详解基于pycharm的requests库使用教程
目录
- requests库安装和导入
- requests库的get请求
- requests库的post请求
- requests库的代理
- requests库的cookie
- 自动识别验证码
requests库安装和导入
第一步:cmd打开命令行,使用如下命令安装requests库。
pip install requests
由于我的安装过了,所以如下:

如果提示你pip版本需要更新,按照提示的指令输入即可更新。
第二步:cmd使用如下命令,验证requests库安装完成。
pip list
第三步:在pycharm中,点击file——settings——project——python interpreter——点击+号——搜索requests——install package!

第四步:在你写的.py文件中,使用如下命令导入即可。
import requests
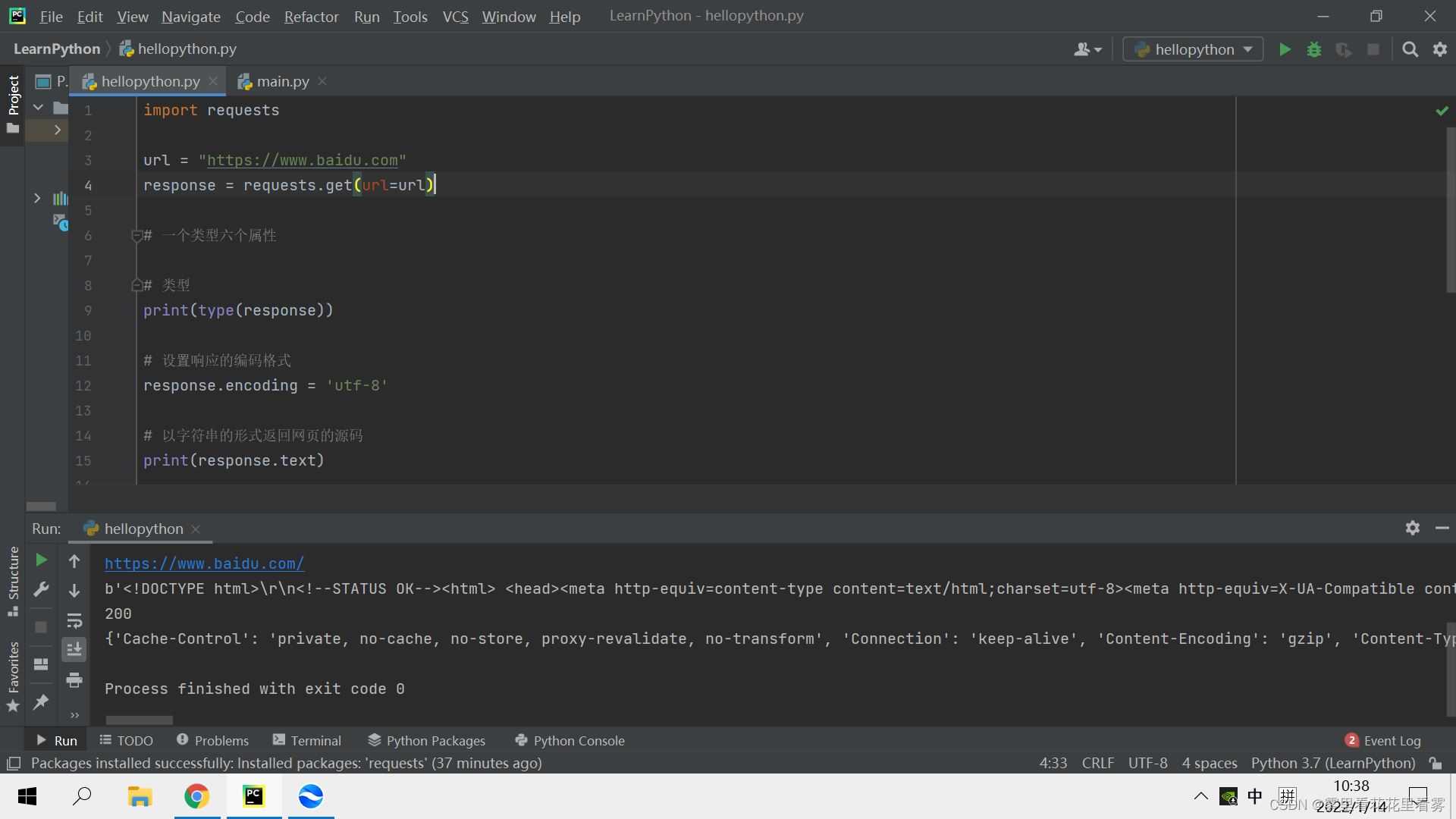
requests库的一个类型六个属性
import requests url = "https://www.baidu.com" response = requests.get(url=url) # 一个类型六个属性 # 类型 print(type(response)) # 设置响应的编码格式 response.encoding = 'utf-8' # 以字符串的形式返回网页的源码 print(response.text) # 返回一个url地址 print(response.url) # 返回的是二进制数据 print(response.content) # 返回相应的状态码 print(response.status_code) # 返回的响应头 print(response.headers)
输出结果如下:
<class 'requests.models.Response'>
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
post一般是表单请求,如果你直接在百度搜一个东西,那是get请求奥!
