pytorch LayerNorm参数的用法及计算过程
说明
LayerNorm中不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响。
LayerNorm参数
torch.nn.LayerNorm(
normalized_shape: Union[int, List[int], torch.Size],
eps: float = 1e-05,
elementwise_affine: bool = True)
normalized_shape
如果传入整数,比如4,则被看做只有一个整数的list,此时LayerNorm会对输入的最后一维进行归一化,这个int值需要和输入的最后一维一样大。
假设此时输入的数据维度是[3, 4],则对3个长度为4的向量求均值方差,得到3个均值和3个方差,分别对这3行进行归一化(每一行的4个数字都是均值为0,方差为1);LayerNorm中的weight和bias也分别包含4个数字,重复使用3次,对每一行进行仿射变换(仿射变换即乘以weight中对应的数字后,然后加bias中对应的数字),并会在反向传播时得到学习。
如果输入的是个list或者torch.Size,比如[3, 4]或torch.Size([3, 4]),则会对网络最后的两维进行归一化,且要求输入数据的最后两维尺寸也是[3, 4]。
假设此时输入的数据维度也是[3, 4],首先对这12个数字求均值和方差,然后归一化这个12个数字;weight和bias也分别包含12个数字,分别对12个归一化后的数字进行仿射变换(仿射变换即乘以weight中对应的数字后,然后加bias中对应的数字),并会在反向传播时得到学习。
假设此时输入的数据维度是[N, 3, 4],则对着N个[3,4]做和上述一样的操作,只是此时做仿射变换时,weight和bias被重复用了N次。
假设此时输入的数据维度是[N, T, 3, 4],也是一样的,维度可以更多。
注意:显然LayerNorm中weight和bias的shape就是传入的normalized_shape。
eps
归一化时加在分母上防止除零。
elementwise_affine
如果设为False,则LayerNorm层不含有任何可学习参数。
如果设为True(默认是True)则会包含可学习参数weight和bias,用于仿射变换,即对输入数据归一化到均值0方差1后,乘以weight,即bias。
LayerNorm前向传播(以normalized_shape为一个int举例)
1、如下所示输入数据的shape是(3, 4),此时normalized_shape传入4(输入维度最后一维的size),则沿着最后一维(沿着最后一维的意思就是对最后一维的数据进行操作)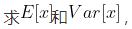 并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即
并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即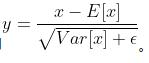
tensor = torch.FloatTensor([[1, 2, 4, 1],
[6, 3, 2, 4],
[2, 4, 6, 1]])
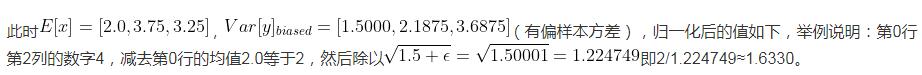
[[-0.8165, 0.0000, 1.6330, -0.8165], [ 1.5213, -0.5071, -1.1832, 0.1690], [-0.6509, 0.3906, 1.4321, -1.1717]]
2、如果elementwise_affine==True,则对归一化后的batch进行仿射变换,即乘以模块内部的weight(初值是[1., 1., 1., 1.])然后加上模块内部的bias(初值是[0., 0., 0., 0.]),这两个变量会在反向传播时得到更新。
3、如果elementwise_affine==False,则LayerNorm中不含有weight和bias两个变量,只做归一化,不会进行仿射变换。
总结
在使用LayerNorm时,通常只需要指定normalized_shape就可以了。
补充:【Pytorch】F.layer_norm和nn.LayerNorm到底有什么区别?
