Portia开源可视化爬虫工具的使用学习
目录
- 背景
- 安装
- 使用Portia包
- page sample
- 启动程序
- 总结
背景
由于最近在写一个可供配置的爬虫模板,方便快速扩展新的抓取业务,并且最后目标是将其做成一个可视化的配置服务。还正在进行中,并且有点没有头绪,所以想参考网上现有的轮子,看看能不能找到点新的思路。
安装
Docker安装完成后拉去portia服务项目
# < ..FOLDER> 路径自定义即可 , 可在后面加上portia的版本 docker run -i -t --rm -v <PROJECTS_FOLDER>:/app/data/projects:rw -p 9001:9001 scrapinghub/portia # git上是如下语句 docker run -v ~/portia_projects:/app/data/projects:rw -p 9001:9001 scrapinghub/portia
具体可参考官方文档
使用Portia包
新建project
Portia安装完成以后使用浏览器打开http://localhost:9001, 在create a new project 中输入项目名
点击 New spider 创建一个新的spider
右边侧栏会提示你输入一个url,Portia会将网页的url作为一个start page。
这个start page一般被用来当做seek(种子),用来获得更多的链接。

Portia支持创建 page sample(页面样本),当你创建了一个页面样本,就可以调度后面的任务按照你设定的模板抓取元素。(所以我们需要先创建这样的模板)
page sample
创建了sample之后,我们可以开始注释页面。注释会将页面中的一条数据链接到项目字段。这些即是我们想要提取的数据
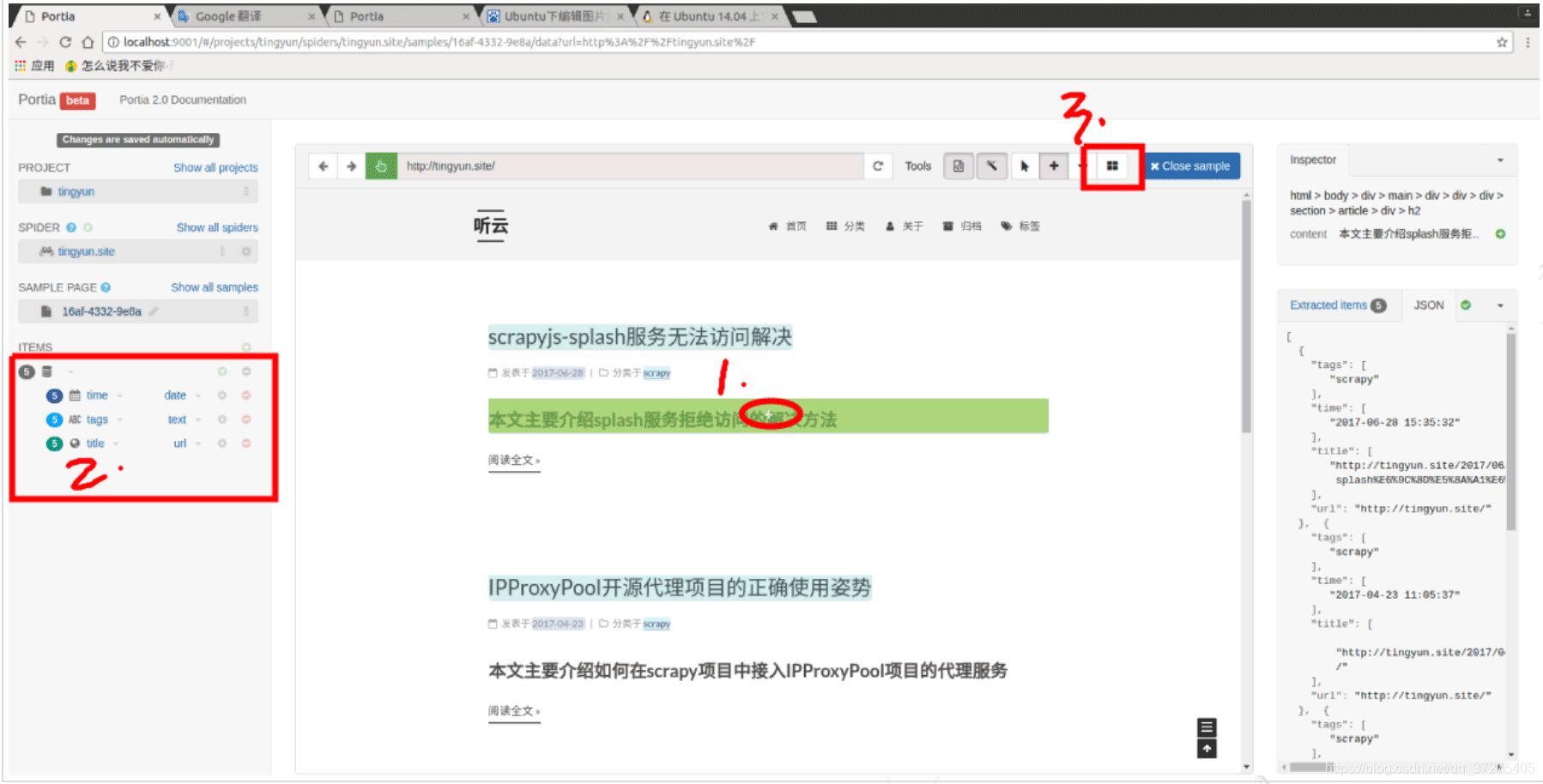
字段命名,选择数据类型

Portia默认遵循所有域内URL。在许多情况下,您需要限制Portia将访问的页面,以便不会在不相关的页面上浪费请求。
为此,您可以分别设置跟随和排除白名单和黑名单URL的模式。可以通过将爬网策略更改为来配置这些。Configure URL patterns

到此操作结束
可以在最右侧看到我们选中的项目,将所有需要提取的items注释完之后,关闭样本。Close Sample,如果以后需要再添加其他元素,继续配置此样本,方便后续的抓取。
最后,我们可以在右边看到我们需要的数据,json如下格式
启动程序
我们配置好了sample page和start pages,那么就要开始抓取数据了,也就是将数据保存到json文件或者数据库中。这里我们保存成json文件
官方给出的代码如下
docker run -i -t --rm -v PROJECTS_FOLDER:/app/data/projects:rw -v OUPUT_FOLDER:/mnt:rw -p 9001:9001 scrapinghub/portia \ portiacrawl /app/data/projects/PROJECT_NAME SPIDER_NAME -o /mnt/RESULT.json
其中可以更改的是大写的那些部分:PROJECTS_FOLDER / OUPUT_FOLDER / PROJECT_NAME / SPIDER_NAME / RESULT.json
依次是: 项目名 / 输出目录 / project的名字 / Spider名字 / 保存结果的文件
启动程序前必须先关闭Portia的调试页面,这里我直接使用kill命令,因为我在docker启动的终端按下ctrl+c 或 crtl+z都无效,只能用进程关闭
例如,我的启动代码如下:
docker run -i -t --rm -v ~/portia_projects:/app/data/projects:rw -v ~/result:/mnt:rw -p 9001:9001 scrapinghub/portia \ portiacrawl /app/data/projects/tingyun tingyun.site -o /mnt/tingyun.json
运行成功就能看见代码在飞快地跑了,而且都是我们想要的items
总结
到此,我们就结束了这一次使用Portia的抓取之旅,通过使用Portia确实能实现很快速简易的抓取功能,能将抓取过程可视化得呈现给操作者,还有其他有趣的功能在后续的学习中遇到再次分享给大家,接下来会去考虑试着将其用到一些大规模的抓取上,看看到底效果如何,更多关于Portia开源可视化爬虫工具的资料请关注我们其它相关文章!
相关推荐
-
Python HTML解析模块HTMLParser用法分析【爬虫工具】
本文实例讲述了Python HTML解析模块HTMLParser用法.分享给大家供大家参考,具体如下: 简介 先简略介绍一下.实际上,HTMLParser是python用来解析HTML的内置模块.它可以分析出HTML里面的标签.数据等等,是一种处理HTML的简便途径.HTMLParser采用的是一种事件驱动的模式,当HTMLParser找到一个特定的标记时,它会去调用一个用户定义的函数,以此来通知程序处理.它主要的用户回调函数的命名都是以"handle_"开头的,都是HTMLParse
-
node.js 基于cheerio的爬虫工具的实现(需要登录权限的爬虫工具)
公司有过一个需求,需要拿一个网页的的表格数据,数据量达到30w左右:为了提高工作效率. 结合自身经验和网上资料.写了一套符合自己需求的nodejs爬虫工具.也许也会适合你的. 先上代码.在做讲解 'use strict'; // 引入模块 const superagent = require('superagent'); const cheerio = require('cheerio'); const Excel = require('exceljs'); var baseUrl = '';
-
Java 爬虫工具Jsoup详解
Java 爬虫工具Jsoup详解 Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址.HTML 文本内容.它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据. jsoup 的主要功能如下: 1. 从一个 URL,文件或字符串中解析 HTML: 2. 使用 DOM 或 CSS 选择器来查找.取出数据: 3. 可操作 HTML 元素.属性.文本: jsoup 是基于 MIT 协议发布的,可放心使用于商业项目. js
-
Python爬虫工具requests-html使用解析
使用Python开发的同学一定听说过Requsts库,它是一个用于发送HTTP请求的测试.如比我们用Python做基于HTTP协议的接口测试,那么一定会首选Requsts,因为它即简单又强大.现在作者Kenneth Reitz 又开发了requests-html 用于做爬虫. 该项目从3月上线到现在已经7K+的star了! GiHub项目地址: https://github.com/kennethreitz/requests-html requests-html 是基于现有的框架 PyQuery
-
JAVA使用HtmlUnit爬虫工具模拟登陆CSDN案例
最近要弄一个爬虫程序,想着先来个简单的模拟登陆, 在权衡JxBrowser和HtmlUnit 两种技术, JxBowser有界面呈现效果,但是对于某些js跳转之后的效果获取比较繁琐. 随后考虑用HtmlUnit, 想着借用咱们CSND的登陆练练手.谁知道CSDN的登陆,js加载时间超长,不设置长一点的加载时间,按钮提交根本没效果,js没生效. 具体看代码注释吧. 奉劝做爬虫的同志们,千万别用CSDN登陆练手,坑死我了. maven配置如下: <dependencies> <!-- ht
-
Python大批量搜索引擎图像爬虫工具详解
python图像爬虫包 最近在做一些图像分类的任务时,为了扩充我们的数据集,需要在搜索引擎下爬取额外的图片来扩充我们的训练集.搞人工智能真的是太难了
-

Portia开源可视化爬虫工具的使用学习
目录 背景 安装 使用Portia包 page sample 启动程序 总结 背景 由于最近在写一个可供配置的爬虫模板,方便快速扩展新的抓取业务,并且最后目标是将其做成一个可视化的配置服务.还正在进行中,并且有点没有头绪,所以想参考网上现有的轮子,看看能不能找到点新的思路. 安装 Docker安装完成后拉去portia服务项目 # < ..FOLDER> 路径自定义即可 , 可在后面加上portia的版本 docker run -i -t --rm -v <PROJECTS_FOLDER
-
Nginx开源可视化配置工具NginxConfig使用教程
