go语言编程学习实现图的广度与深度优先搜索
目录
- 图的实现
- BFS
- DFS
图的实现
所谓图就是节点及其连接关系的集合。所以可以通过一个一维数组表示节点,外加一个二维数组表示节点之间的关系。
//图的矩阵实现
typedef struct MGRAPH{
nodes int[]; //节点
edges int[][]; //边
}mGraph;

然而对于一些实际问题,其邻接矩阵中可能存在大量的0值,此时可以通过邻接链表来表示稀疏图,其数据结构如图所示

其左侧为图的示意图,右侧为图的邻接链表。红字表示节点序号,链表中为与这个节点相连的节点,如1节点与2、5节点相连。由于在go中,可以很方便地使用数组来代替链表,所以其链表结构可以写为
package main
import "fmt"
type Node struct{
value int; //节点为int型
};
type Graph struct{
nodes []*Node
edges map[Node][]*Node //邻接表示的无向图
}
其中,map为Go语言中的键值索引类型,其定义格式为map[<op1>]<op2>,<op1>为键,<op2>为值。在图结构中,map[Node][]*Node表示一个Node对应一个Node指针所组成的数组。
下面将通过Go语言生成一个图
//增加节点
//可以理解为Graph的成员函数
func (g *Graph) AddNode(n *Node) {
g.nodes = append(g.nodes, n)
}
//增加边
func (g *Graph) AddEdge(u, v *Node) {
g.edges[*u] = append(g.edges[*u],v) //u->v边
g.edges[*v] = append(g.edges[*v],u) //u->v边
}
//打印图
func (g *Graph) Print(){
//range遍历 g.nodes,返回索引和值
for _,iNode:=range g.nodes{
fmt.Printf("%v:",iNode.value)
for _,next:=range g.edges[*iNode]{
fmt.Printf("%v->",next.value)
}
fmt.Printf("\n")
}
}
func initGraph() Graph{
g := Graph{}
for i:=1;i<=5;i++{
g.AddNode(&Node{i,false})
}
//生成边
A := [...]int{1,1,2,2,2,3,4}
B := [...]int{2,5,3,4,5,4,5}
g.edges = make(map[Node][]*Node)//初始化边
for i:=0;i<7;i++{
g.AddEdge(g.nodes[A[i]-1], g.nodes[B[i]-1])
}
return g
}
func main(){
g := initGraph()
g.Print()
}
其运行结果为
PS E:\Code> go run .\goGraph.go 1:2->5-> 2:1->3->4->5-> 3:2->4-> 4:2->3->5-> 5:1->2->4->
BFS
广度优先搜索(BFS)是最简单的图搜索算法,给定图的源节点后,向外部进行试探性地搜索。其特点是,通过与源节点的间隔来调控进度,即只有当距离源节点为 k k k的节点被搜索之后,才会继续搜索,得到距离源节点为 k + 1 k+1 k+1的节点。
对于图的搜索而言,可能存在重复的问题,即如果1搜索到2,相应地2又搜索到1,可能就会出现死循环。因此对于图中的节点,我们用searched对其进行标记,当其值为false时,说明没有被搜索过,否则则说明已经搜索过了。
type Node struct{
value int;
searched bool;
}
/*func initGraph() Graph{
g := Graph{}
*/
//相应地更改节点生成函数
for i:=1;i<=5;i++{
g.AddNode(&Node{i,false})
}
/*
...