requests库的get请求
首先将代码写出来,然后根据代码给大家将对应的知识点,算是入门。
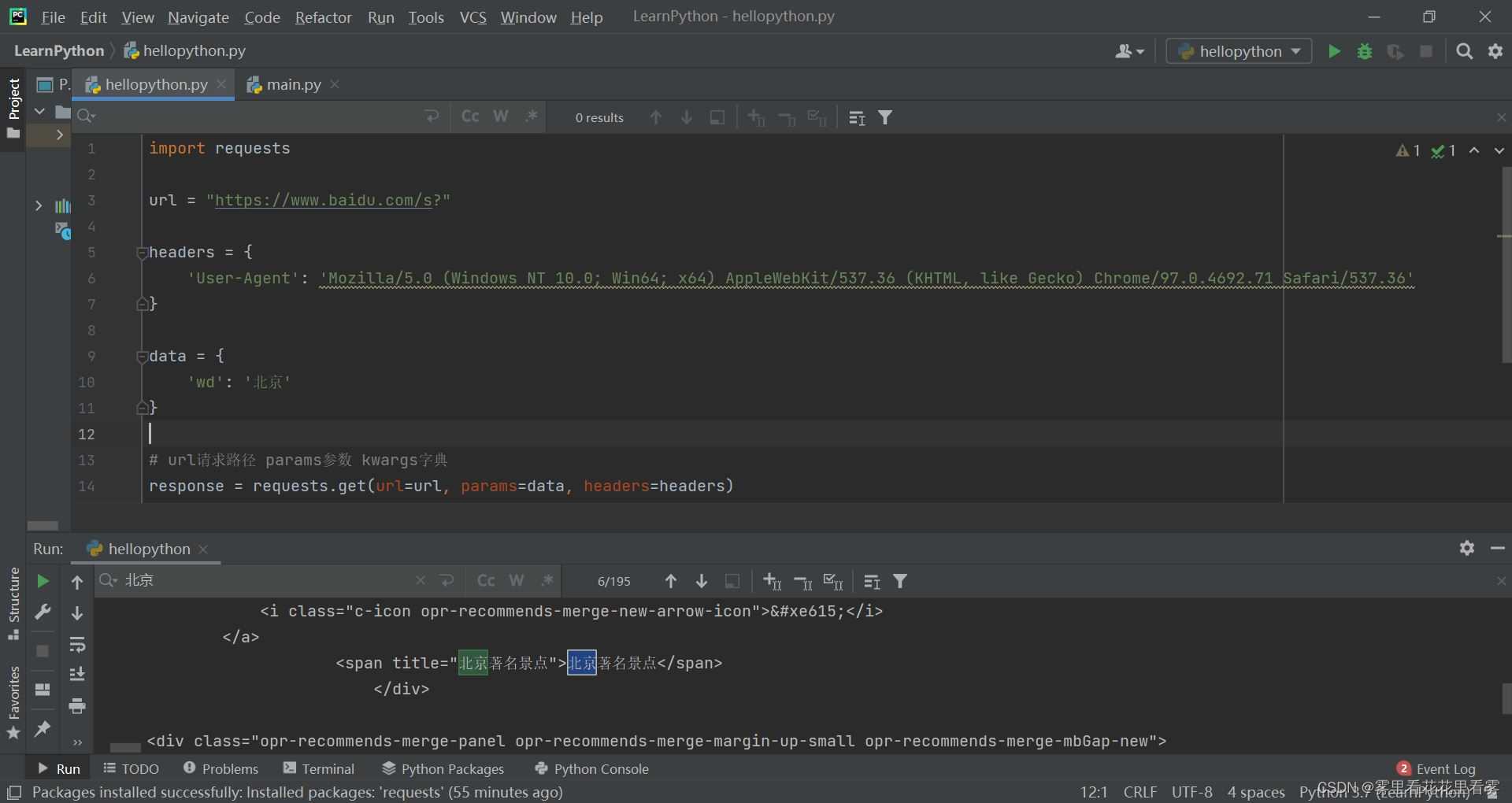
import requests
url = "https://www.baidu.com/s?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
data = {
'wd': '北京'
}
# url请求路径 params参数 kwargs字典
response = requests.get(url=url, params=data, headers=headers)
# 参数使用params传递,且参数无需url encode编码 ,且参数也不需要对象定制,请求资源路径中的?可加可不加
print(response.text)
第一步:首先来看requests库的get方法使用及参数含义。
response = requests.get(url=url, params=data, headers=headers)
url表示请求路径,params表示参数,kwargs表示字典。
参数使用params传递,且参数无需url encode编码 ,且参数也不需要对象定制,请求资源路径中的?可加可不加。
第二步:下面演示一下,这三个参数怎么传递。
接下来的讲解,学过前端的应该都知道怎么弄吧?
