probs
box_scores = tf.reshape(box_scores, [-1, classes_num])
return boxes, box_scores
# 单个特征层的解码过程
def _get_feats(self, feats, anchors, num_classes, input_shape):
"""
Introduction
------------
根据yolo最后一层的输出确定bounding box
Parameters
----------
feats: yolo模型最后一层输出
anchors: anchors的位置
num_classes: 类别数量
input_shape: 输入大小
Returns
-------
box_xy, box_wh, box_confidence, box_class_probs
"""
num_anchors = len(anchors)
anchors_tensor = tf.reshape(tf.constant(anchors, dtype=tf.float32), [1, 1, 1, num_anchors, 2])
grid_size = tf.shape(feats)[1:3]
predictions = tf.reshape(feats, [-1, grid_size[0], grid_size[1], num_anchors, num_classes + 5])
# 这里构建13*13*1*2的矩阵,对应每个格子加上对应的坐标
grid_y = tf.tile(tf.reshape(tf.range(grid_size[0]), [-1, 1, 1, 1]), [1, grid_size[1], 1, 1])
grid_x = tf.tile(tf.reshape(tf.range(grid_size[1]), [1, -1, 1, 1]), [grid_size[0], 1, 1, 1])
grid = tf.concat([grid_x, grid_y], axis = -1)
grid = tf.cast(grid, tf.float32)
# 将x,y坐标归一化,相对网格的位置
box_xy = (tf.sigmoid(predictions[..., :2]) + grid) / tf.cast(grid_size[::-1], tf.float32)
# 将w,h也归一化
box_wh = tf.exp(predictions[..., 2:4]) * anchors_tensor / tf.cast(input_shape[::-1], tf.float32)
box_confidence = tf.sigmoid(predictions[..., 4:5])
box_class_probs = tf.sigmoid(predictions[..., 5:])
return box_xy, box_wh, box_confidence, box_class_probs
该函数被其它函数调用,用于完成三个特征层的解码:
def eval(self, yolo_outputs, image_shape, max_boxes = 20):
"""
Introduction
------------
根据Yolo模型的输出进行非极大值抑制,获取最后的物体检测框和物体检测类别
Parameters
----------
yolo_outputs: yolo模型输出
image_shape: 图片的大小
max_boxes: 最大box数量
Returns
-------
boxes_: 物体框的位置
scores_: 物体类别的概率
classes_: 物体类别
"""
# 每一个特征层对应三个先验框
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
boxes = []
box_scores = []
# inputshape是416x416
# image_shape是实际图片的大小
input_shape = tf.shape(yolo_outputs[0])[1 : 3] * 32
# 对三个特征层的输出获取每个预测box坐标和box的分数,score = 置信度x类别概率
#---------------------------------------#
# 对三个特征层解码
# 获得分数和框的位置
#---------------------------------------#
for i in range(len(yolo_outputs)):
_boxes, _box_scores = self.boxes_and_scores(yolo_outputs[i], self.anchors[anchor_mask[i]], len(self.class_names), input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
# 放在一行里面便于操作
boxes = tf.concat(boxes, axis = 0)
box_scores = tf.concat(box_scores, axis = 0)
3、进行得分排序与非极大抑制筛选
这一部分基本上是所有目标检测通用的部分。不过该项目的处理方式与其它项目不同。其对于每一个类进行判别。
1、取出每一类得分大于self.obj_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
实现代码如下:
#---------------------------------------#
# 1、取出每一类得分大于self.obj_threshold
# 的框和得分
# 2、对得分进行非极大抑制
#---------------------------------------#
