python selenium xpath定位操作
xpath是一种在xm文档中定位的语言,详细简介,请自行参照百度百科,本文主要总结一下xpath的使用方法,个人看法,如有不足和错误,敬请指出。
注意:xpath的定位 同一级别的多个标签 索引从1开始 而不是0
1. 绝对定位:
此方法最为简单,具体格式为
xxx.find_element_by_xpath("绝对路径")
具体例子:
xxx.find_element_by_xpath("/html/body/div[x]/form/input") x 代表第x个 div标签,注意,索引从1开始而不是0
此方法缺点显而易见,当页面元素位置发生改变时,都需要修改,因此,并不推荐使用。
2.相对路径:
相对路径,以‘//'开头,具体格式为
xxx.find_element_by_xpath("//标签")
具体例子:
xxx.find_element_by_xpath("//input[x]") 定位第x个input标签,[x]可以省略,默认为第一个
相对路径的长度和开始位置并不受限制,也可以采取以下方法
xxx.find_element_by_xpath("//div[x]/form[x]/input[x]"), [x]依然是可以省略的

("//*[@id='J_login_form']/dl/dt/input[@id='J_password']"
3.标签属性定位:
3.1标签属性定位,相对比较简单,也要求属性能够定位到唯一一个元素,如果存在多个相同条件的标签,默认只是第一个,具体格式
xxx.find_element_by_xpath("//标签[@属性==‘属性值']")
属性判断条件:最常见为id,name,class等等,目前属性的类别没有特殊限制,只要能够唯一标识一个元素都是可以的
具体例子
xxx.find_element_by_xpath("//a[@href='/industryMall/hall/industryIndex.ht']") xxx.find_element_by_xpath("//input[@value='确定']") xxx.find_element_by_xpath("//div[@class = 'submit']/input")
当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,具体例子
xxx..find_element_by_xpath("//input[@type='name' and @name='kw1']")
3.2 当标签属性很少,不足以唯一区别元素时,但是标签中间中间存在唯一的文本值,也可以定位,其具体格式
xxx.find_element_by_xpath("//标签[contains(text(),'文本值')]")
具体例子:
xxx.find_element_by_xpath("//iunpt[contains(text(),'型号:')]")
注意:尽量在html中复制此段文本,避免因为肉眼无法分辨的字符导致定位失败
3.3 其他的属性值如果太长,也可以采取模糊方法定位,直接上示例

xxx.find_element_by_xpath(“//a[contains(@href, ‘logout')]”)
3.4 XPath 关于网页中的动态属性的定位,例如,ASP.NET应用程序中动态生成id属性值,可以有以下四种方法:
a.starts-with例子: input[starts-with(@id,'ctrl')] 解析:匹配以ctrl开始的属性值
b.ends-with 例子:input[ends-with(@id,'_userName')] 解析:匹配以userName结尾的属性值
c.contains() 例子:Input[contains(@id,'userName')] 解析:匹配含有userName属性值
当然,如果上面的单一方法不能完成定位,也可以采取组合式定位 类似("//input[@id='kw1']//input[start-with(@id,'nice']/div[1]/form[3])
以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看xpath中支持的方法:
1、child 选取当前节点的所有子元素
2、parent 选取当前节点的父节点
3、descendant选取当前节点的所有后代元素(子、孙等)
4、ancestor 选取当前节点的所有先辈(父、祖父等)
5、descendant-or-self选取当前节点的所有后代元素(子、孙等)以及当前节点本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
7、preceding-sibling选取当前节点之前的所有同级节点
8、following-sibling选取当前节点之后的所有同级节点
9、preceding选取文档中当前节点的开始标签之前的所有节点
10、following选取文档中当前节点的结束标签之后的所有节点
11、self 选取当前节点
12、attribute 选取当前节点的所有属性
13、namespace选取当前节点的所有命名空间节点

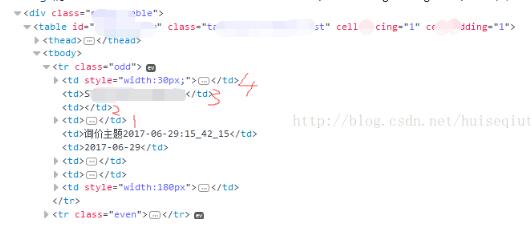
上图实例,需要点击订单号为17051915200001的发货按钮,这时候不能直接定位到发货按钮,而是先要定位到订单号元素,再定位他的兄弟节点。
参照上图,我们首先定位到td标签中包含订单号的td元素,然后选择其之后的同级节点,following-sibling,我们要找的元素在后面的第8个td标签下,因此定位可以写名为下面的格式
Xxx.find_element_by_xpath("//td[contains(text(),'17051915200001')]/following-sibling::td[8]/a[@class='link']")
preceding-sibling 情况类似,但是所有元素的排列顺序是相反的(和following-sibling相反),如图:
其他方法的使用方式相同, 11-13目前没有使用过,也没有搜索到实际使用的案例,如果有人知道,希望不吝赐教。
补充知识:Python+selenium:用“and”连接属性定位元素
如下所示:
find_element_by_xpath("//input[@id='kw' and @class='su']/span/input") //用and来连接属性定位元素
以上这篇python selenium xpath定位操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python Selenium自动化获取页面信息的方法
1.获取页面title title:获取当前页面的标题显示的字段 from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.baidu.com') #打印网页标题 print(browser.title) #输出内容:百度一下,你就知道 2.获取页面URL current_url:获取当前页面的URL from selenium import webdriver
-
Python selenium根据class定位页面元素的方法
在日常的网页源码中,我们基于元素的id去定位是最万无一失的,id在单个页面中是不会重复的.但是实际工作中,很多前端开发人员并未给每个元素都编写id属性.通常一段html代码如下: <div class="sui-tips s-isindex-wrap sui-tips-exceedtipnews" style="display: none; width: auto;"> <div class="sui-tips-arrow" s
-
python+Selenium自动化测试——输入,点击操作
这是我的第一个真正意思上的自动化脚本. 1.练习的测试用例为: 打开百度首页,搜索"胡歌",然后检索列表,有无"胡歌的新浪微博"这个链接 2.在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本. 此测试场景拆分如下: 1)启动Chrome浏览器 2)打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按
-
Selenium定位元素操作示例
本文实例讲述了Selenium定位元素操作.分享给大家供大家参考,具体如下: Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需
-
python selenium xpath定位操作
xpath是一种在xm文档中定位的语言,详细简介,请自行参照百度百科,本文主要总结一下xpath的使用方法,个人看法,如有不足和错误,敬请指出. 注意:xpath的定位 同一级别的多个标签 索引从1开始 而不是0 1. 绝对定位: 此方法最为简单,具体格式为 xxx.find_element_by_xpath("绝对路径") 具体例子: xxx.find_element_by_xpath("/html/body/div[x]/form/input") x 代表第x个
-

java selenium XPath 定位实现方法
xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. 阅读目录 什么是xpath xpath定位的缺点 testXpath.html 代码如下 绝对路径定位方式 使用浏览器调试工具,可以直接获取xpath语句 绝对路径的缺点 绝对路径和相对路径的区别 相对路径定位方式 使用索引号定位 使用页面属性定位 模糊定位starts-with关键字 模糊定位contains关键字 text() 函数 文本定位 什么是xpath xpath 是XML Path的简称, 由于H
-
Python selenium模拟手动操作实现无人值守刷积分功能
经常为学校的各种刷分而发愁,得知开学无望,日后还要刷课,索性自动化一次,学而不用乃愚昧 聪慧 四大模块 初始化 from selenium import webdriver if __name__ == '__main__': driver = webdriver.Chrome() url = 'https://pc.xuexi.cn/points/login.html?ref=https://pc.xuexi.cn/points/my-points.html' driver.get(url =
-
Python Selenium XPath根据文本内容查找元素的方法
问题现象 元素的属性中没有id.name:虽然有class,但比较大众化,且位置也不固定:例如:页码中的下一页:那该如何找到该元素? <a class="paging">上一页</div> <a class="paging">1</div> <a class="paging">2</div> <a class="paging">下一页</
-
Python爬虫Xpath定位数据的两种方法
方法一:直接右键,将文章路径复制下来点击Copy full Xpath 使用selenium+lxml中的etree进行配合使用,使用etree解析html网页 import requests from lxml import etree import time import socket import csv from selenium import webdriver from configparser import ConfigParser from selenium.webdriver
-
玩转python selenium鼠标键盘操作(ActionChains)
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击.双击.点击鼠标右键.拖拽等等.而selenium给我们提供了一个类来处理这类事件--ActionChains selenium.webdriver.common.action_chains.ActionChains(driver) 这个类基本能够满足我们所有对鼠标操作的需求. 1.ActionChains基本用法 首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行
-
Python+Selenium实现读取网易邮箱验证码
前面写到了一些关于python+Selenium的基础操作 的教程,这篇文章将讲解一些实战内容. 在自动化工作中,有可能会遇到一些发送邮箱验证码类似的功能,如下 我们一般的解决思路就是 : 发送邮件—>打开邮箱—>输入邮箱账户密码—>登录邮箱—>打开未读邮件—>获取验证码—>保存验证码—>读取验证码 以下是一个实现打开网易邮箱读取未读邮件获取验证码的代码 def wangyi(self,username, password, name): dr = webdriv
-
Python selenium的基本使用方法分析
本文实例讲述了Python selenium的基本使用方法.分享给大家供大家参考,具体如下: selenium是一个web自动化测试工具,selenium可以直接运行在浏览器上,可以接收指令,让浏览器自动加载页面,获取需要的数据. selenium的基本使用 1.导包 from selenium import webdriver 2.创建driver对象 webdriver.PhantomJS() 3.请求数据 driver.get("http://www.baidu.com") 4.
-
python+selenium select下拉选择框定位处理方法
一.前言 总结一下python+selenium select下拉选择框定位处理的两种方式,以备后续使用时查询: 二.直接定位(XPath) 使用Firebug找到需要定位到的元素,直接右键复制XPath,使用find_element_by_xpath定位: driver = webdriver.Firefox() driver.get("https://www.baidu.com/") driver.find_element_by_xpath().click() 三.间接定位(Sel