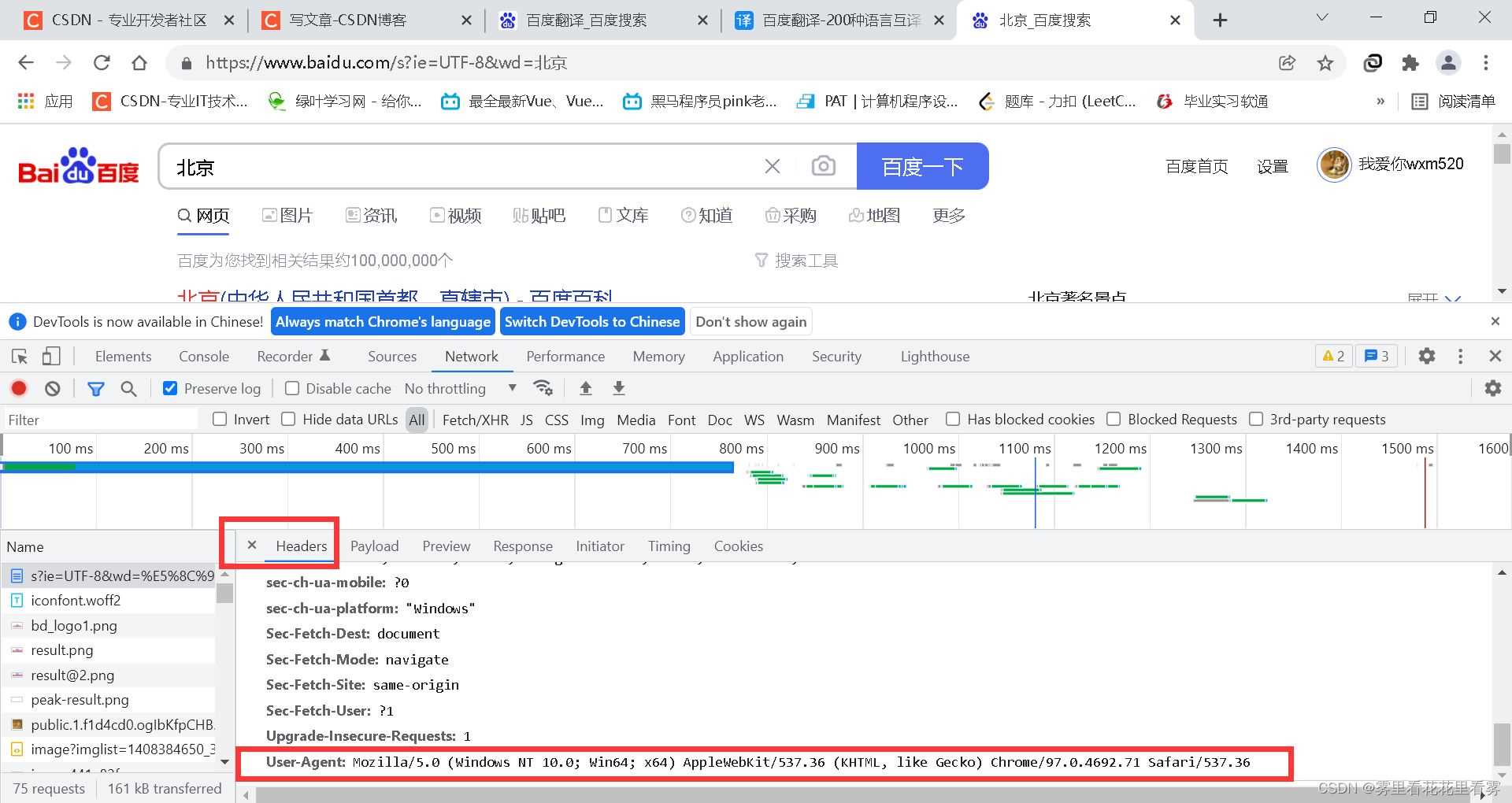
右键检查——选择如下——然后刷新
这个地方是我们请求的url!