背景
最近在做视频方向,处理的是时序特征,就想着能不能用Batch Normalization来做视频特征BN层?在网上查阅资料发现,时序特征并不能用Batch Normalization,因为一个batch中的序列有长有短。
此外,BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。
Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。
对于RNN等时序模型,有时候同一个batch内部的训练实例长度不一(不同长度的句子),则不同的时态下需要保存不同的统计量,无法正确使用BN层,只能使用Layer Normalization。
查阅Layer Normalization(下述LN)后发现,这东西有两种用法,一个是F.layer_norm,一个是torch.nn.LayerNorm,本文探究他们的区别。
F.layer_norm
用法
F.layer_norm(x, normalized_shape, self.weight.expand(normalized_shape), self.bias.expand(normalized_shape))
其中:
x是输入的Tensor
normalized_shape是要归一化的维度,可以是x的后若干维度
self.weight.expand(normalized_shape),可选参数,自定义的weight
self.bias.expand(normalized_shape),可选参数,自定义的bias
示例
很容易看出来,跟F.normalize基本一样,没有可学习的参数,或者自定义参数。具体使用示例如下:
import torch.nn.functional as F
input = torch.tensor(a)
y = F.layer_norm(input,(4,))
print(y)
#####################输出################
tensor([[[-0.8095, -1.1224, 1.2966, 0.6354],
[-1.0215, -0.9661, 0.8387, 1.1488],
[-0.3047, 1.0412, -1.4978, 0.7613]],
[[ 0.4605, 1.2144, -1.5122, -0.1627],
[ 1.5676, 0.1340, -1.0471, -0.6545],
[ 1.5388, -0.3520, -1.2273, 0.0405]]])
添加缩放:
w = torch.tensor([1,1,2,2])
b = torch.tensor([1,1,1,1])
y = F.layer_norm(input,(4,),w,b)
print(y)
#########################输出######################
tensor([[[ 0.1905, -0.1224, 3.5931, 2.2708],
[-0.0215, 0.0339, 2.6775, 3.2976],
[ 0.6953, 2.0412, -1.9956, 2.5225]],
[[ 1.4605, 2.2144, -2.0243, 0.6746],
[ 2.5676, 1.1340, -1.0942, -0.3090],
[ 2.5388, 0.6480, -1.4546, 1.0810]]])
nn.LayerNorm
用法
torch.nn.LayerNorm(
normalized_shape: Union[int, List[int], torch.Size],
eps: float = 1e-05,
elementwise_affine: bool = True)
normalized_shape: 输入尺寸, [∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
示例
elementwise_affine如果设为False,则LayerNorm层不含有任何可学习参数。
如果设为True(默认是True)则会包含可学习参数weight和bias,用于仿射变换,即对输入数据归一化到均值0方差1后,乘以weight,即bias。
import torch input = torch.randn(2,3,2,2) import torch.nn as nn #取消仿射变换要写成 #m = nn.LayerNorm(input.size()[1:], elementwise_affine=False) m1 = nn.LayerNorm(input.size()[1:])#input.size()[1:]为torch.Size([3, 2, 2]) output1 = m1(input) #只normalize后两个维度 m2 = nn.LayerNorm([2,2]) output2 = m2(input) #只normalize最后一个维度 m3 = nn.LayerNorm(2) output3 = m3(input)
总结
F.layer_norm中没有可学习参数,而nn.LayerNorm有可学习参数。当elementwise_affine设为False时,nn.LayerNorm退化为F.layer_norm。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pytorch 一行代码查看网络参数总量的实现
大家还是直接看代码吧~ netG = Generator() print('# generator parameters:', sum(param.numel() for param in netG.parameters())) netD = Discriminator() print('# discriminator parameters:', sum(param.numel() for param in netD.parameters())) 补充:PyTorch查看网络模型的参数量PARA
-
pytorch 优化器(optim)不同参数组,不同学习率设置的操作
optim 的基本使用 for do: 1. 计算loss 2. 清空梯度 3. 反传梯度 4. 更新参数 optim的完整流程 cifiron = nn.MSELoss() optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9) for i in range(iters): out = net(inputs) loss = cifiron(out,label) optimiter.zero_grad() # 清空之前
-
pytorch固定BN层参数的操作
背景: 基于PyTorch的模型,想固定主分支参数,只训练子分支,结果发现在不同epoch相同的测试数据经过主分支输出的结果不同. 原因: 未固定主分支BN层中的running_mean和running_var. 解决方法: 将需要固定的BN层状态设置为eval. 问题示例: 环境:torch:1.7.0 # -*- coding:utf-8 -*- import torch import torch.nn as nn import torch.nn.functional as F class
