Tensorflow卷积实现原理+手写python代码实现卷积教程
从一个通道的图片进行卷积生成新的单通道图的过程很容易理解,对于多个通道卷积后生成多个通道的图理解起来有点抽象。本文以通俗易懂的方式讲述卷积,并辅以图片解释,能快速理解卷积的实现原理。最后手写python代码实现卷积过程,让Tensorflow卷积在我们面前不再是黑箱子!
注意:
本文只针对batch_size=1,padding='SAME',stride=[1,1,1,1]进行实验和解释,其他如果不是这个参数设置,原理也是一样。
1 Tensorflow卷积实现原理
先看一下卷积实现原理,对于in_c个通道的输入图,如果需要经过卷积后输出out_c个通道图,那么总共需要in_c * out_c个卷积核参与运算。参考下图:
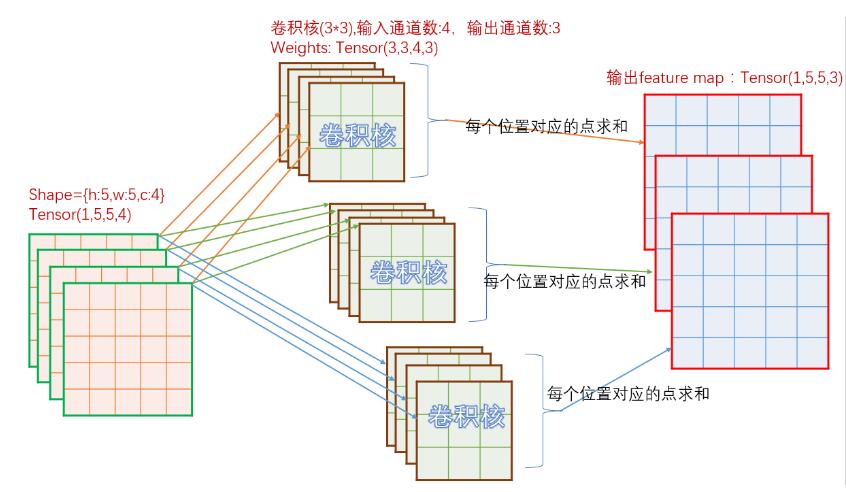
如上图,输入为[h:5,w:5,c:4],那么对应输出的每个通道,需要4个卷积核。上图中,输出为3个通道,所以总共需要3*4=12个卷积核。对于单个输出通道中的每个点,取值为对应的一组4个不同的卷积核经过卷积计算后的和。
接下来,我们以输入为2个通道宽高分别为5的输入、3*3的卷积核、1个通道宽高分别为5的输出,作为一个例子展开。
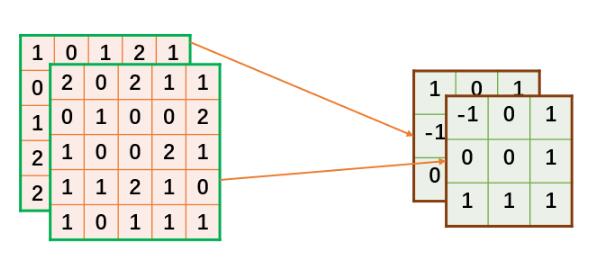
2个通道,5*5的输入定义如下:
#输入,shape=[c,h,w] input_data=[ [[1,0,1,2,1], [0,2,1,0,1], [1,1,0,2,0], [2,2,1,1,0], [2,0,1,2,0]], [[2,0,2,1,1], [0,1,0,0,2], [1,0,0,2,1], [1,1,2,1,0], [1,0,1,1,1]], ]
对于输出为1通道map,根据前面计算方法,需要2*1个卷积核。定义卷积核如下:
#卷积核,shape=[in_c,k,k]=[2,3,3] weights_data=[ [[ 1, 0, 1], [-1, 1, 0], [ 0,-1, 0]], [[-1, 0, 1], [ 0, 0, 1], [ 1, 1, 1]] ]
上面定义的数据,在接下来的计算对应关系将按下图所描述的方式进行。
由于Tensorflow定义的tensor的shape为[n,h,w,c],这里我们可以直接把n设为1,即batch size为1。还有一个问题,就是我们刚才定义的输入为[c,h,w],所以需要将[c,h,w]转为[h,w,c]。转换方式如下,注释已经解释很详细,这里不再解释。
def get_shape(tensor): [s1,s2,s3]= tensor.get_shape() s1=int(s1) s2=int(s2) s3=int(s3) return s1,s2,s3 def chw2hwc(chw_tensor): [c,h,w]=get_shape(chw_tensor) cols=[] for i in range(c): #每个通道里面的二维数组转为[w*h,1]即1列 line = tf.reshape(chw_tensor[i],[h*w,1]) cols.append(line) #横向连接,即将所有竖直数组横向排列连接 input = tf.concat(cols,1)#[w*h,c] #[w*h,c]-->[h,w,c] input = tf.reshape(input,[h,w,c]) return input
同理,Tensorflow使用卷积核的时候,使用的格式是[k,k,in_c,out_c]。而我们在定义卷积核的时候,是按[in_c,k,k]的方式定义的,这里需要将[in_c,k,k]转为[k,k,in_c],由于为了简化工作量,我们规定输出为1个通道,即out_c=1。所以这里我们可以直接简单地对weights_data调用chw2hwc,再在第3维度扩充一下即可。
接下来,贴出完整的代码:
import tensorflow as tf import numpy as np input_data=[ [[1,0,1,2,1], [0,2,1,0,1], [1,1,0,2,0], [2,2,1,1,0], [2,0,1,2,0]], [[2,0,2,1,1], [0,1,0,0,2], [1,0,0,2,1], [1,1,2,1,0], [1,0,1,1,1]], ] weights_data=[ [[ 1, 0, 1], [-1, 1, 0], [ 0,-1, 0]], [[-1, 0, 1], [ 0, 0, 1], [ 1, 1, 1]] ] def get_shape(tensor): [s1,s2,s3]= tensor.get_shape() s1=int(s1) s2=int(s2) s3=int(s3) return s1,s2,s3 def chw2hwc(chw_tensor): [c,h,w]=get_shape(chw_tensor) cols=[] for i in range(c): #每个通道里面的二维数组转为[w*h,1]即1列 line = tf.reshape(chw_tensor[i],[h*w,1]) cols.append(line) #横向连接,即将所有竖直数组横向排列连接 input = tf.concat(cols,1)#[w*h,c] #[w*h,c]-->[h,w,c] input = tf.reshape(input,[h,w,c]) return input def hwc2chw(hwc_tensor): [h,w,c]=get_shape(hwc_tensor) cs=[] for i in range(c): #[h,w]-->[1,h,w] channel=tf.expand_dims(hwc_tensor[:,:,i],0) cs.append(channel) #[1,h,w]...[1,h,w]---->[c,h,w] input = tf.concat(cs,0)#[c,h,w] return input def tf_conv2d(input,weights): conv = tf.nn.conv2d(input, weights, strides=[1, 1, 1, 1], padding='SAME') return conv def main(): const_input = tf.constant(input_data , tf.float32) const_weights = tf.constant(weights_data , tf.float32 ) input = tf.Variable(const_input,name="input") #[2,5,5]------>[5,5,2] input=chw2hwc(input) #[5,5,2]------>[1,5,5,2] input=tf.expand_dims(input,0) weights = tf.Variable(const_weights,name="weights") #[2,3,3]-->[3,3,2] weights=chw2hwc(weights) #[3,3,2]-->[3,3,2,1] weights=tf.expand_dims(weights,3) #[b,h,w,c] conv=tf_conv2d(input,weights) rs=hwc2chw(conv[0]) init=tf.global_variables_initializer() sess=tf.Session() sess.run(init) conv_val = sess.run(rs) print(conv_val[0]) if __name__=='__main__': main()
上面代码有几个地方需要提一下,
由于输出通道为1,因此可以对卷积核数据转换的时候直接调用chw2hwc,如果输入通道不为1,则不能这样完成转换。
输入完成chw转hwc后,记得在第0维扩充维数,因为卷积要求输入为[n,h,w,c]
为了方便我们查看结果,记得将hwc的shape转为chw
执行上面代码,运行结果如下:
[[ 2. 0. 2. 4. 0.] [ 1. 4. 4. 3. 5.] [ 4. 3. 5. 9. -1.] [ 3. 4. 6. 2. 1.] [ 5. 3. 5. 1. -2.]]