# 对每一个类进行判断
for c in range(len(self.class_names)):
# 取出所有类为c的box
class_boxes = tf.boolean_mask(boxes, mask[:, c])
# 取出所有类为c的分数
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
# 非极大抑制
nms_index = tf.image.non_max_suppression(class_boxes, class_box_scores, max_boxes_tensor, iou_threshold = self.nms_threshold)
# 获取非极大抑制的结果
class_boxes = tf.gather(class_boxes, nms_index)
class_box_scores = tf.gather(class_box_scores, nms_index)
classes = tf.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = tf.concat(boxes_, axis = 0)
scores_ = tf.concat(scores_, axis = 0)
classes_ = tf.concat(classes_, axis = 0)
实际上该部分与第二部分在一个函数里,完成输出的解码和筛选,完成预测过程。
def eval(self, yolo_outputs, image_shape, max_boxes = 20):
"""
Introduction
------------
根据Yolo模型的输出进行非极大值抑制,获取最后的物体检测框和物体检测类别
Parameters
----------
yolo_outputs: yolo模型输出
image_shape: 图片的大小
max_boxes: 最大box数量
Returns
-------
boxes_: 物体框的位置
scores_: 物体类别的概率
classes_: 物体类别
"""
# 每一个特征层对应三个先验框
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
boxes = []
box_scores = []
# inputshape是416x416
# image_shape是实际图片的大小
input_shape = tf.shape(yolo_outputs[0])[1 : 3] * 32
# 对三个特征层的输出获取每个预测box坐标和box的分数,score = 置信度x类别概率
#---------------------------------------#
# 对三个特征层解码
# 获得分数和框的位置
#---------------------------------------#
for i in range(len(yolo_outputs)):
_boxes, _box_scores = self.boxes_and_scores(yolo_outputs[i], self.anchors[anchor_mask[i]], len(self.class_names), input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
# 放在一行里面便于操作
boxes = tf.concat(boxes, axis = 0)
box_scores = tf.concat(box_scores, axis = 0)
mask = box_scores >= self.obj_threshold
max_boxes_tensor = tf.constant(max_boxes, dtype = tf.int32)
boxes_ = []
scores_ = []
classes_ = []
#---------------------------------------#
# 1、取出每一类得分大于self.obj_threshold
# 的框和得分
# 2、对得分进行非极大抑制
#---------------------------------------#
# 对每一个类进行判断
for c in range(len(self.class_names)):
# 取出所有类为c的box
class_boxes = tf.boolean_mask(boxes, mask[:, c])
# 取出所有类为c的分数
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
# 非极大抑制
nms_index = tf.image.non_max_suppression(class_boxes, class_box_scores, max_boxes_tensor, iou_threshold = self.nms_threshold)
# 获取非极大抑制的结果
class_boxes = tf.gather(class_boxes, nms_index)
class_box_scores = tf.gather(class_box_scores, nms_index)
classes = tf.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = tf.concat(boxes_, axis = 0)
scores_ = tf.concat(scores_, axis = 0)
classes_ = tf.concat(classes_, axis = 0)
return boxes_, scores_, classes_
得到框的位置和种类后就可以画图了。
实现结果

以上就是python目标检测yolo3详解预测及代码复现的详细内容,更多关于yolo3预测复现的资料请关注我们其它相关文章!