前言 Nginx是一款非常流行的Web服务器,作为程序员我相信大家没少和它打交道.在我使用Nginx的过程中,一直觉得它的配置很麻烦,尤其是在Linux服务器上用vim手撸配置的时候!最近发现一款开源的Nginx可视化配置工具NginxConfig,能轻松生成Nginx配置,推荐给大家! SpringBoot实战电商项目mall(50k+star)地址: https://github.com/macrozheng/mall NginxConfig简介 NginxConfig号称你唯一需要的Ngi
-
2018年Python值得关注的开源库、工具和开发者(总结篇)
1.开源库 Web 领域:Sanic https://github.com/channelcat/sanic 这个库的名字和之前一个很火的梗有关,有人在 youtube 上画 Sonic 那个蓝色小人,结果一本正经的画出了下面这货,给它起名叫 Sanic,还配了一句话是 Gotta go faster. 这个库和 Flask 类似,但是比它快很多,速度能在测试中达到每秒 36000 次请求.在2017年的 Star 增长数几乎是翻了一倍.Gotta go faster! 环境与包管理:Pipen
-
python爬虫工具例举说明
小编发现对于一些刚学python的初学者来说,学习基础的模块知识固然重要,但是更多的倾向于依赖一些实用小工具去解决问题.不得不说,为了省时省力小编刚学python的时候也用工具去处理了一些事情,发现效果还不错.这里把之前使用的python爬虫工具整理了出来,进行简单介绍和优势分析,下面一起来看看有哪些吧. 常见的爬虫软件大致可以划分为两大类:云爬虫和采集器 云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务. 采集器一般就是要下载安装在本机,然后
-
python爬虫Mitmproxy安装使用学习笔记
目录 一.简介和安装 1.1.概念和作用 概念 作用 1.2.安装 1.3.工具介绍 二.设置代理 2.1.PC端设置代理 2.2.PC端安装证书 2.3.移动端设置代理 三. mitmdump 3.1.插件使用 3.2.常用事件 3.2.1.request事件 3.2.2.response事件 3.3.下载图片 一.简介和安装 1.1.概念和作用 概念 Mitmproxy是一个免费的开源交互式的HTTPS代理.MITM即中间人攻击(Man-in-the-Middle Attack). 作用 代
-
python 爬虫之selenium可视化爬虫的实现
之所以把selenium爬虫称之为可视化爬虫 主要是相较于前面所提到的几种网页解析的爬虫方式 selenium爬虫主要是模拟人的点击操作 selenium驱动浏览器并进行操作的过程是可以观察到的 就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑 当然了,selenium也有无界面模式 快速入门 selenium基本介绍: selenium 是一套完整的web应用程序测试系统, 包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Contro
-
Nginx可视化配置工具NginxWebUI的使用
目录 NginxWebUI介绍 NginxWebUI功能说明 NginxWebUI安装 1.jar包运行方式 2.docker安装说明 NginxWebUI使用演示 介绍一款好用的网页版开源工具,同样它的功能也是Nginx配置生成器,功能非常强大,方便实用,它是:NginxWebUI. NginxWebUI介绍 NginxWebUI是一款方便实用的nginx 网页配置工具,可以使用 WebUI 配置 Nginx 的各项功能,包括端口转发,反向代理,ssl 证书配置,负载均衡等,最终生成「ngin
-
springboot框架阿里开源低代码工具LowCodeEngine
目录 前言 LowCodeEngine简介 搭建低代码平台 使用低代码平台 目标效果 总结 前言 解放双手!推荐一款阿里开源的低代码工具,YYDS! 之前分享过一些低代码相关的文章,发现大家还是比较感兴趣的.之前在我印象中低代码就是通过图形化界面来生成代码而已,其实真正的低代码不仅要负责生成代码,还要负责代码的维护,把它当做一站式开发平台也不为过!最近体验了一把阿里开源的低代码工具LowCodeEngine,确实是一款面向企业级的低代码解决方案,推荐给大家! SpringBoot实战电商项目ma