这个计算结果是怎么计算出来的?为了让大家更清晰的学习其中细节,我特地制作了一个GIF图,看完这个图后,如果你还看不懂卷积的计算过程,你可以来打我。。。。

2 手写Python代码实现卷积
自己实现卷积时,就无须将定义的数据[c,h,w]转为[h,w,c]了。
import numpy as np input_data=[ [[1,0,1,2,1], [0,2,1,0,1], [1,1,0,2,0], [2,2,1,1,0], [2,0,1,2,0]], [[2,0,2,1,1], [0,1,0,0,2], [1,0,0,2,1], [1,1,2,1,0], [1,0,1,1,1]] ] weights_data=[ [[ 1, 0, 1], [-1, 1, 0], [ 0,-1, 0]], [[-1, 0, 1], [ 0, 0, 1], [ 1, 1, 1]] ] #fm:[h,w] #kernel:[k,k] #return rs:[h,w] def compute_conv(fm,kernel): [h,w]=fm.shape [k,_]=kernel.shape r=int(k/2) #定义边界填充0后的map padding_fm=np.zeros([h+2,w+2],np.float32) #保存计算结果 rs=np.zeros([h,w],np.float32) #将输入在指定该区域赋值,即除了4个边界后,剩下的区域 padding_fm[1:h+1,1:w+1]=fm #对每个点为中心的区域遍历 for i in range(1,h+1): for j in range(1,w+1): #取出当前点为中心的k*k区域 roi=padding_fm[i-r:i+r+1,j-r:j+r+1] #计算当前点的卷积,对k*k个点点乘后求和 rs[i-1][j-1]=np.sum(roi*kernel) return rs def my_conv2d(input,weights): [c,h,w]=input.shape [_,k,_]=weights.shape outputs=np.zeros([h,w],np.float32) #对每个feature map遍历,从而对每个feature map进行卷积 for i in range(c): #feature map==>[h,w] f_map=input[i] #kernel ==>[k,k] w=weights[i] rs =compute_conv(f_map,w) outputs=outputs+rs return outputs def main(): #shape=[c,h,w] input = np.asarray(input_data,np.float32) #shape=[in_c,k,k] weights = np.asarray(weights_data,np.float32) rs=my_conv2d(input,weights) print(rs) if __name__=='__main__': main()
代码无须太多解释,直接看注释。然后跑出来的结果如下:
[[ 2. 0. 2. 4. 0.] [ 1. 4. 4. 3. 5.] [ 4. 3. 5. 9. -1.] [ 3. 4. 6. 2. 1.] [ 5. 3. 5. 1. -2.]]
对比发现,跟Tensorflow的卷积结果是一样的。
3 小结
本文中,我们学习了Tensorflow的卷积实现原理,通过也通过python代码实现了输出通道为1的卷积,其实输出通道数不影响我们学习卷积原理。后面如果有机会的话,我们去实现一个更加健全,完整的卷积。
以上这篇Tensorflow卷积实现原理+手写python代码实现卷积教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用keras和tensorflow保存为可部署的pb格式
Keras保存为可部署的pb格式 加载已训练好的.h5格式的keras模型 传入如下定义好的export_savedmodel()方法内即可成功保存 import keras import os import tensorflow as tf from tensorflow.python.util import compat from keras import backend as K def export_savedmodel(model): ''' 传入keras model会自动保存为pb
-
Tensorflow中的图(tf.Graph)和会话(tf.Session)的实现
Tensorflow编程系统 Tensorflow工具或者说深度学习本身就是一个连贯紧密的系统.一般的系统是一个自治独立的.能实现复杂功能的整体.系统的主要任务是对输入进行处理,以得到想要的输出结果.我们之前见过的很多系统都是线性的,就像汽车生产工厂的流水线一样,输入->系统处理->输出.系统内部由很多单一的基本部件构成,这些单一部件具有特定的功能,且需要稳定的特性:系统设计者通过特殊的连接方式,让这些简单部件进行连接,以使它们之间可以进行数据交流和信息互换,来达到相互配合而完成具体工作的目的
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
使用tensorflow实现VGG网络,训练mnist数据集方式
VGG作为流行的几个模型之一,训练图形数据效果不错,在mnist数据集是常用的入门集数据,VGG层数非常多,如果严格按照规范来实现,并用来训练mnist数据集,会出现各种问题,如,经过16层卷积后,28*28*1的图片几乎无法进行. 先介绍下VGG ILSVRC 2014的第二名是Karen Simonyan和 Andrew Zisserman实现的卷积神经网络,现在称其为VGGNet.它主要的贡献是展示出网络的深度是算法优良性能的关键部分. 他们最好的网络包含了16个卷积/全连接层.网络的结构
-
Tensorflow卷积实现原理+手写python代码实现卷积教程