*/
此外,由于在搜索过程中会改变节点的属性,所以map所对应哈希值也会发生变化,即Node作为键值将无法对应原有的邻接节点,所以Graph中边的键值更替为节点的指针,这样即便节点的值发生变化,但其指针不会变化。
type Graph struct{
nodes []*Node
edges map[*Node][]*Node //邻接表示的无向图
}
//增加边
func (g *Graph) AddEdge(u, v *Node) {
g.edges[u] = append(g.edges[u],v) //u->v边
g.edges[v] = append(g.edges[v],u) //u->v边
}
//打印图
func (g *Graph) Print(){
//range遍历 g.nodes,返回索引和值
for _,iNode:=range g.nodes{
fmt.Printf("%v:",iNode.value)
for _,next:=range g.edges[iNode]{
fmt.Printf("%v->",next.value)
}
fmt.Printf("\n")
}
}
func initGraph() Graph{
g := Graph{}
for i:=1;i<=9;i++{
g.AddNode(&Node{i,false})
}
//生成边
A := [...]int{1,1,2,2,2,3,4,5,5,6,1}
B := [...]int{2,5,3,4,5,4,5,6,7,8,9}
g.edges = make(map[*Node][]*Node)//初始化边
for i:=0;i<11;i++{
g.AddEdge(g.nodes[A[i]-1], g.nodes[B[i]-1])
}
return g
}
func (g *Graph) BFS(n *Node){
var adNodes[] *Node //存储待搜索节点
n.searched = true
fmt.Printf("%d:",n.value)
for _,iNode:=range g.edges[n]{
if !iNode.searched {
adNodes = append(adNodes,iNode)
iNode.searched=true
fmt.Printf("%v ",iNode.value)
}
}
fmt.Printf("\n")
for _,iNode:=range adNodes{
g.BFS(iNode)
}
}
func main(){
g := initGraph()
g.Print()
g.BFS(g.nodes[0])
}
该图为
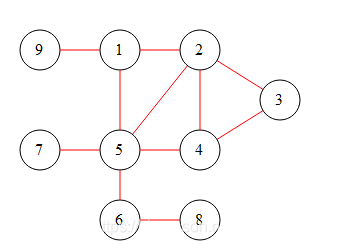
输出结果为
PS E:\Code\goStudy> go run .\goGraph.go 1:2->5->9-> 2:1->3->4->5-> 3:2->4-> 4:2->3->5-> 5:1->2->4->6->7-> 6:5->8-> 7:5-> 8:6-> 9:1-> //下面为BFS结果 1:2 5 9 2:3 4 3: 4: 5:6 7 6:8 8: 7: 9:
DFS
深度优先遍历(DFS)与BFS的区别在于,后者的搜索过程可以理解为逐层的,即可将我们初始搜索的节点看成父节点,那么与该节点相连接的便是一代节点,搜索完一代节点再搜索二代节点。DFS则是从父节点搜索开始,一直搜索到末代节点,从而得到一个末代节点的一条世系;然后再对所有节点进行遍历,找到另一条世系,直至不存在未搜索过的节点。
其基本步骤为:
- 首先选定一个未被访问过的顶点 V 0 V_0 V0作为初始顶点,并将其标记为已访问
- 然后搜索 V 0 V_0 V0邻接的所有顶点,判断是否被访问过,如果有未被访问的顶点,则任选一个顶点 V 1 V_1 V1进行访问,依次类推,直到 V n V_n Vn不存在未被访问过的节点为止。
- 若此时图中仍旧有顶点未被访问,则再选取其中一个顶点进行访问,否则遍历结束。
我们先实现第二步,即单个节点的最深搜索结果
func (g *Graph) visitNode(n *Node){
for _,iNode:= range g.edges[n]{
if !iNode.searched{
iNode.searched = true
fmt.Printf("%v->",iNode.value)
g.visitNode(iNode)
return
}
}
}
func main(){
g := initGraph()
g.nodes[0].searched = true
fmt.Printf("%v->",g.nodes[0].value)
g.visitNode(g.nodes[0])
}
结果为
PS E:\Code> go run .\goGraph.go 1->2->3->4->5->6->8->
即

可见,还有节点7、9未被访问。
完整的DFS算法只需在单点遍历之前,加上一个对所有节点的遍历即可
func (g *Graph) DFS(){
for _,iNode:=range g.nodes{
if !iNode.searched{
iNode.searched = true
fmt.Printf("%v->",iNode.value)
g.visitNode(iNode)
fmt.Printf("\n")
g.DFS()
}
}
}
func main(){
g := initGraph()
g.nodes[0].searched = true
fmt.Printf("%v->",g.nodes[0].value)
g.visitNode(g.nodes[0])
}
结果为
PS E:\Code> go run .\goGraph.go 1->2->3->4->5->6->8-> 7-> 9->
以上就是go语言编程学习实现图的广度与深度优先搜索的详细内容,更多关于go语言实现图的广度与深度优先搜索的资料请关注我们其它相关文章!
相关推荐
-

详解Go语言运用广度优先搜索走迷宫
目录 一.理解广度优先算法 1.1.分析如何进行广度优先探索 1.2.我们来总结一下 1.3.代码分析 二.代码实现广度优先算法走迷宫 一.理解广度优先算法 我们要实现的是广度优先算法走迷宫 比如,我们有一个下面这样的迷宫 这个迷宫是6行5列 其中0代表可以走的路, 1代表一堵墙. 我们把墙标上言责, 就如右图所示. 其中(0,0)是起点, (6, 5)是终点. 我们要做的是, 从起点走到终点最近的路径. 这个例子是抛转隐喻, 介绍广度优先算法, 广度优先算法的应用很广泛, 所以, 先来看看规律
-
go语言实现将重要数据写入图片中
原理:将数据的二进制形式写入图像红色通道数据二进制的低位 只支持png格式的输出 写入数据 go run shadow.go -in="c.jpg" -data="hide me" -out="out.png" 读取数据 go run shadow.go -in="out.png" 复制代码 代码如下: package main import ( "errors" "flag&qu
-
Go语言实现的树形结构数据比较算法实例
本文实例讲述了Go语言实现的树形结构数据比较算法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: // Two binary trees may be of different shapes, // but have the same contents. For example: // // 4 6 // 2 6 4 7 // 1 3 5 7 2 5 //
-
go语言编程学习实现图的广度与深度优先搜索
目录 图的实现 BFS DFS 图的实现 所谓图就是节点及其连接关系的集合.所以可以通过一个一维数组表示节点,外加一个二维数组表示节点之间的关系. //图的矩阵实现 typedef struct MGRAPH{ nodes int[]; //节点 edges int[][]; //边 }mGraph; 然而对于一些实际问题,其邻接矩阵中可能存在大量的0值,此时可以通过邻接链表来表示稀疏图,其数据结构如图所示 其左侧为图的示意图,右侧为图的邻接链表.红字表示节点序号,链表中为与这个节点相连的节点,
-
R语言编程学习绘制动态图实现示例
在讨论级数时,可能需要比对前 n n n项和的变化情况,而随着 n n n的递增,通过动态图来反映这种变化会更加直观,而通过R语言绘制动态图也算是一门不那么初级的技术,所以在此添加一节,补充一下R语言的绘图知识. 绘图需要用到ggplot2,为多张图加上时间轴则需要用到gganimate,为了让这些动态图片被渲染,需要用到av.此外,ggplot2绘图需要输入的数据格式为tibble. install.packages("ggplot2") install.packages("
-
Go语言编程学习golang配置golint
目录 下载golint 打开setting对话框 设置一个快捷键 下载golint 下载golang 的 lint,下载地址:https://github.com/golang/lint mkdir -p $GOPATH/src/golang.org/x/ cd $GOPATH/src/golang.org/x/ git clone https://github.com/golang/lint.git git clone https://github.com/golang/tools.git 到
-
Python实现图的广度和深度优先路径搜索算法
目录 前言 1. 图理论 1.1 图的概念 1.2 定义图 1.3 图的抽象数据结构 2. 图的存储实现 2.1 邻接矩阵 2.2 编码实现邻接矩阵 3. 搜索路径 3.1 广度优先搜索 3.2 深度优先搜索算法 4. 总结 前言 图是一种抽象数据结构,本质和树结构是一样的. 图与树相比较,图具有封闭性,可以把树结构看成是图结构的前生.在树结构中,如果把兄弟节点之间或子节点之间横向连接,便构建成一个图. 树适合描述从上向下的一对多的数据结构,如公司的组织结构. 图适合描述更复杂的多对多数据结构,
