ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境的详细教程
准备4台虚拟机,安装好ol7.7,分配固定ip192.168.168.11 12 13 14,其中192.168.168.11作为master,其他3个作为slave,主节点也同时作为namenode的同时也是datanode,192.168.168.14作为datanode的同时也作为secondary namenodes
首先修改/etc/hostname将主机名改为master、slave1、slave2、slave3
然后修改/etc/hosts文件添加
192.168.168.11 master 192.168.168.12 slave1 192.168.168.13 slave2 192.168.168.14 slave3
然后卸载自带openjdk改为sun jdk,参考https://www.cnblogs.com/yongestcat/p/13222963.html
配置无密码登陆本机
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
配置互信
master上把公钥传输给各个slave
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@slave3:/home/hadoop/
在slave主机上将master的公钥加入各自的节点上
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
master上安装hadoop
sudo tar -xzvf ~/hadoop-3.2.1.tar.gz -C /usr/local sudo mv hadoop-3.2.1-src/ ./hadoop sudo chown -R hadoop: ./hadoop
.bashrc添加并使之生效
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
集群配置,/usr/local/hadoop/etc/hadoop目录中有配置文件:
修改core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/nameNode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/dataNode</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>slave3:50090</value> </property> </configuration>
修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改hadoop-env.sh找到JAVA_HOME的配置将目录修改为
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
修改workers
[hadoop@master /usr/local/hadoop/etc/hadoop]$ vim workers master slave1 slave2 slave3
最后将配置好的/usr/local/hadoop文件夹复制到其他节点
sudo scp -r /usr/local/hadoop/ slave1:/usr/local/ sudo scp -r /usr/local/hadoop/ slave2:/usr/local/ sudo scp -r /usr/local/hadoop/ slave3:/usr/local/
并且把文件夹owner改为hadoop
sudo systemctl stop firewalld sudo systemctl disable firewalld
关闭防火墙
格式化hdfs,首次运行前运行,以后不用,在任意节点执行都可以/usr/local/hadoop/bin/hadoop namenode –format

看到这个successfuly formatted就是表示成功
start-dfs.sh启动集群hdfs
jps命令查看运行情况
 通过master的9870端口可以网页监控http://192.168.168.11:9870/
通过master的9870端口可以网页监控http://192.168.168.11:9870/

也可以通过命令行查看集群状态hadoop dfsadmin -report
[hadoop@master ~]$ hadoop dfsadmin -report WARNING: Use of this script to execute dfsadmin is deprecated. WARNING: Attempting to execute replacement "hdfs dfsadmin" instead. Configured Capacity: 201731358720 (187.88 GB) Present Capacity: 162921230336 (151.73 GB) DFS Remaining: 162921181184 (151.73 GB) DFS Used: 49152 (48 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (4): Name: 192.168.168.11:9866 (master) Hostname: master Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9796546560 (9.12 GB) DFS Remaining: 40636280832 (37.85 GB) DFS Used%: 0.00% DFS Remaining%: 80.58% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.12:9866 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9710411776 (9.04 GB) DFS Remaining: 40722415616 (37.93 GB) DFS Used%: 0.00% DFS Remaining%: 80.75% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.13:9866 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9657286656 (8.99 GB) DFS Remaining: 40775540736 (37.98 GB) DFS Used%: 0.00% DFS Remaining%: 80.85% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.14:9866 (slave3) Hostname: slave3 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9645883392 (8.98 GB) DFS Remaining: 40786944000 (37.99 GB) DFS Used%: 0.00% DFS Remaining%: 80.87% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 [hadoop@master ~]$
start-yarn.sh可以开启yarn,可以通过master8088端口监控
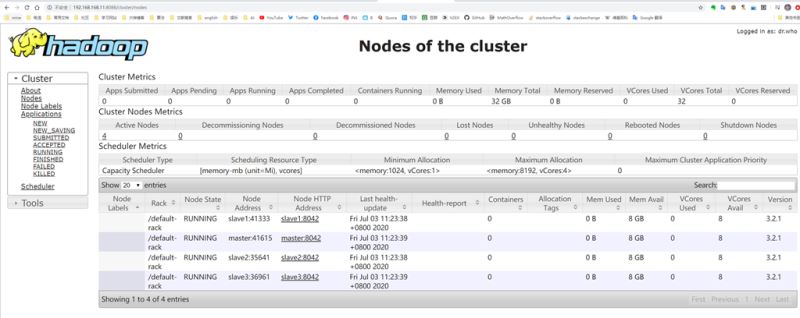
启动集群命令,可以同时开启hdfs和yarn /usr/local/hadoop/sbin/start-all.sh
停止集群命令 /usr/local/hadoop/sbin/stop-all.sh
就这样,记录过程,以备后查
到此这篇关于ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境的文章就介绍到这了,更多相关ol7.7安装部署hadoop分布式集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
在Hadoop集群环境中为MySQL安装配置Sqoop的教程
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中. Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS. 一.安装sqoop 1.下载sqoop压缩包,并解压 压缩包分别是:sqoop-1.2.0-CDH3B4.tar.gz,hadoop-0.20.2-C
-
java结合HADOOP集群文件上传下载
对HDFS上的文件进行上传和下载是对集群的基本操作,在<HADOOP权威指南>一书中,对文件的上传和下载都有代码的实例,但是对如何配置HADOOP客户端却是没有讲得很清楚,经过长时间的搜索和调试,总结了一下,如何配置使用集群的方法,以及自己测试可用的对集群上的文件进行操作的程序.首先,需要配置对应的环境变量: 复制代码 代码如下: hadoop_HOME="/home/work/tools/java/hadoop-client/hadoop" for f in $hadoo
-
Hadoop单机版和全分布式(集群)安装
Hadoop,分布式的大数据存储和计算, 免费开源!有Linux基础的同学安装起来比较顺风顺水,写几个配置文件就可以启动了,本人菜鸟,所以写的比较详细.为了方便,本人使用三台的虚拟机系统是Ubuntu-12.设置虚拟机的网络连接使用桥接方式,这样在一个局域网方便调试.单机和集群安装相差不多,先说单机然后补充集群的几点配置. 第一步,先安装工具软件编辑器:vim 复制代码 代码如下: sudo apt-get install vim ssh服务器: openssh,先安装ssh是为了使用远程终端工
-
详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境的详细教程
准备4台虚拟机,安装好ol7.7,分配固定ip192.168.168.11 12 13 14,其中192.168.168.11作为master,其他3个作为slave,主节点也同时作为namenode的同时也是datanode,192.168.168.14作为datanode的同时也作为secondary namenodes 首先修改/etc/hostname将主机名改为master.slave1.slave2.slave3 然后修改/etc/hosts文件添加 192.168.168.11 m
-
ol7.7安装部署4节点spark3.0.0分布式集群的详细教程
为学习spark,虚拟机中开4台虚拟机安装spark3.0.0 底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境 首先,去http://spark.apache.org/downloads.html下载对应安装包 解压 [hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local
-
详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群 在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了. 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装. 2:在centos7中安装docker,docker的版本为1.8.2 安装步骤如下: <1>安装制定版本的docker yum install -y docker-1.8.2-10.el7.centos <2>安装的时候可能会报错,需要删除这个依赖 r
-
Linux下ZooKeeper分布式集群安装教程
ZooKeeper 就是动物园管理员的意思,它是用来管理 Hadoop(大象).Hive(蜜蜂).pig(小猪)的管理员,Apache Hbase.Apache Solr.Dubbo 都用到了 ZooKeeper,其实就是一个集群管理工具,是集群的入口.ZooKeeper 是一个分布式的.开源的程序协调服务,是 Hadoop 项目下的一个子项目.ZooKeeper 主要应用场景包括集群管理(主从管理.负载均衡.高可用的管理).配置文件的集中管理.分布式锁.注册中心等.实际项目中,为了保证高可用,
-
Linux下Kafka分布式集群安装教程
Kafka(http://kafka.apache.org/) 是由 LinkedIn 使用 Scala 编写的一个分布式消息系统,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量.Spack.Elasticsearch 都支持与 Kafka 集成.下面看一下几种分布式开源消息队列系统的对比: Kafka 集群架构: 一般不建议直接使用 Kafka 自带的 Zookeeper 建立 zk 集群,这里我们使用独
-
浅析Hadoop完全分布式集群搭建问题
目录 一.Hadoop是什么 二.Hadoop组成 1.Hadoop1.x 2.Hadoop2.x 三.Hadoop集群搭建所需工具(链接如下,自行下载) 四.Hadoop集群配置前期准备 五.Hadoop运行环境搭建 六.Hadoop完全分布式集群环境正式搭建 1.编写集群分发脚本xsync 2.集群配置 3.SSH无密登录配置 4.群起集群 5.集群启动/停止方式总结 6.集群时间同步(必须root用户) 一.Hadoop是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 在前一篇文章中详细介绍了Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇,这里继续记录下Kubernetes集群插件等部署过程: 十一.Kubernetes集群插件 插件是Kubernetes集群的附件组件,丰富和完善了集群的功能,这里分别介绍的插件有cor
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 接着Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇继续往下部署: 八.部署master节点 master节点的kube-apiserver.kube-scheduler 和 kube-controller-manager 均以多实例模式运行:kube-sc
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇
Kubernetes(通常称为"K8S")是Google开源的容器集群管理系统.其设计目标是在主机集群之间提供一个能够自动化部署.可拓展.应用容器可运营的平台.Kubernetes通常结合docker容器工具工作,并且整合多个运行着docker容器的主机集群,Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术.Kubernetes是一个用于容器集群的自动化部署.扩容以及运维的开源平台. 本文系列: Kubernetes(K8S)容器集群管理环境完整部署详