python filecmp.dircmp实现递归比对两个目录的方法
使用python filecmp模块的dircmp类可以很方便的比对两个目录,dircmp的用法已经有很多文章介绍,不再赘述。
可以help(filecmp.dircmp)查看帮助信息,其中提到的x.report()、x.report_partial_closure(),都只能打印两目录一级子目录的比较信息。而x.report_full_closure()可以递归打印所有子目录的比对信息,但是输出太多,大多数情况下我们可能只关心两目录的不同之处。
help(filecmp.dircmp) 摘选: | High level usage: | x = dircmp(dir1, dir2) | x.report() -> prints a report on the differences between dir1 and dir2 | or | x.report_partial_closure() -> prints report on differences between dir1 | and dir2, and reports on common immediate subdirectories. | x.report_full_closure() -> like report_partial_closure, | but fully recursive.
本文编写的脚本,重点关注并实现两个目标:
1)递归比对两个目录及其所有子目录。
2)仅输出两目录不同之处,包括文件名相同(common_files)但是文件不一致(diff_files),以及左、右目录中独有的文件或子目录。
py脚本compare_dir.py内容如下:
# -*- coding: utf-8 -*-
"""
@desc 使用filecmp.dircmp递归比对两个目录,输出比对结果以及统计信息。
@author longfeiwlf
@date 2020-5-20
"""
from filecmp import dircmp
import sys
# 定义全局变量:
number_different_files = 0 # 文件名相同但不一致的文件数
number_left_only = 0 # 左边目录独有的文件或目录数
number_right_only = 0 # 右边目录独有的文件或目录数
def print_diff(dcmp):
"""递归比对两目录,如果有不同之处,打印出来,同时累加统计计数。"""
global number_different_files
global number_left_only
global number_right_only
for name in dcmp.diff_files:
print("diff_file found: %s/%s" % (dcmp.left, name))
number_different_files += 1
for name_left in dcmp.left_only:
print("left_only found: %s/%s" % (dcmp.left, name_left))
number_left_only += 1
for name_right in dcmp.right_only:
print("right_only found: %s/%s" % (dcmp.right, name_right))
number_right_only += 1
for sub_dcmp in dcmp.subdirs.values():
print_diff(sub_dcmp) # 递归比较子目录
if __name__ == '__main__':
try:
mydcmp = dircmp(sys.argv[1], sys.argv[2])
except IndexError as ie:
print(ie)
print("使用方法:python compare_dir_cn.py 目录1 目录2")
else:
print("\n比对结果详情: ")
print_diff(mydcmp)
if (number_different_files == 0 and number_left_only == 0
and number_right_only == 0):
print("\n两个目录完全一致!")
else:
print("\n比对结果统计:")
print("Total Number of different files is: "
+ str(number_different_files))
print("Total Number of files or directories only in '"
+ sys.argv[1] + "' is: " + str(number_left_only))
print("Total Number of files or directories only in '"
+ sys.argv[2] + "' is: " + str(number_right_only))
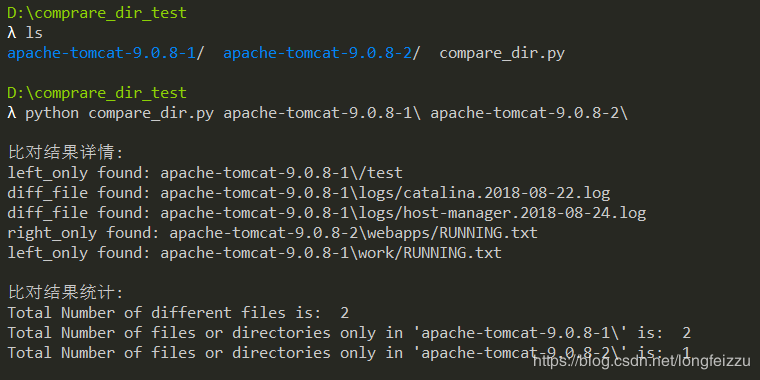
compare_dir.py脚本使用举例:
总结
到此这篇关于filecmp.dircmp实现递归比对两个目录的文章就介绍到这了,更多相关filecmp.dircmp实现递归比对两个目录内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python利用递归和walk()遍历目录文件的方法示例
前言 经常需要检查一个"目录或文件夹"内部有没有我们想要的文件或者文件夹,就需要我们循环迭代出所有文件和子文件夹,Python中遍历指定目录下所有的文件和文件夹,包含多级目录,有两种方法,一种是通过递归思想去遍历,另一种是os模块的walk()函数下面话不多说,就来一起看看详细的介绍: 列出目录结构 一.递归方法 #coding:utf-8 import os allfile=[] def getallfile(path): allfilelist=os.listdir(path) f
-
python递归删除指定目录及其所有内容的方法
实例如下: #! /usr/bin/python # -*- coding: utf-8 -*- import os def del_dir_tree(path): ''' 递归删除目录及其子目录, 子文件''' if os.path.isfile(path): try: os.remove(path) except Exception, e: #pass print e elif os.path.isdir(path): for item in os.listdir(path): itempa
-
Python通过递归获取目录下指定文件代码实例
这篇文章主要介绍了python通过递归获取目录下指定文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 获取一个目录下所有指定格式的文件是实际生产中常见需求. import os #递归获取一个目录下所有的指定格式的文件 def get_jsonfile(path,file_list): dir_list=os.listdir(path) for x in dir_list: new_x=os.path.join(path,x) if
-
python递归打印某个目录的内容(实例讲解)
以下函数列出某个目录下(包括子目录)所有文件,本随笔重点不在于递归函数的实现,这是一个很简单的递归,重点在于熟悉Python 库os以及os.path一些函数的功能和用法. 1. os.listdir(path): 列出path下所有内容(包括文件和目录,不包括.和..) 2. os.path.join(path1,path2,path3...): 拼接目录,例如将'home','test'拼接成'home/test/' 3. os.path.isdir(path): 判断path是否为目录 代
-
python filecmp.dircmp实现递归比对两个目录的方法
使用python filecmp模块的dircmp类可以很方便的比对两个目录,dircmp的用法已经有很多文章介绍,不再赘述. 可以help(filecmp.dircmp)查看帮助信息,其中提到的x.report().x.report_partial_closure(),都只能打印两目录一级子目录的比较信息.而x.report_full_closure()可以递归打印所有子目录的比对信息,但是输出太多,大多数情况下我们可能只关心两目录的不同之处. help(filecmp.dircmp) 摘选:
-
python遍历文件夹,指定遍历深度与忽略目录的方法
背景 需要在文件夹中搜索某一文件,找到后返回此文件所在目录.用最常规的os.listdir()方式实现了一版,但执行时报错:递归超过最大深度.于是自己添加了点功能,之所有写此函数是为了让它适应不同的项目,因为有项目要找的文件在第一层,有的在第二层. 函数 功能:在文件夹中查找某一文件,找到后返回True与文件所在目录路径. 参数:filepath, 要查找的目录 参数:filename, 要查找的文件 扩展1:find_depth, 查找时指定递归深度: 扩展2:ignore_path, 查找时
-
python中的函数递归和迭代原理解析
这篇文章主要介绍了python中的函数递归和迭代原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.递归 1.递归的介绍 什么是递归? 程序调用自身的编程技巧称为递归( recursion).递归做为一种算法在程序设计语言中广泛应用. 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大
-
python实现文法左递归的消除方法
前言 继词法分析后,又来到语法分析范畴.完成语法分析需要解决几个子问题,今天就完成文法左递归的消除. 没借鉴任何博客,完全自己造轮子. 开始之前 文法左递归消除程序的核心是对字符串的处理,输入的产生式作为字符串,对它的拆分.替换与合并操作贯穿始终,处理过程的逻辑和思路稍有错漏便会漏洞百出. 采用直接改写法,不理解左递归消除方法很难读懂代码. 要求 CFG文法判断 左递归的类型 消除直接左递归和间接左递归 界面 源码 import os import tkinter as tk import tk
-
python实现合并两个数组的方法
本文实例讲述了python实现合并两个数组的方法.分享给大家供大家参考.具体如下: python合并两个数组,将两个数组连接成一个数组,例如,数组 a=[1,2,3] ,数组 b=[4,5,6],连接后:[1,2,3,4,5,6] 方法1 a=[1,2,3] b=[4,5,6] a=a+b 方法2 a=[1,2,3] b=[4,5,6] a.extend(b) 希望本文所述对大家的Python程序设计有所帮助.
-
Python递归遍历列表及输出的实现方法
本文实例讲述了Python递归遍历列表及输出的实现方法.分享给大家供大家参考.具体实现方法如下: def dp(s): if isinstance(s,(int,str)): print(s) else: for item in s: dp(item) l=['jack',('tom',23),'rose',(14,55,67)] dp(l) 运行结果如下: jack tom 23 rose 14 55 67 希望本文所述对大家的Python程序设计有所帮助.
-
python使用append合并两个数组的方法
本文实例讲述了python使用append合并两个数组的方法.分享给大家供大家参考.具体如下: lista = [1,2,3] listb = [4,5,6] mergedlist =[] for elem in lista: mergedlist.append(elem) for elem in listb: mergedlist.append(elem) 希望本文所述对大家的Python程序设计有所帮助.
-
详解python中字典的循环遍历的两种方式
开发中经常会用到对于字典.列表等数据的循环遍历,但是python中对于字典的遍历对于很多初学者来讲非常陌生,今天就来讲一下python中字典的循环遍历的两种方式. 注意: python2和python3中,下面两种方法都是通用的. 1. 只对键的遍历 一个简单的for语句就能循环字典的所有键,就像处理序列一样: d = {'name1' : 'pythontab', 'name2' : '.', 'name3' : 'com'} for key in d: print (key, ' value
-
Java之递归求和的两种简单方法(推荐)
方法一: package com.smbea.demo; public class Student { private int sum = 0; /** * 递归求和 * @param num */ public void sum(int num) { this.sum += num--; if(0 < num){ sum(num); } else { System.out.println("sum = " + sum); } } } 方法二: package com.smbea
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10: