详解C/C++内存区域划分(简而易懂)
C语言在内存中一共分为如下几个区域,分别是:
1. 内存栈区: 存放局部变量名;
2. 内存堆区: 存放new或者malloc出来的对象;
3. 常数区: 存放局部变量或者全局变量的值;
4. 静态区: 用于存放全局变量或者静态变量;
5. 代码区:二进制代码。
知道如上一些内存分配机制,有助于我们理解指针的概念。
C/C++不提供垃圾回收机制,因此需要对堆中的数据进行及时销毁,防止内存泄漏,使用free和delete销毁new和malloc申请的堆内存,而栈内存是动态释放。
C/C++内存区域划分详解
C/C++内存分布
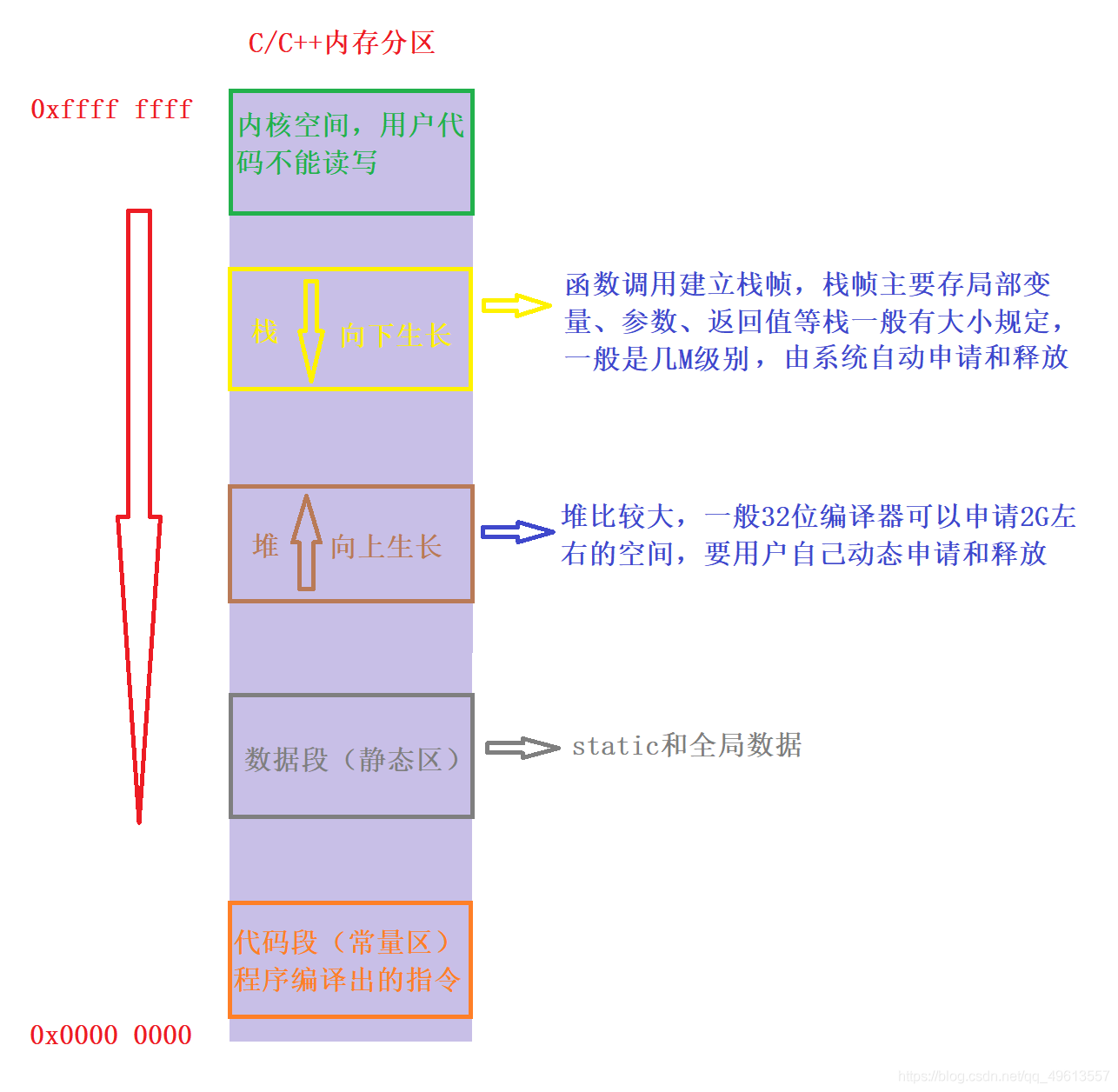
C/C++中,内存主要分为、堆、栈、全局/静态存储区和常量存储区。
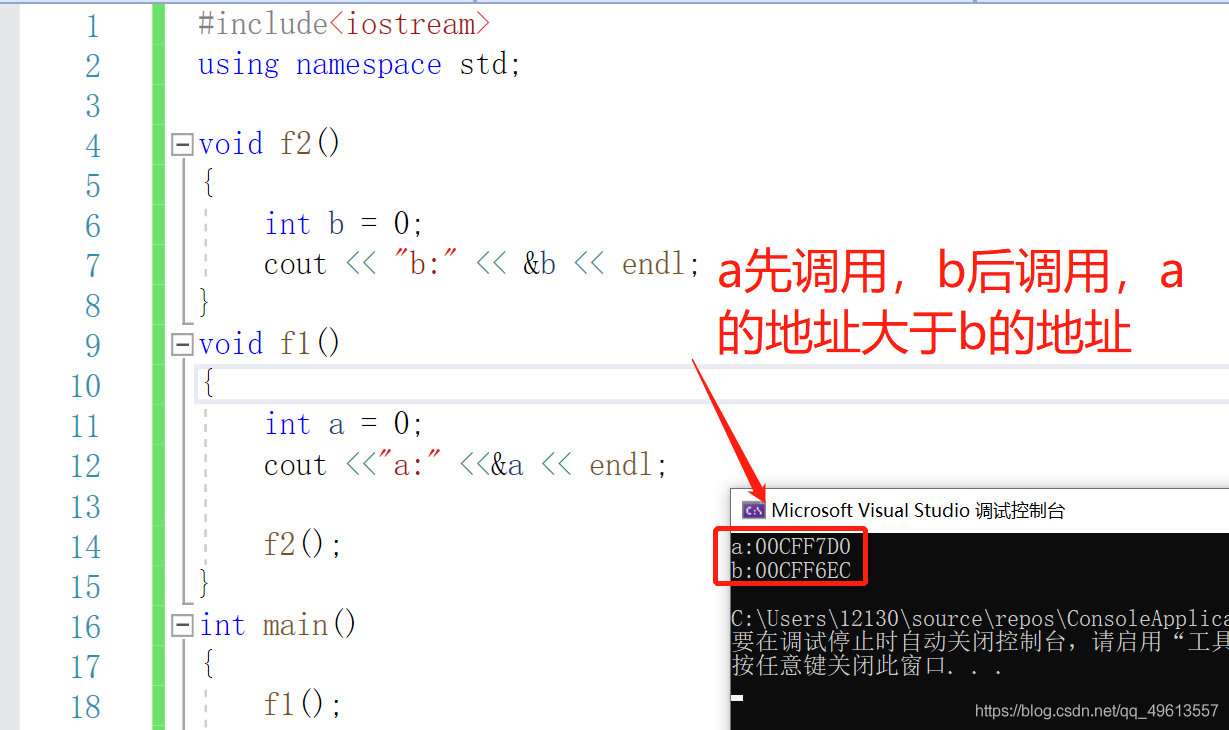
栈:栈又叫堆栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等,是向下增长的。所谓向下生长的就是,先调用的栈帧的地址比后调用的地址大,栈一般大小有几个M左右。
#include<iostream>
using namespace std;
void f2()
{
int b = 0;
cout << "b:" << &b << endl;
}
void f1()
{
int a = 0;
cout <<"a:" <<&a << endl;
f2();
}
int main()
{
f1();
return 0;
}
堆:就是那些由new/malloc分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new/malloc就要对应一个delete/free,由程序员主动释放。堆是可以上增长的.意思是先建立的堆的地址小于后建立的堆的地址。
#include<iostream>
using namespace std;
int main()
{
void* p1 = malloc(10);
void* p2 = malloc(10);
cout << p1 << endl;
cout << p2 << endl;
return 0;
}

数据段:存储全局数据和静态数据。
代码段:可执行的代码/只读常量
知道了内存分布,下面就来做题吧,考验知识的时候到了,看看会做几题吧

是不是前几题还得心应手,后面就有点懵了


栈和堆的区别:
栈:由编译器自动分配并且释放,一般存储函数的参数局部变量等
堆:由程序员分配释放,若程不释放则系统释放
1、申请内存方式
栈:由系统自动分配,如变量的声明的同时会开辟空间,(int a; 开辟4个字节的空间)(静态指定)
堆:由程序员申请,需要制定大小(动态分配)
2、系统响应的不同
栈:只要剩余空间大于申请内存,系统就会提供,否则会栈溢出
堆:便历空闲地址链表,找到符合要求的,就删除该地址分配给程序,内存的首地址记录分配的大小,(方便delete)多余的内存回收
3、空间大小不同
栈:连续的,编译时就确定的常数
堆:不连续,他的上限决定于系统中有效的虚拟内存
4、执行效率的不同
栈:由系统分配,速度快
堆:程序员分配,速度慢,容易产生内存碎片,不过用起来方便
到此这篇关于C/C++内存区域划分详解的文章就介绍到这了,更多相关C++内存划分内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++内存查找实例