-
pytorch查看网络参数显存占用量等操作
1.使用torchstat pip install torchstat from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224)) 关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数.我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数. 2.使用torchsummary pip in
-
pytorch交叉熵损失函数的weight参数的使用
首先 必须将权重也转为Tensor的cuda格式: 然后 将该class_weight作为交叉熵函数对应参数的输入值. class_weight = torch.FloatTensor([0.13859937, 0.5821059, 0.63871904, 2.30220396, 7.1588294, 0]).cuda() 补充:关于pytorch的CrossEntropyLoss的weight参数 首先这个weight参数比想象中的要考虑的多 你可以试试下面代码 import torch im
-
Pytorch 统计模型参数量的操作 param.numel()
param.numel() 返回param中元素的数量 统计模型参数量 num_params = sum(param.numel() for param in net.parameters()) print(num_params) 补充:Pytorch 查看模型参数 Pytorch 查看模型参数 查看利用Pytorch搭建模型的参数,直接看程序 import torch # 引入torch.nn并指定别名 import torch.nn as nn import torch.nn.functio
-
pytorch 如何自定义卷积核权值参数
pytorch中构建卷积层一般使用nn.Conv2d方法,有些情况下我们需要自定义卷积核的权值weight,而nn.Conv2d中的卷积参数是不允许自定义的,此时可以使用torch.nn.functional.conv2d简称F.conv2d torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) F.conv2d可以自己输入且也必须要求自己输入卷积权值weig
-
pytorch LayerNorm参数的用法及计算过程
说明 LayerNorm中不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响. LayerNorm参数 torch.nn.LayerNorm( normalized_shape: Union[int, List[int], torch.Size], eps: float = 1e-05, elementwise_affine: bool = True) normalized_shape 如果传入整数,比如4,则被看做只有一个整数的li
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
pytorch中permute()函数用法补充说明(矩阵维度变化过程)
目录 一.前言 二.举例解释 1.permute(0,1,2) 2.permute(0,1,2) ⇒ permute(0,2,1) 3.permute(0,2,1) ⇒ permute(1,0,2) 4.permute(1,0,2) ⇒ permute(0,2,1) 三.写在最后 一.前言 之前写了篇torch中permute()函数用法文章,在详细的说一下permute函数里维度变化的详细过程 非常感谢@m0_46225327对本文案例更加细节补充 注意: 本文是这篇torch中permute
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-
Pytorch 中retain_graph的用法详解
用法分析 在查看SRGAN源码时有如下损失函数,其中设置了retain_graph=True,其作用是什么? ############################ # (1) Update D network: maximize D(x)-1-D(G(z)) ########################### real_img = Variable(target) if torch.cuda.is_available(): real_img = real_img.cuda() z = V
-
Pytorch之Variable的用法
1.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子,而tensor是鸡蛋,鸡蛋应该放在篮子里才能方便拿走(定义variable时一个参数就是tensor) Variable这个篮子里除了装了tensor外还有requires_grad参数,表示是否需要对其求导,默认为False Variable这个篮子呢,自身有一些属性 比如grad,梯度vari
-
基于pytorch中的Sequential用法说明
class torch.nn.Sequential(* args) 一个时序容器.Modules 会以他们传入的顺序被添加到容器中.当然,也可以传入一个OrderedDict. 为了更容易的理解如何使用Sequential, 下面给出了一个例子: # Example of using Sequential model = nn.Sequential( nn.Conv2d(1,20,5), nn.ReLU(), nn.Conv2d(20,64,5), nn.ReLU() ) # Example o
-
pytorch中的weight-initilzation用法
pytorch中的权值初始化 官方论坛对weight-initilzation的讨论 torch.nn.Module.apply(fn) torch.nn.Module.apply(fn) # 递归的调用weights_init函数,遍历nn.Module的submodule作为参数 # 常用来对模型的参数进行初始化 # fn是对参数进行初始化的函数的句柄,fn以nn.Module或者自己定义的nn.Module的子类作为参数 # fn (Module -> None) – function t
-
pytorch中permute()函数用法实例详解
目录 前言 三维情况 变化一:不改变任何参数 变化二:1与2交换 变化三:0与1交换 变化四:0与2交换 变化五:0与1交换,1与2交换 变化六:0与1交换,0与2交换 总结 前言 本文只讨论二维三维中的permute用法 最近的Attention学习中的一个permute函数让我不理解 这个光说太抽象 我就结合代码与图片解释一下 首先创建一个三维数组小实例 import torch x = torch.linspace(1, 30, steps=30).view(3,2,5) # 设置一个三维
-
Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol