C++详解哈夫曼树的概念与实现步骤
目录
- 一、 基本概念
- 二、构造哈夫曼树
- 三、哈夫曼树的基本性质
- 四、哈夫曼编码
- 五、哈夫曼解码
- 六、文件的压缩和解压缩
一、 基本概念
结点的权: 有某种现实含义的数值
结点的带权路径长度: 从结点的根到该结点的路径长度与该结点权值的乘积
树的带权路径长度: 树上所有叶结点的带权路径长度之和


哈夫曼树: 在含有 n n n个带权叶结点的二叉树中, w p l wpl wpl 最小 的二叉树称为哈夫曼树,也称最优二叉树(给定叶子结点,哈夫曼树不唯一)。
二、构造哈夫曼树
比较简单,此处不赘述步骤


三、哈夫曼树的基本性质
- 每个初始结点最终都是叶结点,且权值越小的结点到根结点的路径长度越大
- 具有 n n n个根结点的哈夫曼树的结点总数为 2 n − 1
- 哈夫曼树中不存在度为1的结点
- 哈夫曼树不唯一,但 w p l必然相同且最优
四、哈夫曼编码
目的:为给定的字符集合构建二进制编码,使得编码的期望长度达到最短
在考试中,小渣利用哈夫曼编码老渣发电报传递100道选择题的答案,小渣传递了10个A、8个B、80个C、2个D,老渣利用哈夫曼编码的方式解码。
小渣构造的哈夫曼树如下:
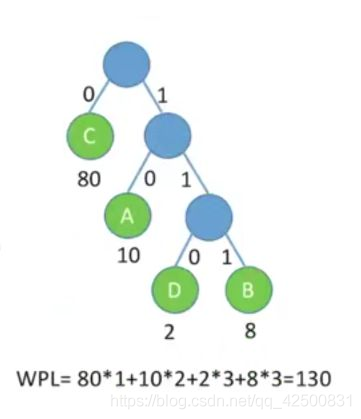
可以发现,A、B、C、D的编码分别为10、111、0、110。
这样小渣只要根据1~100题的答案顺序发送01序列,老渣收到后进行解码就能正确收到答案了。而且哈夫曼编码的方式不会有歧义,因为哈夫曼编码是一种前缀编码。
前缀编码: 没有一个编码是另一个编码的前缀,因为数据节点都是叶子节点。如果出现一个字符的编码是另一个字符编码的前缀,那这个字符一定处于内部节点,这是不可能的
由哈夫曼树得到的哈夫曼编码: 字符集中的每个字符都是以叶子结点出现在哈夫曼树中,各个字符出现的频率为结点的权值。
给字符串进行编码的时候,由于出现频率越高(权值大)的字符距离根节点越进,编码越短;只有出现频率越低(权值小)的字符距离根节点较远,编码长。没关系,由于频率高的字符编码都短,所以哈夫曼编码可以得到最短的编码序列

五、哈夫曼解码
哈夫曼编码不同于ASCII和Unicode这些字符编码,这些字符集中的码长都采用的是长度相同的编码方案,而哈夫曼编码使用的是变长编码,而且哈夫曼编码满足立刻可解码性(就是说任一字符的编码都不会是另一个更长字符编码的前缀),只要当某个字符的编码中所有位被全部接收时,可以立即进行解码而无须等待后面接收的位来决定是否存在另一个合法的更长的编码
第一张表不满足立刻可解码性,第二张表满足

我们接收100的时候,需要考虑是立刻解码成D还是等待接收下一位,如果下一位是0就可以解码成B,这就说明表中的编码不具有立刻可解码性

第二张表就具有立刻可解码性,因为任一字符的编码都不是另一个更长字符编码的前缀。只要收到的序列对应了某个字符的编码,直接解码成对应字符即可,无需等待后面的数据
我们的代码实现是用字符串构建哈夫曼树,只能针对由该字符串包含的字符组成的字符串进行编解码。代码里使用字符串存储的编码,实际上应该用bit进行存储
#include <iostream>
#include <string>
#include <vector>
#include <functional>
#include <unordered_map>
#include <queue>
using namespace std;
using uint = unsigned int;
class HuffmanTree {
public:
// 这里的lambda表达式用来初始化function函数对象
// priority_queue的构造函数指出,如果传入一个参数,那这个参数用来初始化比较器对象
// 如果传入两个参数,第一个是比较器对象,第二个是底层容器
HuffmanTree()
:min_heap_([](Node* n1, Node* n2)->bool {return n1->weight_ > n2->weight_; })
, root_(nullptr)
{}
~HuffmanTree() {
init();
cout << "已释放所有内存!" << endl;
}
// 根据字符串创建哈夫曼树
void create(const string& str) {
if (root_ != nullptr) {
cout << "哈夫曼树初始化..." << endl;
init();
cout << "初始化完成!" << endl;
}
// 统计频率(权重)
unordered_map<char, uint> w_map;
for (char c : str) {
w_map[c]++;
}
// 遍历w_map,把所有的字符对应的权重放入小根堆,按照权重排序
for (pair<const char, uint>& p : w_map) {
min_heap_.push(new Node(p.first, p.second));
}
// 根据优先级队列,从小根堆中取出节点,构建哈夫曼树
while (min_heap_.size() > 1) {
Node* n1 = min_heap_.top();
min_heap_.pop();
Node* n2 = min_heap_.top();
min_heap_.pop();
Node* node = new Node('\0', n1->weight_ + n2->weight_); // 内部节点存\0
node->left_ = n1;
node->right_ = n2;
min_heap_.push(node);
}
root_ = min_heap_.top();
min_heap_.pop();
// 创建完哈夫曼树,直接对传入的海量字符进行编码并存储到code_map_
create_huffman_code(str);
}
string get_code(const string& str) {
// 利用哈夫曼树对str编码并返回
string code;
for (char c : str) {
code += code_map_[c];
}
return code;
}
void show_huffman_code() const {
// 打印哈夫曼编码
for (const auto& pair : code_map_) {
cout << pair.first << " : " << pair.second << endl;
}
}
string decode(const string& encode_str) {
Node* cur = root_;
string decode_str;
for (char c : encode_str) {
if (c == '0') {
cur = cur->left_;
}
else {
cur = cur->right_;
}
if (cur->left_ == nullptr && cur->right_ == nullptr) {
// 到达叶子节点
decode_str.push_back(cur->data_);
cur = root_;
}
}
return decode_str;
}
uint get_wpl() {
if (root_ == nullptr) {
return 0;
}
if (root_->left_ == nullptr && root_->right_ == nullptr) {
// 对于叶子节点,直接返回自己的weight * depth
return root_->weight_ * 1;
}
else {
// 对于内部节点,直接返回从子节点拿到的weight之和
return get_w(root_->left_, 2) + get_w(root_->right_, 2);
}
}
private:
struct Node {
Node(char data, uint weight)
:data_(data)
, weight_(weight)
, left_(nullptr)
, right_(nullptr)
{}
char data_;
uint weight_;
Node* left_;
Node* right_;
};
private:
// 防止当前对象重新构建哈夫曼树,释放所有的节点,然后初始化私有成员
void init() {
// 释放哈夫曼树的节点
if (root_ != nullptr) {
queue<Node*> q;
q.push(root_);
while (!q.empty()) {
Node* node = q.front();
q.pop();
if (node->left_ != nullptr) {
q.push(node->left_);
}
if (node->right_ != nullptr) {
q.push(node->right_);
}
delete node;
}
MinHeap empty([](Node* n1, Node* n2)->bool {return n1->weight_ > n2->weight_; });
swap(empty, min_heap_);
code_map_.clear();
}
}
void create_huffman_code(const string& str) {
string code;
create_huffman_code(root_, code);
}
void create_huffman_code(Node* node, string code) {
if (node->left_ == nullptr && node->right_ == nullptr) {
code_map_[node->data_] = code;
return;
}
create_huffman_code(node->left_, code + "0");
create_huffman_code(node->right_, code + "1");
}
uint get_w(Node* node, int depth) {
if (node == nullptr) {
return 0;
}
if (node->left_ == nullptr && node->right_ == nullptr) {
// 对于叶子节点,直接返回自己的weight * depth
return node->weight_ * depth;
}
else {
// 对于内部节点,直接返回从子节点拿到的weight之和
return get_w(node->left_, depth + 1) + get_w(node->right_, depth + 1);
}
}
private:
Node* root_;
unordered_map<char, string> code_map_; // 存储字符对应的哈夫曼编码
using MinHeap = priority_queue<Node*, vector<Node*>, function<bool(Node*, Node*)>>;
MinHeap min_heap_; // 构建哈夫曼树的时候使用小根堆
};
int main() {
string str = "Aa";
HuffmanTree htree;
htree.create(str);
htree.show_huffman_code();
cout << htree.get_wpl() << endl;
str = "ABC";
htree.create(str);
htree.show_huffman_code();
cout << htree.get_wpl() << endl;;
string encode = htree.get_code(str);
cout << "encode:" << encode << endl;
cout << "decode:" << htree.decode(encode) << endl;
return 0;
}
六、文件的压缩和解压缩
我们利用哈夫曼编码压缩文件的时候,如果文件是100M,我们可以压缩成20M,如果文件时1K,我们可能压缩成2K,当文件较小的时候,我们得到的压缩文件反而更大了,这是为什么?
文件的压缩过程如下:
- 按字节读取原文件的所有内容,并统计字节数据的权值,构建哈夫曼树
- 通过哈夫曼树,得到文件的哈夫曼编码
- 把文件的内容按字节进行编码,将编码内容按bit存储成压缩文件,还要存储文件字节数据以及权值
解码的过程如下:
- 读取原始文件的字节数据以及权值,构建哈夫曼树
- 读取压缩文件的01码,利用哈夫曼树对01进行解码,将解码数据存储成新的文件,就解码出了原始文件
由于压缩文件不仅存储01码,还需要存储文件字节数据以及权值用来重建哈夫曼树(就是代码中的w_map)。当原始文件较小时,文件字节数据以及权值可能大于原始文件的大小,故小文件压缩后可能变大
到此这篇关于C++详解哈夫曼树的概念与实现步骤的文章就介绍到这了,更多相关C++哈夫曼树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++实现哈夫曼树的方法
序言 对于哈夫曼编码,个人的浅薄理解就是在压缩存储空间用很大用处. 用一个很简单例子,存储一篇英文文章时候,可能A出现的概率较大,Z出现的记录较小,如果正常存储,可能A与Z存储使用的空间一样.但是用哈夫曼编码方式,A经常出现,所用编码长度就短. 构造哈夫曼树,生成哈夫曼编码 一.定义节点类型 struct Node { char C; long key; Node *Left, *Right,*parent; Node() { Left = Right = NULL; } }; 二.定义树类型(
-
C++实现哈夫曼树算法
如何建立哈夫曼树的,网上搜索一堆,这里就不写了,直接给代码. 1.哈夫曼树结点类:HuffmanNode.h #ifndef HuffmanNode_h #define HuffmanNode_h template <class T> struct HuffmanNode { T weight; // 存储权值 HuffmanNode<T> *leftChild, *rightChild, *parent; // 左.右孩子和父结点 }; #endif /* HuffmanNode
-
C++数据结构之文件压缩(哈夫曼树)实例详解
C++数据结构之文件压缩(哈夫曼树)实例详解 概要: 项目简介:利用哈夫曼编码的方式对文件进行压缩,并且对压缩文件可以解压 开发环境:windows vs2013 项目概述: 1.压缩 a.读取文件,将每个字符,该字符出现的次数和权值构成哈夫曼树 b.哈夫曼树是利用小堆构成,字符出现次数少的节点指针存在堆顶,出现次数多的在堆底 c.每次取堆顶的两个数,再将两个数相加进堆,直到堆被取完,这时哈夫曼树也建成 d.从哈夫曼树中获取哈夫曼编码,然后再根据整个字符数组来获取出现了得字符的编
-

解析C++哈夫曼树编码和译码的实现
一.背景介绍: 给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近. 二.实现步骤: 1.构造一棵哈夫曼树 2.根据创建好的哈夫曼树创建一张哈夫曼编码表 3.输入一串哈夫曼序列,输出原始字符 三.设计思想: 1.首先要构造一棵哈夫曼树,哈夫曼树的结点结构包括权值,双亲,左右孩子:假如由n个字符来构造一棵哈夫曼树,则共有结点2n-1个:在构造前,先初始化
-
C++数据结构与算法之哈夫曼树的实现方法
本文实例讲述了C++数据结构与算法之哈夫曼树的实现方法.分享给大家供大家参考,具体如下: 哈夫曼树又称最优二叉树,是一类带权路径长度最短的树. 对于最优二叉树,权值越大的结点越接近树的根结点,权值越小的结点越远离树的根结点. 前面一篇图文详解JAVA实现哈夫曼树对哈夫曼树的原理与java实现方法做了较为详尽的描述,这里再来看看C++实现方法. 具体代码如下: #include <iostream> using namespace std; #if !defined(_HUFFMANTREE_H
-
C++ 哈夫曼树对文件压缩、加密实现代码
在以前写LZW压缩算法的时候,遇到很多难受的问题,基本上都在哈夫曼编码中解决了,虽然写这代码很费神,但还是把代码完整的码出来了,毕竟哈夫曼这个思想确实很牛逼.哈夫曼树很巧妙的解决了当时我在LZW序列化的时候想解决的问题,就是压缩后文本的分割.比如用lzw编码abc,就是1,2,3.但这个在存为文件的时候必须用分割符把1,2,3分割开,非常浪费空间,否则会和12 23 123 产生二义性.而哈夫曼树,将所有char分布在叶节点上,在还原的时候,比如1101110,假设110是叶节点,那么走到110
-
C++实现哈夫曼树编码解码
本文实例为大家分享了C++实现哈夫曼树的编码解码,供大家参考,具体内容如下 代码: #pragma once #include<iostream> #include<stack> using namespace std; #define m 20 stack<int> s; /*哈夫曼树结点类HuffmanNode声明*/ template<class T> class HuffmanNode { private: HuffmanNode<T>
-
C++实现哈夫曼树简单创建与遍历的方法
本文以实例形式讲述了C++实现哈夫曼树简单创建与遍历的方法,比较经典的C++算法. 本例实现的功能为:给定n个带权的节点,如何构造一棵n个带有给定权值的叶节点的二叉树,使其带全路径长度WPL最小. 据此构造出最优树算法如下: 哈夫曼算法: 1. 将n个权值分别为w1,w2,w3,....wn-1,wn的节点按权值递增排序,将每个权值作为一棵二叉树.构成n棵二叉树森林F={T1,T2,T3,T4,...Tn},其中每个二叉树都只有一个权值,其左右字数为空 2. 在森林F中选取根节点权值最小二叉树,
-
C++详解哈夫曼树的概念与实现步骤
目录 一. 基本概念 二.构造哈夫曼树 三.哈夫曼树的基本性质 四.哈夫曼编码 五.哈夫曼解码 六.文件的压缩和解压缩 一. 基本概念 结点的权: 有某种现实含义的数值 结点的带权路径长度: 从结点的根到该结点的路径长度与该结点权值的乘积 树的带权路径长度: 树上所有叶结点的带权路径长度之和 哈夫曼树: 在含有 n n n个带权叶结点的二叉树中, w p l wpl wpl 最小 的二叉树称为哈夫曼树,也称最优二叉树(给定叶子结点,哈夫曼树不唯一). 二.构造哈夫曼树 比较简单,此处不赘述步骤
-
使用C语言详解霍夫曼树数据结构
1.基本概念 a.路径和路径长度 若在一棵树中存在着一个结点序列 k1,k2,--,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径. 从 k1 到 kj 所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1. b.结点的权和带权路径长度 在许多应用中,常常将树中的结点赋予一个有着某种意义的实数,我们称此实数为该结点的权,(如下面一个树中的蓝色数字表示结点的权) 结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘
-
基于C语言利用哈夫曼树实现文件压缩的问题
一.哈夫曼树 具有n个权值的n个叶子结点,构造出一个二叉树,使得该树的带权路径长度(WPL)最小,则称此二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree). 注意:哈夫曼树是带权路径长度最短的树,且权值越大的叶子结点离根结点越近. 二.哈夫曼编码 哈夫曼编码是一种编码方式,又称"霍夫曼编码",其是可变字长的编码(VCL)的一种,是由霍夫曼于1952年提出的一种编码方式,有时被称为最佳编码,一般称为Huffman编码. 那么我们为什么要使用哈夫曼编码进行压缩?
-
Java实现赫夫曼树(哈夫曼树)的创建
目录 一.赫夫曼树是什么? 1.路径和路径长度 2.节点的权和带权路径长度 3.树的带权路径长度 二.创建赫夫曼树 1.图文创建过程 2.代码实现 一.赫夫曼树是什么? 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度(WPL)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近. 图1 一棵赫夫曼树 1.路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径.
-
C++使用数组来实现哈夫曼树
目录 写在前面 构造思想 算法设计 构造实例 理解代码 确定结构体 循环找出最小值 调用细节 调试试图 总结 写在前面 哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树.所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数).树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
图文详解JAVA实现哈夫曼树
前言 我想学过数据结构的小伙伴一定都认识哈夫曼,这位大神发明了大名鼎鼎的"最优二叉树",为了纪念他呢,我们称之为"哈夫曼树".哈夫曼树可以用于哈夫曼编码,编码的话学问可就大了,比如用于压缩,用于密码学等.今天一起来看看哈夫曼树到底是什么东东. 概念 当然,套路之一,首先我们要了解一些基本概念. 1.路径长度:从树中的一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目称为路径长度. 2.树的路径长度:从树根到每一个结点的路径长度之和,我们所说的完全
-
Python完成哈夫曼树编码过程及原理详解
哈夫曼树原理 秉着能不写就不写的理念,关于哈夫曼树的原理及其构建,还是贴一篇博客吧. https://www.jb51.net/article/97396.htm 其大概流程 哈夫曼编码代码 # 树节点类构建 class TreeNode(object): def __init__(self, data): self.val = data[0] self.priority = data[1] self.leftChild = None self.rightChild = None self.co