本文实例讲述了C++内存查找的方法,分享给大家供大家参考.具体如下: windows程序设计中的内存查找功能,主程序代码如下: 复制代码 代码如下: // MemRepair.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <Windows.h> BOOL FindFirst(DWORD dwValue); BOOL FindNext(DWORD dwValue); HANDLE g_hProce
-
浅谈C++内存分配及变长数组的动态分配
第一部分 C++内存分配 一.关于内存 1.内存分配方式 内存分配方式有三种: (1)从静态存储区域分配.内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在 例如全局变量,static变量. (2)在栈上创建.在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存 储单元自动被释放.栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限. (3) 从堆上分配,亦称动态内存分配.程序在运行的时候用malloc或new申请任意多少的内存,程序员
-

C++动态分配和撤销内存以及结构体类型作为函数参数
C++动态分配内存(new)和撤销内存(delete) 在软件开发过程中,常常需要动态地分配和撤销内存空间,例如对动态链表中结点的插入与删除.在C语言中是利用库函数malloc和free来分配和撤销内存空间的.C++提供了较简便而功能较强的运算符new和delete来取代malloc和free函数. 注意: new和delete是运算符,不是函数,因此执行效率高. 虽然为了与C语言兼容,C++仍保留malloc和free函数,但建议用户不用malloc和free函数,而用new和delete运算
-
C++程序检测内存泄漏的方法分享
一.前言 在Linux平台上有valgrind可以非常方便的帮助我们定位内存泄漏,因为Linux在开发领域的使用场景大多是跑服务器,再加上它的开源属性,相对而言,处理问题容易形成"统一"的标准.而在Windows平台,服务器和客户端开发人员惯用的调试方法有很大不同.下面结合我的实际经验,整理下常见定位内存泄漏的方法. 注意:我们的分析前提是Release版本,因为在Debug环境下,通过VLD这个库或者CRT库本身的内存泄漏检测函数能够分析出内存泄漏,相对而言比较简单.而服务器有很多问
-
浅谈C++对象的内存分布和虚函数表
c++中一个类中无非有四种成员:静态数据成员和非静态数据成员,静态函数和非静态函数. 1.非静态数据成员被放在每一个对象体内作为对象专有的数据成员. 2.静态数据成员被提取出来放在程序的静态数据区内,为该类所有对象共享,因此只存在一份. 3.静态和非静态成员函数最终都被提取出来放在程序的代码段中并为该类所有对象共享,因此每一个成员函数也只能存在一份代码实体.在c++中类的成员函数都是保存在静态存储区中的 ,那静态函数也是保存在静态存储区中的,他们都是在类中保存同一个惫份. 因此,构成对象本身的只
-
C/C++动态分配与释放内存的区别详细解析
1. malloc()函数1.1 malloc的全称是memory allocation,中文叫动态内存分配.原型:extern void *malloc(unsigned int num_bytes); 说明:分配长度为num_bytes字节的内存块.如果分配成功则返回指向被分配内存的指针,分配失败返回空指针NULL.当内存不再使用时,应使用free()函数将内存块释放. 1.2 void *malloc(int size); 说明:malloc 向系统申请分配指定size个字节的内存空间,返
