彻底搞定堆排序:二叉堆
目录
- 二叉堆
- 插入
- 删除
- 构建
- 二叉堆代码实现
- 总结
二叉堆
什么是二叉堆
二叉堆本质上是一种完全二叉树,它分为两个类型
- 最大堆:最大堆的任何一个父节点的值,都大于等于它的左、右孩子节点的值(堆顶就是整个堆的最大元素)
- 最小堆:最小堆的任何一个父节点的值,都小于等于它的左、右孩子节点的值(堆顶就是整个堆的最小元素)
二叉堆的根节点叫做堆顶
二叉堆的基本操作
- 插入节点
- 删除节点
- 构建二叉堆
这几种操作都基于堆的自我调整,所谓堆自我调整,就是把一个不符合堆的完全二叉树,调整成一个堆,下面以最小堆为例。
插入
插入节点0的过程
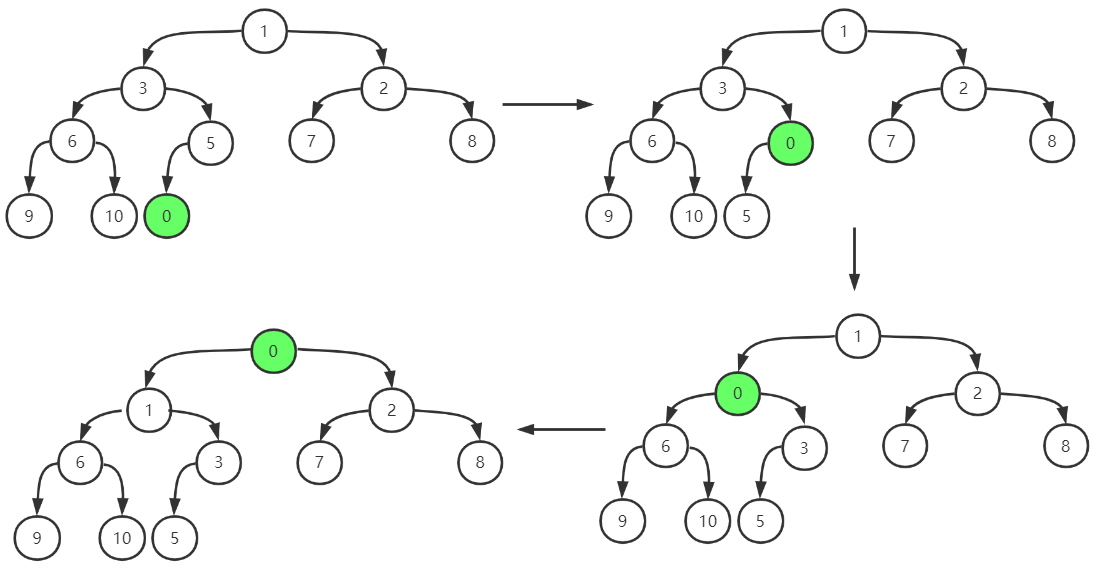
删除
删除节点的过程和插入的过程刚好相反,所删除的是处于堆顶的节点。例如删除1
- 为了维持完全二叉树的结构,把堆的最后一个元素临时补充到堆顶
- 删除原来10的位置
- 对堆顶的节点10执行下沉操作

构建
构建二叉堆,也就是把一个无序的完全二叉树调整为二叉堆,本质就是让所有的非叶子节点一次下沉


二叉堆代码实现
二查堆虽然是一颗完全二叉树,但它的存储方式并不是链式的,而是顺序存储,换句话说,二叉堆的所有节点都存储在数组中

当父节点为parent时,左孩子为2 * parent + 1;右孩子为2 * parent + 2
/**
* @author :zsy
* @date :Created 2021/5/17 9:41
* @description:二叉堆
*/
public class HeapTest {
public static void main(String[] args) {
int[] arr = {1, 3, 2, 6, 5, 7, 8, 9, 10, 0};
Heap heap = new Heap(arr);
heap.upAdjust(arr);
System.out.println(Arrays.toString(arr));
arr = new int[]{7, 1, 3, 10, 5, 2, 8, 9, 6};
heap = new Heap(arr);
heap.buildHead();
System.out.println(Arrays.toString(arr));
}
}
class Heap {
private int[] arr;
public Heap(int[] arr) {
this.arr = arr;
}
public void buildHead() {
//从最后一个非叶子节点开始,依次下沉
for (int i = (arr.length - 2) / 2; i >= 0; i--) {
downAdjust(arr, i, arr.length);
}
}
private void downAdjust(int[] arr, int parentIndex, int length) {
int temp = arr[parentIndex];
int childrenIndex = parentIndex * 2 + 1;
while (childrenIndex < length) {
//如果有右孩子,并且右孩子小于左孩子,那么定位到右孩子
if (childrenIndex + 1 < length && arr[childrenIndex + 1] < arr[childrenIndex]) {
childrenIndex++;
}
//如果父节点小于较小孩子节点的值,直接跳出
if (temp <= arr[childrenIndex]) break;
//无需交换,单向赋值
arr[parentIndex] = arr[childrenIndex];
parentIndex = childrenIndex;
childrenIndex = 2 * childrenIndex + 1;
}
arr[parentIndex] = temp;
}
public void upAdjust(int[] arr) {
int childrenIndex = arr.length - 1;
int parentIndex = (childrenIndex - 1) / 2;
int temp = arr[childrenIndex];
while (childrenIndex > 0 && temp < arr[parentIndex]) {
//单向赋值
arr[childrenIndex] = arr[parentIndex];
childrenIndex = parentIndex;
parentIndex = (parentIndex - 1) / 2;
}
arr[childrenIndex] = temp;
}
}
结果:
[0, 1, 2, 6, 3, 7, 8, 9, 10, 5]
[1, 5, 2, 6, 7, 3, 8, 9, 10]
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

理解二叉堆数据结构及Swift的堆排序算法实现示例
二叉堆的性质 1.二叉堆是一颗完全二叉树,最后一层的叶子从左到右排列,其它的每一层都是满的 2.最小堆父结点小于等于其每一个子结点的键值,最大堆则相反 3.每个结点的左子树或者右子树都是一个二叉堆 下面是一个最小堆: 堆的存储 通常堆是通过一维数组来实现的.在起始数组为 0 的情形中: 1.父节点i的左子节点在位置 (2*i+1); 2.父节点i的右子节点在位置 (2*i+2); 3.子节点i的父节点在位置 floor((i-1)/2); 维持堆的性质 我们以最大堆来介绍(后续会分别给出最大堆和
-
Java实现堆排序和图解
目录 堆排序基本介绍 堆排序基本思想 堆排序图解 步骤一 步骤二 代码实现 总结 堆排序基本介绍 1.堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序. 2.堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系. 3.每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆 4.大顶堆举例说明 大顶堆特点:arr[i]
-
python下实现二叉堆以及堆排序的示例
堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆, 正如其名, 大头堆的第一个元素是最大的, 每个有子结点的父结点, 其数据值都比其子结点的值要大.小头堆则相反. 我大概讲解下建一个树形堆的算法过程: 找到N/2 位置的数组数据, 从这个位置开始, 找到该节点的左子结点的索引, 先比较这个结点的下的子结点, 找到最大的那个, 将最大的子结点的索引赋值给左子结点, 然后将最大的子结点
-
java编程实现优先队列的二叉堆代码分享
这里主要介绍的是优先队列的二叉堆Java实现,代码如下: package practice; import edu.princeton.cs.algs4.StdRandom; public class TestMain { public static void main(String[] args) { int[] a = new int[20]; for (int i = 0; i < a.length; i++) { int temp = (int)(StdRandom.random()*1
-
Java实现堆排序(大根堆)的示例代码
堆排序是一种树形选择排序方法,它的特点是:在排序的过程中,将array[0,...,n-1]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(最小)的元素. 1. 若array[0,...,n-1]表示一颗完全二叉树的顺序存储模式,则双亲节点指针和孩子结点指针之间的内在关系如下: 任意一节点指针 i:父节点:i==0 ? null : (i-1)/2 左孩子:2*i + 1 右孩子:2*i + 2 2. 堆的定义:n个关键字序列a
-
彻底搞定堆排序:二叉堆
目录 二叉堆 插入 删除 构建 二叉堆代码实现 总结 二叉堆 什么是二叉堆 二叉堆本质上是一种完全二叉树,它分为两个类型 最大堆:最大堆的任何一个父节点的值,都大于等于它的左.右孩子节点的值(堆顶就是整个堆的最大元素) 最小堆:最小堆的任何一个父节点的值,都小于等于它的左.右孩子节点的值(堆顶就是整个堆的最小元素) 二叉堆的根节点叫做堆顶 二叉堆的基本操作 插入节点 删除节点 构建二叉堆 这几种操作都基于堆的自我调整,所谓堆自我调整,就是把一个不符合堆的完全二叉树,调整成一个堆,下面以最小堆为例
-
Java语言实现二叉堆的打印代码分享
二叉堆是一种特殊的堆,二叉堆是完全二元树(二叉树)或者是近似完全二元树(二叉树).二叉堆有两种:最大堆和最小堆.最大堆:父结点的键值总是大于或等于任何一个子节点的键值:最小堆:父结点的键值总是小于或等于任何一个子节点的键值. 打印二叉堆:利用层级关系 我这里是先将堆排序,然后在sort里执行了打印堆的方法printAsTree() public class MaxHeap<T extends Comparable<? super T>> { private T[] data; pr
-
PHP利用二叉堆实现TopK-算法的方法详解
前言 在以往工作或者面试的时候常会碰到一个问题,如何实现海量TopN,就是在一个非常大的结果集里面快速找到最大的前10或前100个数,同时要保证内存和速度的效率,我们可能第一个想法就是利用排序,然后截取前10或前100,而排序对于量不是特别大的时候没有任何问题,但只要量特别大是根本不可能完成这个任务的,比如在一个数组或者文本文件里有几亿个数,这样是根本无法全部读入内存的,所以利用排序解决这个问题并不是最好的,所以我们这里就用php去实现一个小顶堆来解决这个问题. 二叉堆 二叉堆是一种特殊的堆,二
-
Python实现二叉堆
优先队列的二叉堆实现 在前面的章节里我们学习了"先进先出"(FIFO)的数据结构:队列(Queue).队列有一种变体叫做"优先队列"(Priority Queue).优先队列的出队(Dequeue)操作和队列一样,都是从队首出队.但在优先队列的内部,元素的次序却是由"优先级"来决定:高优先级的元素排在队首,而低优先级的元素则排在后面.这样,优先队列的入队(Enqueue)操作就比较复杂,需要将元素根据优先级尽量排到队列前面.我们将会发现,对于下一
-
C语言每日练习之二叉堆
目录 一.堆的概念 1.概述 2.定义 3.性质 4.作用 二.堆的存储结构 1.根结点编号 2.孩子结点编号 3.父结点编号 4.数据域 5.堆的数据结构 三.堆的常用接口 1.元素比较 2.交换元素 3.空判定 4.满判定 5.上浮操作 6.下沉操作 四.堆的创建 1.算法描述 2.动画演示 3.源码详解 五.堆元素的插入 1.算法描述 2.动画演示 3.源码详解 五.堆元素的删除 1.算法描述 2.动画演示 3.源码详解 总结 一.堆的概念 1.概述 堆是计算机科学中一类特殊的数据结构的统
-
Java实现二叉堆、大顶堆和小顶堆
目录 什么是二叉堆 什么是大顶堆.小顶堆 建堆 程序实现 建立大顶堆 逻辑过程 程序实现 建立小顶堆 逻辑过程 程序实现 从堆顶取数据并重构大小顶堆 什么是二叉堆 二叉堆就是完全二叉树,或者是靠近完全二叉树结构的二叉树.在二叉树建树时采取前序建树就是建立的完全二叉树.也就是二叉堆.所以二叉堆的建堆过程理论上讲和前序建树一样. 什么是大顶堆.小顶堆 二叉堆本质上是一棵近完全的二叉树,那么大顶堆和小顶堆必然也是满足这个结构要求的.在此之上,大顶堆要求对于一个节点来说,它的左右节点都比它小:小顶堆要求
-
Java 数据结构与算法系列精讲之二叉堆
目录 概述 优先队列 二叉堆 二叉堆实现 获取索引 添加元素 siftUp 完整代码 概述 从今天开始, 小白我将带大家开启 Java 数据结构 & 算法的新篇章. 优先队列 优先队列 (Priority Queue) 和队列一样, 是一种先进先出的数据结构. 优先队列中的每个元素有各自的优先级, 优先级最高的元素最先得到服务. 如图: 二叉堆 二叉堆 (Binary Heap) 是一种特殊的堆, 二叉堆具有堆的性质和二叉树的性质. 二叉堆中的任意一节点的值总是大于等于其孩子节点值. 如图: 二