Python实现数据透视表详解
目录
- 1.groupby + agg
- 2. crosstab
- 3.groupby + pivot
- pivot_table
- 总结
用Python里的Pandas可以实现,虽然感觉Excel更方便
1.groupby + agg
不够直观,不好看
对贷款年份,贷款种类创建数据透视
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))

2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的参数:
index:选哪个变量做数据透视表的行
columns:选哪个变量做数据透视表的列
values:要聚合的值
aggfunc:使用的聚合函数
margins:是否添加汇总列/行
margins_name:汇总行/列的名字
例子
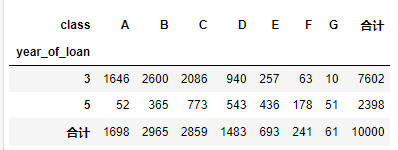
对贷款年份,贷款种类创建数据透视
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合计')

可以直接看出交叉组合之后违约比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
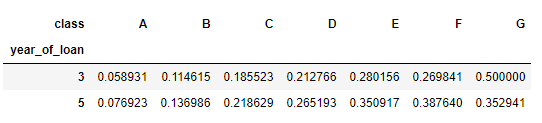
3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
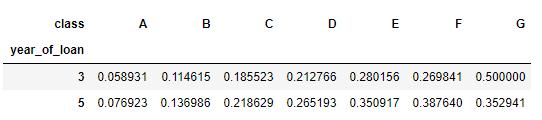
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用参数与crosstab一致
例子
实现同样的数据透视表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Python Pivot table透视表使用方法解析
Pivot 及 Pivot_table函数用法 Pivot和Pivot_table函数都是对数据做透视表而使用的.其中的区别在于Pivot_table可以支持重复元素的聚合操作,而Pivot函数只能对不重复的元素进行聚合操作. 在一般的日常业务中,因为Pivot_table的功能更为强大,Pivot能做的不能做的Pivot_table都可做.所以只需要记住Pivot_table函数用法就好了. Pivot函数的使用演示 #%% import pandas as pd df01 = pd.Data
-
用Python实现数据的透视表的方法
在处理数据时,经常需要对数据分组计算均值或者计数,在Microsoft Excel中,可以通过透视表轻易实现简单的分组运算.而对于更加复杂的分组运算,Python中pandas包可以帮助我们实现. 1 数据 首先引入几个重要的包: import pandas as pd import numpy as np from pandas import DataFrame,Series 通过代码构造数据集: data=DataFrame({'key1':['a','b','c','a','c','a',
-

python 用pandas实现数据透视表功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式.对于熟练使用 excel 的伙伴来说,一定很是亲切! pd.pivot_table() 语法: pivot_table(data, # DataFrame values=None, # 值 index=None, # 分类汇总依据 columns=None, # 列 aggfunc='mean', # 聚合函数 fill_value=None, # 对缺失值的填充 margins=False, # 是否启用总计行/列 dropna=True,
-
Python实现数据透视表详解
目录 1.groupby + agg 2. crosstab 3.groupby + pivot pivot_table 总结 用Python里的Pandas可以实现,虽然感觉Excel更方便 1.groupby + agg 不够直观,不好看 对贷款年份,贷款种类创建数据透视 train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean')) 2. crosstab pandas.crosstab(in
-
Python 处理数据的实例详解
Python 处理数据的实例详解 最近用python(3.2的版本)写了根据特定规则,处理数据的一个小程序,用到了一些python常用的基础知识,在此总结一下: 1,python读文件 2,python写文件 3,python的流程控制 4,python的for循环 5,python的集合,或字符串里判断是否存在某个元素 6,python的逻辑或,逻辑与 7,python的正则过滤 8,python的字符串忽略空格,和以某个字符串开头和按某个字符拆分成list python的打开文件的模式: 关
-
Python pyecharts数据可视化实例详解
目录 一.数据可视化 1.pyecharts介绍 2.初入了解 (1).快速上手 (2).简单的配置项介绍 3.案例实战 (1).柱状图Bar (2).地图Map (3).饼图Pie (4).折线图Line (5).组合图表 二.案例数据获取 总结 一.数据可视化 1.pyecharts介绍 官方网址:https://pyecharts.org/#/zh-cn/intro 概况: Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,使用JavaScript实现的.
-
Python股票数据可视化代码详解
目录 数据准备 阿里巴巴 谷歌 苹果 腾讯 亚马逊 Facebook 数据可视化 查看各个公司的股价平均值 查看各公司股价分布情况 股价走势对比 总结 import numpy as np import pandas as pd from pandas_datareader import data import datetime as dt 数据准备 ''' 获取国内股票数据的方式是:"股票代码"+"对应股市"(港股为.hk,A股为.ss) 例如腾讯是港股是:070
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
Python制作数据分析透视表的方法详解
目录 1.pivot_table函数index属性 2.pivot_table函数values属性 3.pivot_table函数aggfunc属性 4.pivot_table函数columns属性 透视表是一种可以对数据动态排布并且分类汇总的表格格式,在常用的python的数据分析非标准库pandas中体现为pivot_table模块. pivot_table数据透视表可以灵活的定制数据分析需求进行汇总,当然在Excel办公操作中早就存在了数据透视表的工具.如今,数据透视表被应用在python
-
对python抓取需要登录网站数据的方法详解
scrapy.FormRequest login.py class LoginSpider(scrapy.Spider): name = 'login_spider' start_urls = ['http://www.login.com'] def parse(self, response): return [ scrapy.FormRequest.from_response( response, # username和password要根据实际页面的表单的name字段进行修改 formdat
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
Python数据结构与算法之跳表详解
目录 0. 学习目标 1. 跳表的基本概念 1.1 跳表介绍 1.2 跳表的性能 1.3 跳表与普通链表的异同 2. 跳表的实现 2.1 跳表结点类 2.2 跳表的初始化 2.3 获取跳表长度 2.4 读取指定位置元素 2.5 查找指定元素 2.6 在跳表中插入新元素 2.7 删除跳表中指定元素 2.8 其它一些有用的操作 3. 跳表应用 3.1 跳表应用示例 0. 学习目标 在诸如单链表.双线链表等普通链表中,查找.插入和删除操作由于必须从头结点遍历链表才能找到相关链表,因此时间复杂度均为O(