从一个通道的图片进行卷积生成新的单通道图的过程很容易理解,对于多个通道卷积后生成多个通道的图理解起来有点抽象.本文以通俗易懂的方式讲述卷积,并辅以图片解释,能快速理解卷积的实现原理.最后手写python代码实现卷积过程,让Tensorflow卷积在我们面前不再是黑箱子! 注意: 本文只针对batch_size=1,padding='SAME',stride=[1,1,1,1]进行实验和解释,其他如果不是这个参数设置,原理也是一样. 1 Tensorflow卷积实现原理 先看一下卷积实现原理,对于
-

纯numpy卷积神经网络实现手写数字识别的实践
前面讲解了使用纯numpy实现数值微分和误差反向传播法的手写数字识别,这两种网络都是使用全连接层的结构.全连接层存在什么问题呢?那就是数据的形状被“忽视”了.比如,输入数据是图像时,图像通常是高.长.通道方向上的3维形状.但是,向全连接层输入时,需要将3维数据拉平为1维数据.实际上,前面提到的使用了MNIST数据集的例子中,输入图像就是1通道.高28像素.长28像素的(1, 28, 28)形状,但却被排成1列,以784个数据的形式输入到最开始的Affine层. 图像是3维形状,这个形状中应该含有
-
浅谈时钟的生成(js手写简洁代码)
在生成时钟的过程中自己想到布置表盘的写法由这么几种: 当然利用那种模式都可以实现,所以我们要用一个最好理解,代码有相对简便的方法实现 1.利用三角函数 用js在三角函数布置表盘的过程中有遇见到这种情况:是在表盘的刻度处,利用三角函数计算具体的值时不能得到整数,需要向上或者向下取整,这样无形中就会存在些许偏差,而且这样的偏差难利用样式来调整到位,即使最终效果都可以实现,但是细微处的缝隙和角度的偏差都会影响整体的视觉体验,作为一名程序开发人员,这样的视觉体验很难让别人认可,放弃. 2.利用遮罩层 j
-
Python代码调试技巧教程详解
目录 关于代码调试的技巧,我之前写过很多的文章,加起来也有 将近 10 篇了,关注比较早的同学,也应该都有看过. 还没看过的同学,欢迎前往查阅:调试技巧 其中有一篇是关于 pdb 的调试技巧的: 里面介绍了两种 pdb 的调试入口,也是大部分所熟知的. 这里再带大家回顾一下 第一种:指定 -m pdb 来开启 $ python -m pdb pdb_demo.py 第二种:使用 pdb.set_trace() 在代码中设置断点 import pdb pdb.set_trace() 但其实,pdb
-
python tensorflow基于cnn实现手写数字识别
一份基于cnn的手写数字自识别的代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 加载数据集 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 以交互式方式启动session # 如果不使用交互式session,则在启动s
-
一篇文章带你了解谷歌这些大厂是怎么写 python 代码的
目录 谷歌内部的 python 代码规范 1.导入模块和包,不导入单独的类.函数或者变量. 2.从根目录导入,不假定任意的 sys.path,也不使用相对导入. 3.谨慎使用异常 4.不要使用可变类型作为函数默认值,如果修改了这个变量,默认值也会跟着发生变化. 5.注意条件表达式的隐式布尔值 6.谨慎使用装饰器 7.建议使用类型声明,类型声明的好处非常明显: 总结 谷歌内部的 python 代码规范 熟悉 python 一般都会努力遵循 pep8 规范,也会有一些公司制定内部的代码规范.大公司制
-
如何更优雅地写python代码
前言 Python 这门语言最大的优点之一就是语法简洁,好的代码就像伪代码一样,干净.整洁.一目了然.但有时候我们写代码,特别是 Python 初学者,往往还是按照其它语言的思维习惯来写,那样的写法不仅运行速度慢,代码读起来也费尽,给人一种拖泥带水的感觉,过段时间连自己也读不懂. <计算机程序的构造和解释>的作者哈尔·阿伯尔森曾这样说:"Programs must be written for people to read, and only incidentally for mac
-
Python(TensorFlow框架)实现手写数字识别系统的方法
手写数字识别算法的设计与实现 本文使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统.这是本人的本科毕业论文课题,当然,这个也是机器学习的基本问题.本博文不会以论文的形式展现,而是以编程实战完成机器学习项目的角度去描述. 项目要求:本文主要解决的问题是手写数字识别,最终要完成一个识别系统. 设计识别率高的算法,实现快速识别的系统. 1 LeNet-5模型的介绍 本文实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示
-
tensorflow识别自己手写数字
tensorflow作为google开源的项目,现在赶超了caffe,好像成为最受欢迎的深度学习框架.确实在编写的时候更能感受到代码的真实存在,这点和caffe不同,caffe通过编写配置文件进行网络的生成.环境tensorflow是0.10的版本,注意其他版本有的语句会有错误,这是tensorflow版本之间的兼容问题. 还需要安装PIL:pip install Pillow 图片的格式: – 图像标准化,可安装在20×20像素的框内,同时保留其长宽比. – 图片都集中在一个28×28的图像中
-
如何将tensorflow训练好的模型移植到Android (MNIST手写数字识别)
[尊重原创,转载请注明出处]https://blog.csdn.net/guyuealian/article/details/79672257 项目Github下载地址:https://github.com/PanJinquan/Mnist-tensorFlow-AndroidDemo 本博客将以最简单的方式,利用TensorFlow实现了MNIST手写数字识别,并将Python TensoFlow训练好的模型移植到Android手机上运行.网上也有很多移植教程,大部分是在Ubuntu(Linu