-
R语言编程学习从Github上安装包解决网络问题
目录 1. remotes 包安装 2. devtools 包安装 3. 从 gitee.com 上安装 4. 离线安装 1)先从 GitHub 上 下载 zip 压缩文件: 2)在本地 R Studio 上进行安装: 当我们想使用 R 安装一些 Github 相关的软件包,经常会遇到或者或那的网络问题,此时我们需要怎么做呢? 以最近大家分析疫情数据经常用的 Y叔的 nCov2019 包为例,通常我们可以使用如下的尝试顺序: 1. remotes 包安装 install.packages("re
-
C语言实现图的遍历之深度优先搜索实例
DFS(Depth-First-Search)深度优先搜索算法是图的遍历算法中非常常见的一类算法.分享给大家供大家参考.具体方法如下: #include <iostream> #include <algorithm> #include <iterator> using namespace std; #define MAX_VERTEX_NUM 10 struct Node { int adjvex; struct Node *next; int info; }; typ
-
C语言编程中常见的五种错误及对应解决方案
目录 1. 未初始化的变量 2. 数组越界 3. 字符串溢出 4. 重复释放内存 5. 使用无效的文件指针 前言: C 语言有时名声不太好,因为它不像近期的编程语言(比如 Rust)那样具有内存安全性.但是通过额外的代码,一些最常见和严重的 C 语言错误是可以避免的. 即使是最好的程序员也无法完全避免错误.这些错误可能会引入安全漏洞.导致程序崩溃或产生意外操作,具体影响要取决于程序的运行逻辑. 下文讲解了可能影响应用程序的五个错误以及避免它们的方法: 1. 未初始化的变量 程序启动时,系统会为其
-
C语言编程计算信噪比SNR理解学习
目录 概念 计算方法 相关认知 Taprint中的信噪比 实例 概念 这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或信息),并且该种信号并不随原信号的变化而变化. 计算方法 信噪比的计量单位是dB,其计算方法是10lg(Ps/Pn),其中Ps和Pn分别代表信号与噪声的有效功率,也可以换算成电压幅值的比率关系:20Lg(Vs/Vn),Vs和Vn分别代表信号和噪声电压的"有效值". 在音频放大器中,我们希望
-
C语言编程PAT乙级学习笔记示例分享
目录 1001 害死人不偿命的(3n+1)猜想 1002 写出这个数 1003 我要通过! 1004 成绩排名 1005 继续(3n+1)猜想 1006 换个格式输出整数 1007 素数对猜想问题 1008 数组元素循环右移问题 1009 说反话 1010 一元多项式求导 1011 A+B 和 C 1012 数字分类 1013 数素数 1014 福尔摩斯的约会 1001 害死人不偿命的(3n+1)猜想 #include<iostream> #include<stack> using
-
常用的C语言编程工具汇总
中国有句古话叫做"工欲善其事,必先利其器",可见我们对工具的利用是从祖辈就传下来的,而且也告诉我们在开始做事之前先要把工具准备好.有了好的工具那么我们做起事来也会事半功倍.学习C语言也是一样的,对于初学者来说往往选择一款好的编程工具是很头大的事情.下面小编就给大家点评几款常用的C语言编程工具,究竟那款适合你,由你自己决定. VC++ 6.0 本站下载地址: 点击下载 这款软件相信大家看到名字就觉得很亲切的,也是大家吐槽最多的.中国大学的计算机专业学习C语言的必备神器,也算是比较古老