-
深入理解c/c++ 内存对齐
内存对齐,memory alignment.为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐.原因在于,为了访问未对齐的内存,处理器需要作两次内存访问:然而,对齐的内存访问仅需要一次访问.内存对齐一般讲就是cpu access memory的效率(提高运行速度)和准确性(在一些条件下,如果没有对齐会导致数据不同步现象).依赖cpu,平台和编译器的不同.一些cpu要求较高(这句话说的不准确,但是确实依赖cpu的不同),而有些平台已经优化内存对齐问题,不同编译器的对齐模数不同.总
-
详解C/C++内存区域划分(简而易懂)
C语言在内存中一共分为如下几个区域,分别是: 1. 内存栈区: 存放局部变量名: 2. 内存堆区: 存放new或者malloc出来的对象: 3. 常数区: 存放局部变量或者全局变量的值: 4. 静态区: 用于存放全局变量或者静态变量: 5. 代码区:二进制代码. 知道如上一些内存分配机制,有助于我们理解指针的概念. C/C++不提供垃圾回收机制,因此需要对堆中的数据进行及时销毁,防止内存泄漏,使用free和delete销毁new和malloc申请的堆内存,而栈内存是动态释放. C/C++内存区域
-
JVM内存区域划分相关原理详解
学过C语言的朋友都知道C编译器在划分内存区域的时候经常将管理的区域划分为数据段和代码段,数据段包括堆.栈以及静态数据区.那么在Java语言当中,内存又是如何划分的呢? 由于Java程序是交由JVM执行的,所以我们在谈Java内存区域划分的时候事实上是指JVM内存区域划分.在讨论JVM内存区域划分之前,先来看一下Java程序具体执行的过程: 如上图所示,首先Java源代码文件(.java后缀)会被Java编译器编译为字节码文件(.class后缀),然后由JVM中的类加载器加载各个类的字节码文件,加
-
Java虚拟机内存区域划分详解
在谈 JVM 内存区域划分之前,我们先来看一下 Java 程序的具体执行过程,我画了一幅图. Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完毕后,交给执行引擎执行.在整个执行的过程中,JVM 会用一块空间来存储程序执行期间需要用到的数据,这块空间一般被称为运行时数据区,也就是常说的 JVM 内存. 所以,当我们在谈 JVM 内存区域划分的时候,其实谈的就是这块空间--运行时数据区. 大家应该对官方出品的<Java 虚拟机规范>有所了解吧?了解这个规范可
-
详解Java的内存模型
JVM的内存模型 Java "一次运行,到处编译" 的真面目 说JVM内存模型之前,先聊一个老生常谈的问题,为什么Java可以 "一次编译,到处运行",这个话题最直接的答案就是,因为Java有JVM啊,解释这个答案之前,我想先回顾一下一个语言被编译的过程: 一般编程语言的编译过程大抵就是,编译--连接--执行,这里的编译就是,把我们写的源代码,根据语义语法进行翻译,形成目标代码,即汇编码.再由汇编程序翻译成机器语言(可以理解为直接运行于硬件上的01语言):然后进行连
-
浅谈Java内存区域划分和内存分配策略
如果不知道,类的静态变量存储在那? 方法的局部变量存储在那? 赶快收藏 Java内存区域主要可以分为共享内存,堆.方法区和线程私有内存,虚拟机栈.本地方法栈和程序计数器.如下图所示,本文将详细讲述各个区域,同时也会讲述创建对象过程,内存分配策略, 和对象访问定位原理.觉得写得好的,可以点个收藏,绝对不亏. Java内存区域 程序计数器 程序计数器,可以看作程序当前线程所执行的字节码行号指示器.字节码解释器工作时就是通过改变计数器的值来选取下一条需要执行的字节码指令,分支.循环.跳转.异常处理都需
-
详解Swift的内存管理
内存管理 和OC一样, 在Swift中也是采用基于引用计数的ARC内存管理方案(针对堆空间的内存管理) 在Swift的ARC中有三种引用 强引用(strong reference):默认情况下,代码中涉及到的引用都是强引用 弱引用(weak reference):通过weak定义弱引用 无主引用(unowned reference):通过unowned定义无主引用 weak 弱引用(weak reference):通过weak定义弱引用必须是可选类型的var,因为实例销毁后,ARC会自动将弱引用
-
详解python的内存分配机制
开始 作为一个实例,让我们创建四个变量并为其赋值: variable1 = 1 variable2 = "abc" variable3 = (1,2) variable4 = ['a',1] #打印他们的ids print('Variable1: ', id(variable1)) print('Variable2: ', id(variable2)) print('Variable3: ', id(variable3)) print('Variable4: ', id(variabl
-
详解Java volatile 内存屏障底层原理语义
目录 一.volatile关键字介绍及底层原理 1.volatile的特性(内存语义) 2.volatile底层原理 二.volatile--可见性 三.volatile--无法保证原子性 四.volatile--禁止指令重排 1.指令重排 2.as-if-serial语义 五.volatile与内存屏障(Memory Barrier) 1.内存屏障(Memory Barrier) 2.volatile的内存语义实现 六.JMM对volatile的特殊规则定义 一.volatile关键字介绍及底
-
Java详解线上内存暴涨问题定位和解决方案
前因: 因为REST规范,定义资源获取接口使用GET请求,参数拼接在url上. 如果按上述定义,当参数过长,超过tomcat默认配置 max-http-header-size :8kb 会报一下错误信息: Request header is too large 可以修改springboot配置,调整请求头大小 server: max-http-header-size: xxx 后果: 如果max-http-header-size设置过大,会导致接口吞吐下降,jvm oom,内存泄漏. 因为tom
-
详解CLR的内存分配和回收机制
一.CLR CLR:即公共语言运行时(Common Language Runtime),是中间语言(IL)的运行时环境,负责将编译生成的MSIL编译成计算机可以识别的机器码,负责资源管理(内存分配和垃圾回收等). 可能有人会提问:为什么不直接编译成机器码,而要先编译成IL,然后在编译成机器码呢? 原因是:计算机的操作系统不同(分为32位和64位),接受的计算机指令也是不同的,在不同的操作系统中就要进行不同的编译,写出的代码在不同的操作系统中要进行不同的修改.中间增加了IL层,不管是什么操作系统,