相关推荐
-

python目标检测IOU的概念与示例
目录 学习前言 什么是IOU IOU的特点 全部代码 学习前言 神经网络的应用还有许多,目标检测就是其中之一,目标检测中有一个很重要的概念便是IOU 什么是IOU IOU是一种评价目标检测器的一种指标. 下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框为预测框,当我们需要判断两个框之间的关系时,需要用什么指标呢? 此时便需要用到IOU. 计算IOU的公式为: 可以看到IOU是一个比值,即交并比. 在分子部分,值为预测框和实际框之间的重叠区域: 在分母部分,值为预测框和实际框所占有的
-
python目标检测SSD算法预测部分源码详解
目录 学习前言 什么是SSD算法 ssd_vgg_300主体的源码 学习前言 ……学习了很多有关目标检测的概念呀,咕噜咕噜,可是要怎么才能进行预测呢,我看了好久的SSD源码,将其中的预测部分提取了出来,训练部分我还没看懂 什么是SSD算法 SSD是一种非常优秀的one-stage方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度
-
python目标检测yolo1 yolo2 yolo3和SSD网络结构对比
目录 睿智的目标检测5——yolo1.yolo2.yolo3和SSD的网络结构汇总对比 学习前言各个网络的结构图与其实现代码1.yolo12.yolo23.yolo34.SSD 总结 学习前言 ……最近在学习yolo1.yolo2和yolo3,事实上它们和SSD网络有一定的相似性,我准备汇总一下,看看有什么差别. 各个网络的结构图与其实现代码 1.yolo1 由图可见,其进行了二十多次卷积还有四次最大池化,其中3x3卷积用于提取特征,1x1卷积用于压缩特征,最后将图像压缩到7x7xfilter的
-
python目标检测yolo2详解及预测代码复现
目录 前言 实现思路 1.yolo2的预测思路(网络构建思路) 2.先验框的生成 3.利用先验框对网络的输出进行解码 4.进行得分排序与非极大抑制筛选 实现结果 前言 ……最近在学习yolo1.yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义. 尽量配合代码观看会更容易理解. 直接下载 实现思路 1.yolo2的预测思路(网络构建思路) YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19
-
python目标检测SSD算法训练部分源码详解
目录 学习前言 讲解构架 模型训练的流程 1.设置参数 2.读取数据集 3.建立ssd网络. 4.预处理数据集 5.框的编码 6.计算loss值 7.训练模型并保存 开始训练 学习前言 ……又看了很久的SSD算法,今天讲解一下训练部分的代码.预测部分的代码可以参照https://blog.csdn.net/weixin_44791964/article/details/102496765 讲解构架 本次教程的讲解主要是对训练部分的代码进行讲解,该部分讲解主要是对训练函数的执行过程与执行思路进行详
-
python目标检测yolo3详解预测及代码复现
目录 学习前言 实现思路 1.yolo3的预测思路(网络构建思路) 2.利用先验框对网络的输出进行解码 3.进行得分排序与非极大抑制筛选 实现结果 学习前言 对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大 代码下载 本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同. 我保留了预测部分的代码,在实际可以通过执行dete
-
Python Flask搭建yolov3目标检测系统详解流程
[人工智能项目]Python Flask搭建yolov3目标检测系统 后端代码 from flask import Flask, request, jsonify from PIL import Image import numpy as np import base64 import io import os from backend.tf_inference import load_model, inference os.environ['CUDA_VISIBLE_DEVICES'] = '
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下
-
Python 字典的使用详解及实例代码
目录 字典长什么样 字典内能放什么 访问字典内容 修改字典内容 删除字典数据 字典内置函数 字典是Python实现散列表数据结构的形式,表现映射的关系,一对一. 字典长什么样 {}这是一个空字典,可以看出字典是由两个花括号组成的. 在看这个{'a':1},这里面装了一对数据,'a'可称为键,1称为值 这个{'键1':'值1', '键2':'值2'}每一对数据 字典内能放什么 字典内的健是唯一的,在字典内所有内容中只存在一个,但值可以重复出现. 健只能是不变的值,比如字符串,数字,元组 值可以随意
-
Python OpenCV实现图形检测示例详解
目录 1. 轮廓识别与描绘 1.1 cv2.findComtours()方法 1.2 cv2.drawContours() 方法 1.3 代码示例 2. 轮廓拟合 2.1 矩形包围框拟合 - cv2.boundingRect() 2.2圆形包围框拟合 - cv2.minEnclosingCircle() 3. 凸包 绘制 4. Canny边缘检测 - cv2.Canny() 4.1 cv2.Canny() 用法简介 4.2 代码示例 5. 霍夫变换 5.1 概述 5.2 cv2.HoughLin
-
python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算. 希望能提供一些思路,如果觉得有用欢迎赞我表扬我~ IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度.系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的. 计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图: 蓝色的框是:GroundTruth 黄色的框是:Dete