Python爬虫抓取指定网页图片代码实例
想要爬取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容)
(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
(3)设置循环列表,重复抓取和保存内容
以下介绍了两种方法实现抓取指定网页中图片
(1)方法一:使用正则表达式过滤抓到的 html 内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html"
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意,代码中需要修改的就是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一块内容,如何设计正则表达式需要根据你想要抓取的内容设置。我的设计来源如下:
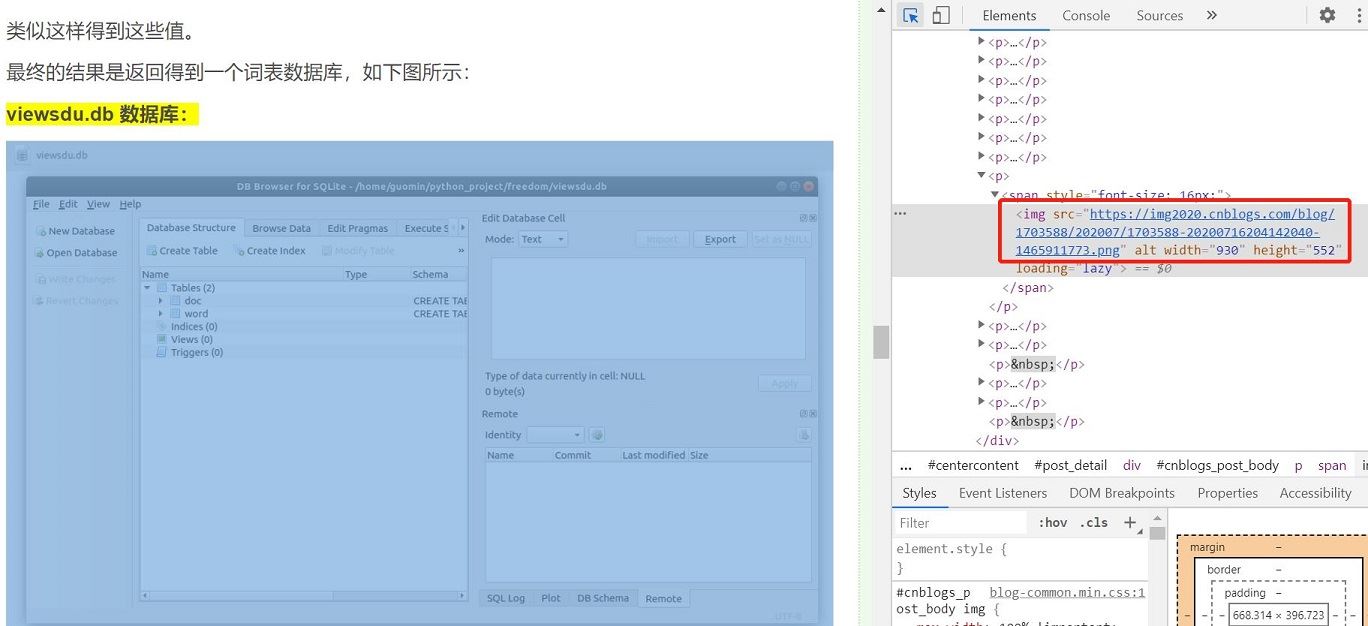
可以看到,因为这个网页上的图片都是 png 格式,所以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)也是可以的。
(2)方法二:使用 BeautifulSoup 库解析 html 网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, 'html.parser')
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是<img src="..." alt=".." />
imgList = soup.find_all('img')
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print('正在下载: %s ' % imgUrl.get('src'))
# 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png'
image_url = imgUrl.get('src')
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == '__main__':
# 指定要爬取的网站
url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html'
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有利弊,我觉得可以灵活结合使用这两种方法,比如先使用方法2中指定标签的方法缩小要寻找的内容范围,然后再使用正则表达式匹配想要的内容,这样做起来更加简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python抓取网页图片示例(python爬虫)
复制代码 代码如下: #-*- encoding: utf-8 -*-'''Created on 2014-4-24 @author: Leon Wong''' import urllib2import urllibimport reimport timeimport osimport uuid #获取二级页面urldef findUrl2(html): re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?<!photos).tuchong.co
-

Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
Python爬虫之网页图片抓取的方法
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url): ''' 打开网页 :param url: :return: ''' req = urllib.reques
-
Python之多线程爬虫抓取网页图片的示例代码
目标 嗯,我们知道搜索或浏览网站时会有很多精美.漂亮的图片. 我们下载的时候,得鼠标一个个下载,而且还翻页. 那么,有没有一种方法,可以使用非人工方式自动识别并下载图片.美美哒. 那么请使用python语言,构建一个抓取和下载网页图片的爬虫. 当然为了提高效率,我们同时采用多线程并行方式. 思路分析 Python有很多的第三方库,可以帮助我们实现各种各样的功能.问题在于,我们弄清楚我们需要什么: 1)http请求库,根据网站地址可以获取网页源代码.甚至可以下载图片写入磁盘. 2)解析网页源代码,
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python3简单爬虫抓取网页图片代码实例
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到大家,并希望大家批评指正. import urllib.request import re import os import urllib #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): page = urllib.request.urlope
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python爬虫抓取指定网页图片代码实例
想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容 (3)设置循环列表,重复抓取和保存内容 以下介绍了两种方法实现抓取指定网页中图片 (1)方法一:使用正则表达式过滤抓到的 html 内容字符串 # 第一个简单的爬取图片的程序 import urllib.request # python自带
-
Python爬虫爬取百度搜索内容代码实例
这篇文章主要介绍了Python爬虫爬取百度搜索内容代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 搜索引擎用的很频繁,现在利用Python爬虫提取百度搜索内容,同时再进一步提取内容分析就可以简便搜索过程.详细案例如下: 代码如下 # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制I
-
Python selenium抓取虎牙短视频代码实例
今天闲着没事,用selenium抓取视频保存到本地,只爬取了第一页,只要小于等于5分钟的视频... 为什么不用requests,没有为什么,就因为有些网站正则和xpath都提取不出来想要的东西,要么就是接口出来的数据加密,要么就因为真正的视频url规律难找! selenium几行代码轻轻松松就搞定! 安装selenium库,设置无界面模式 代码如下: from selenium import webdriver from selenium.webdriver.chrome.options imp
-
python爬虫 爬取超清壁纸代码实例
简介 壁纸的选择其实很大程度上能看出电脑主人的内心世界,有的人喜欢风景,有的人喜欢星空,有的人喜欢美女,有的人喜欢动物.然而,终究有一天你已经产生审美疲劳了,但你下定决定要换壁纸的时候,又发现网上的壁纸要么分辨率低,要么带有水印. 壁纸的选择其实很大程度上能看出电脑主人的内心世界,有的人喜欢风景,有的人喜欢星空,有的人喜欢美女,有的人喜欢动物.然而,终究有一天你已经产生审美疲劳了,但你下定决定要换壁纸的时候,又发现网上的壁纸要么分辨率低,要么带有水印. 演示图片 完整源代码 ''' 在学习过程中
-
Python爬虫——爬取豆瓣电影Top250代码实例
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中.基本上爬取结果还是挺好的.具体代码如下: #!/usr/bin/python #-*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf8') from bs4 import BeautifulSoup imp
-
python爬虫抓取时常见的小问题总结
目录 01 无法正常显示中文? 解决方法 02 加密问题 03 获取不到网页的全部代码? 04 点击下一页时网页网页不变 05 文本节点问题 06 如何快速找到提取数据? 07 获取标签中的数据 08 去除指定内容 09 转化为字符串类型 10 滥用遍历文档树 11 数据库保存问题 12 爬虫采集遇到的墙问题 逃避IP识别 变换请求内容 降低访问频率 慢速攻击判别 13 验证码问题 正向破解 逆向破解 前言: 现在写爬虫,入门已经不是一件门槛很高的事情了,网上教程一大把,但很多爬虫新手在爬取数据
-
分享PHP源码批量抓取远程网页图片并保存到本地的实现方法
做为一个仿站工作者,当遇到网站有版权时甚至加密的时候,WEBZIP也熄火,怎么扣取网页上的图片和背景图片呢.有时候,可能会想到用火狐,这款浏览器好像一个强大的BUG,文章有版权,屏蔽右键,火狐丝毫也不会被影响. 但是作为一个热爱php的开发者来说,更多的是喜欢自己动手.所以,我就写出了下面的一个源码,php远程抓取图片小程序.可以读取css文件并抓取css代码中的背景图片,下面这段代码也是针对抓取css中图片而编写的. <?php header("Content-Type: text/ht
-
python爬虫爬取指定内容的解决方法
目录 解决办法: 实列代码如下:(以我们学校为例) 爬取一些网站下指定的内容,一般来说可以用xpath来直接从网页上来获取,但是当我们获取的内容不唯一的时候我们无法选择,我们所需要的.所指定的内容. 解决办法: 可以使用for In 语句来判断如果我们所指定的内容在这段语句中我们就把这段内容爬取下来,反之就丢弃 实列代码如下:(以我们学校为例) import urllib.request from lxml import etree def creat_url(page): if(page==1