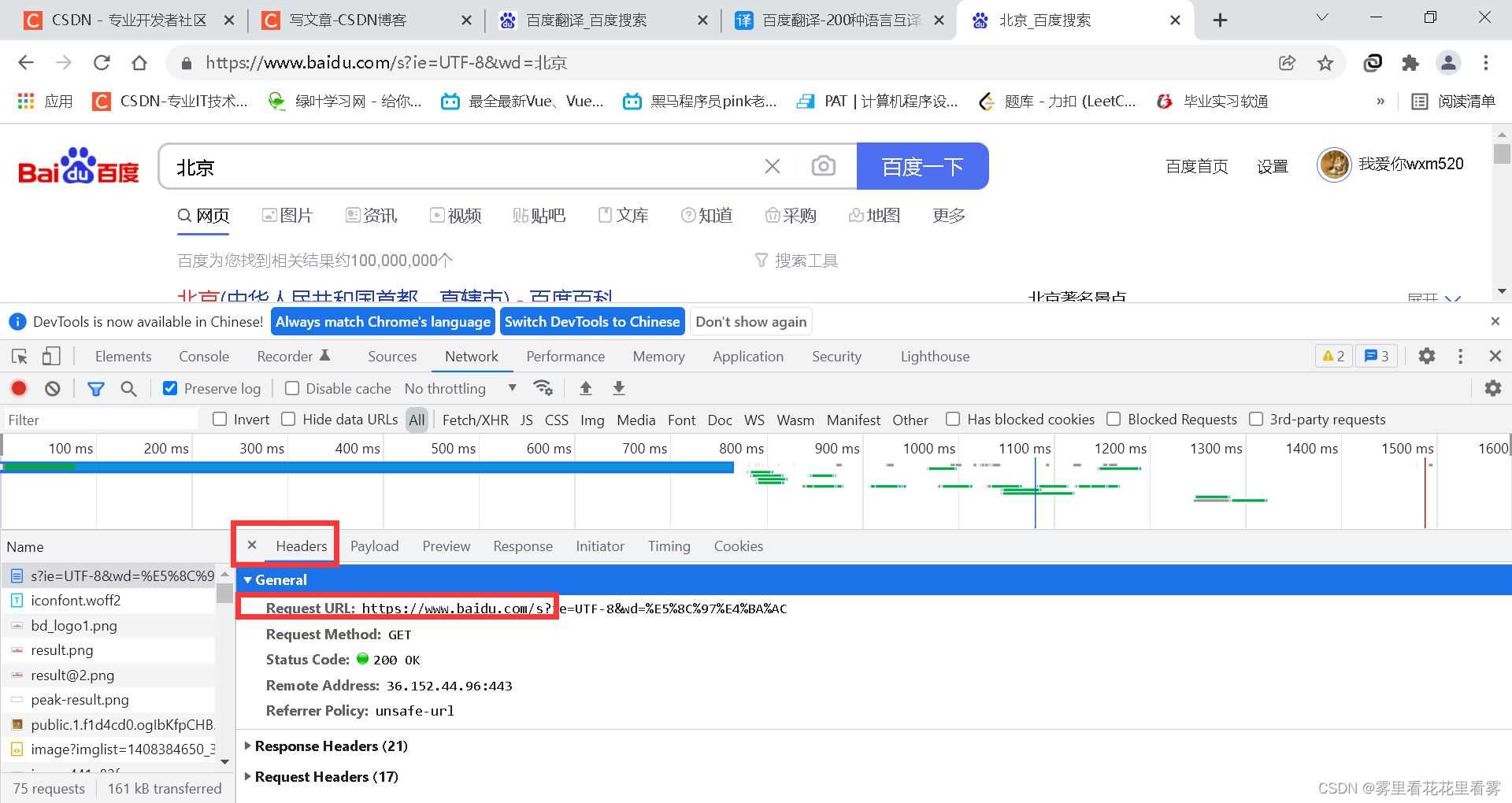
这个地方是我们传递的数据params!
可能很多人会找From Data,这个地方应该是PayLoad,注意一下!

这个地方是我们传递的字典!
选择下面的user agent,其中有我们的浏览器相关信息。
在上述中,应该注意,由于get的后两个其实都是用python中的字典的形式存储的,所以获取数据后,注意一下格式。
第三步:我们来看看有没有数据,可以在输出地方,使用ctrl + f来搜索验证我们想要的内容在不在。

requests库的post请求
首先将代码写出来,然后根据代码给大家将对应的知识点,算是入门。
import requests
url = "https://fanyi.baidu.com/sug"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url请求路径 data请求参数 kwargs字典
response = requests.post(url=url, data=data, headers=headers)
# 参数使用data传递,且参数无需url encode编码 ,且参数也不需要对象定制
print(response.text)
输出结果:
{"errno":0,"data":[{"k":"eye","v":"n. \u773c\u775b; \u89c6\u529b; \u773c\u72b6\u7269; \u98ce\u7eaa\u6263\u6263\u773c vt. \u5b9a\u775b\u5730\u770b; \u6ce8\u89c6; \u5ba1\u89c6; \u7ec6\u770b"},{"k":"Eye","v":"[\u4eba\u540d] \u827e; [\u5730\u540d] [\u82f1\u56fd] \u827e\u4f0a"},{"k":"EYE","v":"abbr. European Year of the Environment \u6b27\u6d32\u73af\u5883\u5e74; Iwas"},{"k":"eyed","v":"adj. \u6709\u773c\u7684"},{"k":"eyer","v":"n. \u6ce8\u89c6\u7684\u4eba"}]}
第一步:首先来看requests库的post方法使用及参数含义。
response = requests.post(url=url, data=data, headers=headers)
这里的参数和get方法还有点不同,我们想看详细的话可以这样看,在pycharm中选中方法,即可看到提示。
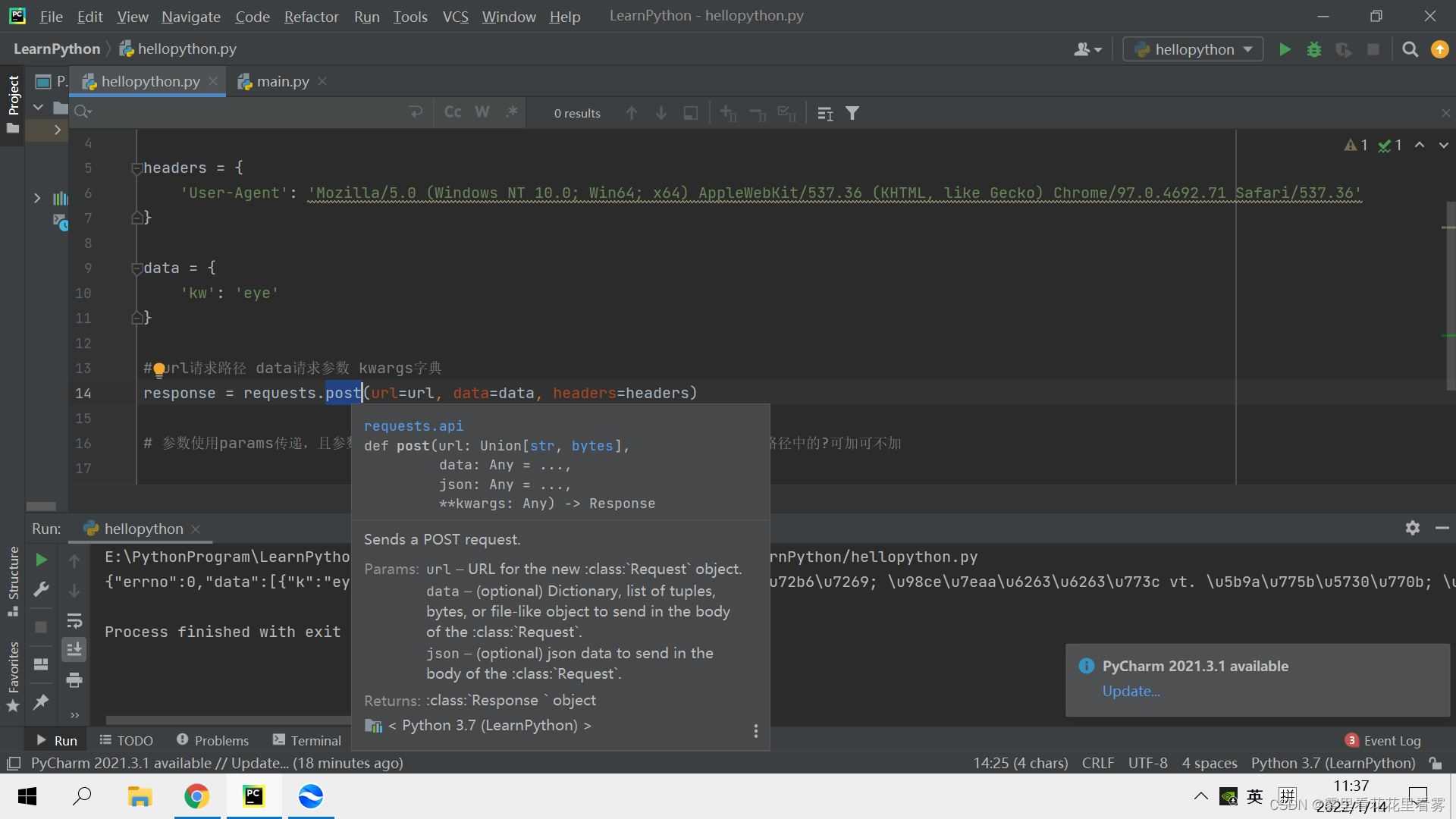
url表示的是请求路径,data表示的是请求参数,kwargs表示的是字典。
其实难点在于怎么找这个url奥!!即哪一个是我们想要的url!!下面以百度翻译为例!!
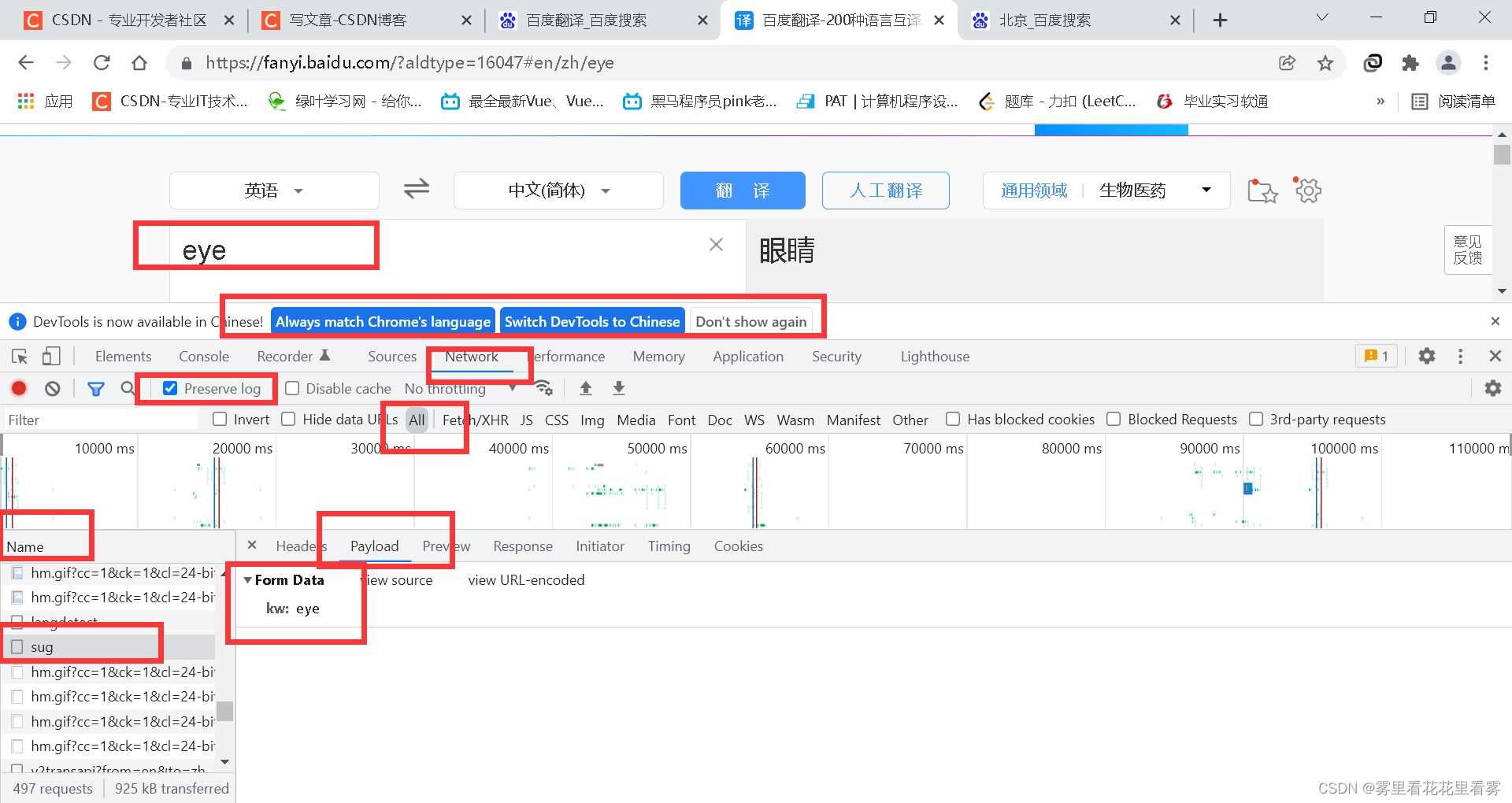
我圈起来的这些地方,一定要注意,选中Preserve log!!
就在左边的Name中找,如果其对应的这个PayLoad中的kw和我们搜索的一致,那就是的啦!!!
第二步,可能返回的数据我们也看不懂,那就转换成json的格式来看就行啦!!
import requests
import json
url = "https://fanyi.baidu.com/sug"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url请求路径 data请求参数 kwargs字典
response = requests.post(url=url, data=data, headers=headers)
obj = json.loads(response.text, encoding='utf-8')
print(obj)
输出结果:
{'errno': 0, 'data': [{'k': 'eye', 'v': 'n. 眼睛; 视力; 眼状物; 风纪扣扣眼 vt. 定睛地看; 注视; 审视; 细看'}, {'k': 'Eye', 'v': '[人名] 艾; [地名] [英国] 艾伊'}, {'k': 'EYE', 'v': 'abbr. European Year of the Environment 欧洲环境年; Iwas'}, {'k': 'eyed', 'v': 'adj. 有眼的'}, {'k': 'eyer', 'v': 'n. 注视的人'}]}
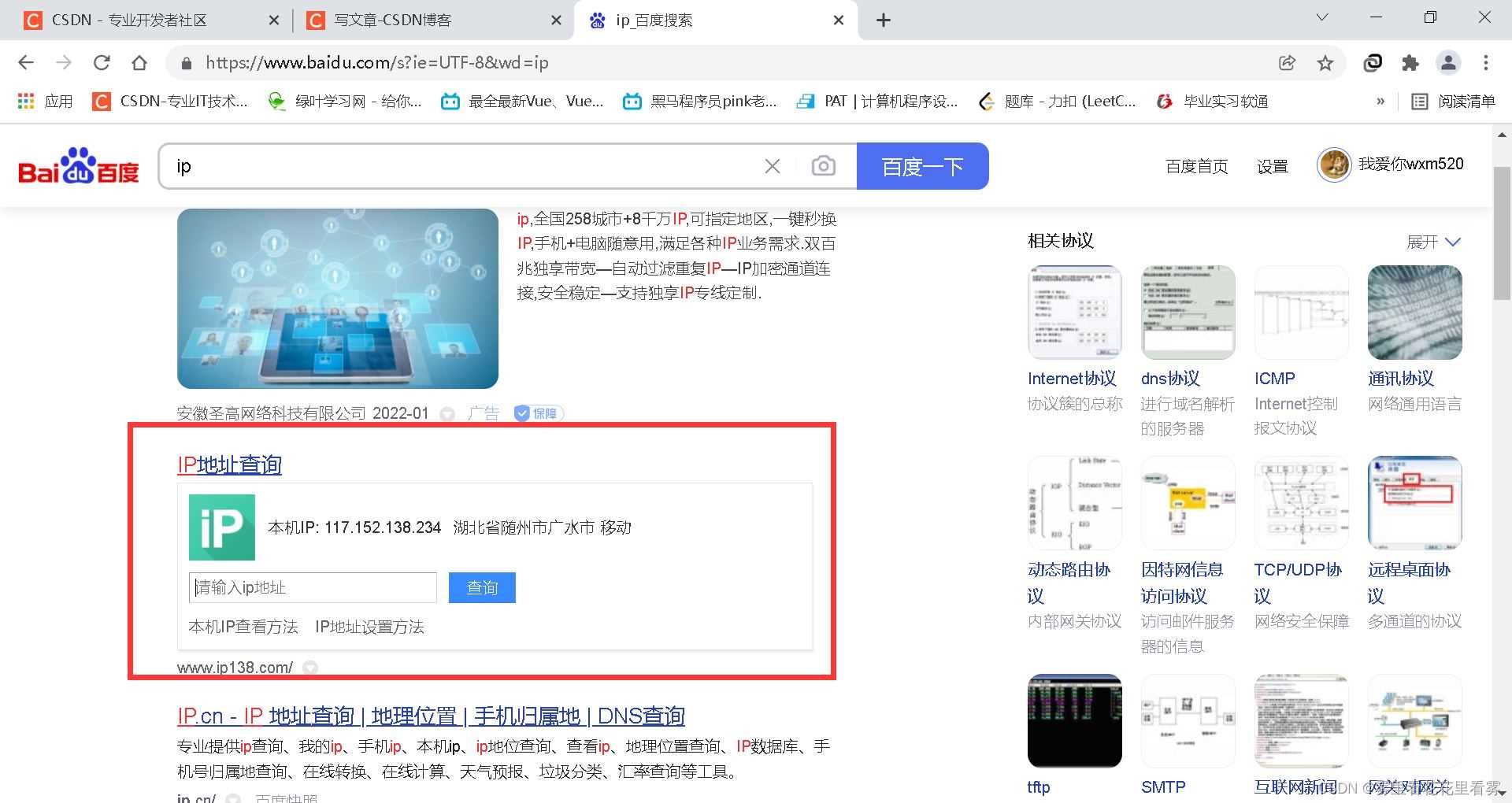
requests库的代理
代理主要处理的是,我们在模拟浏览器给服务器发送请求的时候,我们高速的快速的高频次的访问某个网站,那样的话网站会崩溃的,所以会把我们的ip封掉,那我们怎么办呢?换ip地址就好啦!
import requests
url = "https://www.baidu.com/s?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
data = {
'wd': 'ip'
}
response = requests.get(url=url, params=data, headers=headers)
with open('daili.html', 'w', encoding='utf-8') as fp:
fp.write(response.text)
就会发现写了这个文件!
requests库的cookie
我们是以古诗文网为例!
我们现在想要实现的功能就是,不用登录,直接进入内部的页面。
# 通过登录进入主页面
# 通过找登录接口 我们发现需要的参数很多
"""
__VIEWSTATE: 9Y4yHRQS2k2z739MJJ/8Z0sKfZNltkFId83Z8jCtY3g00xYgg9bsv5oK+KT5DypNl37KWa0IyB+uOwrRPBvTybqGLDdd0chyrWLxhhlHBeAGWL/SLTGYfOh5L1M=
__VIEWSTATEGENERATOR: C93BE1AE
from: http://so.gushiwen.cn/user/collect.aspx
email: 13237153218
pwd: wxm20010428
code: PDBG
denglu: 登录
"""
# 我们观察到__VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量
# __VIEWSTATE __VIEWSTATEGENERATOR 看不到的数据一般都是在页面的源码中
# 我们观察到其在页面源码中 所以我们需要获取页面源码 然后进行解析就可以获取了
# code是验证码
import requests
# 登录url页面
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
# 解析页面源码 然后获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'lxml')
# 获取__VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# print(viewstate)
# print(viewstategenerator)
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
# print(code)
code_url = 'https://so.gushiwen.cn' + code
# print(code_url)
# 获取验证码的图片后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码 就将这个值给code
# 怎么下载???
# import urllib.request
# 此处和后面的请求不是同一个请求 验证码就变了
# urllib.request.urlretrieve(url=code_url, filename='code.jpg')
# request里面有一个方法session() 通过session的返回值就能使请求变成一个对象
session = requests.session()
response_code = session.get(code_url)
# 注意此处使用二进制数据 因为我们要是图片的下载
content_code = response_code.content
with open('code.jpg', 'wb') as fp:
fp.write(content_code)
code_name = input('请输入验证码:')
# 点击登录
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '13237153218',
'pwd': 'wxm20010428',
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url=url_post, headers=headers, data=data_post)
with open('gushiwen.html', 'w', encoding='utf-8') as fp:
fp.write(response_post.text)
首先我们打开这个古诗文网的登录页面(假设已经都注册过了),现在我们要输入正确的账号,错误的密码,正确的验证码,点击登录,但是在提示后不要点击确定,否则页面会跳转,然后抓到这个登录所需要的参数。
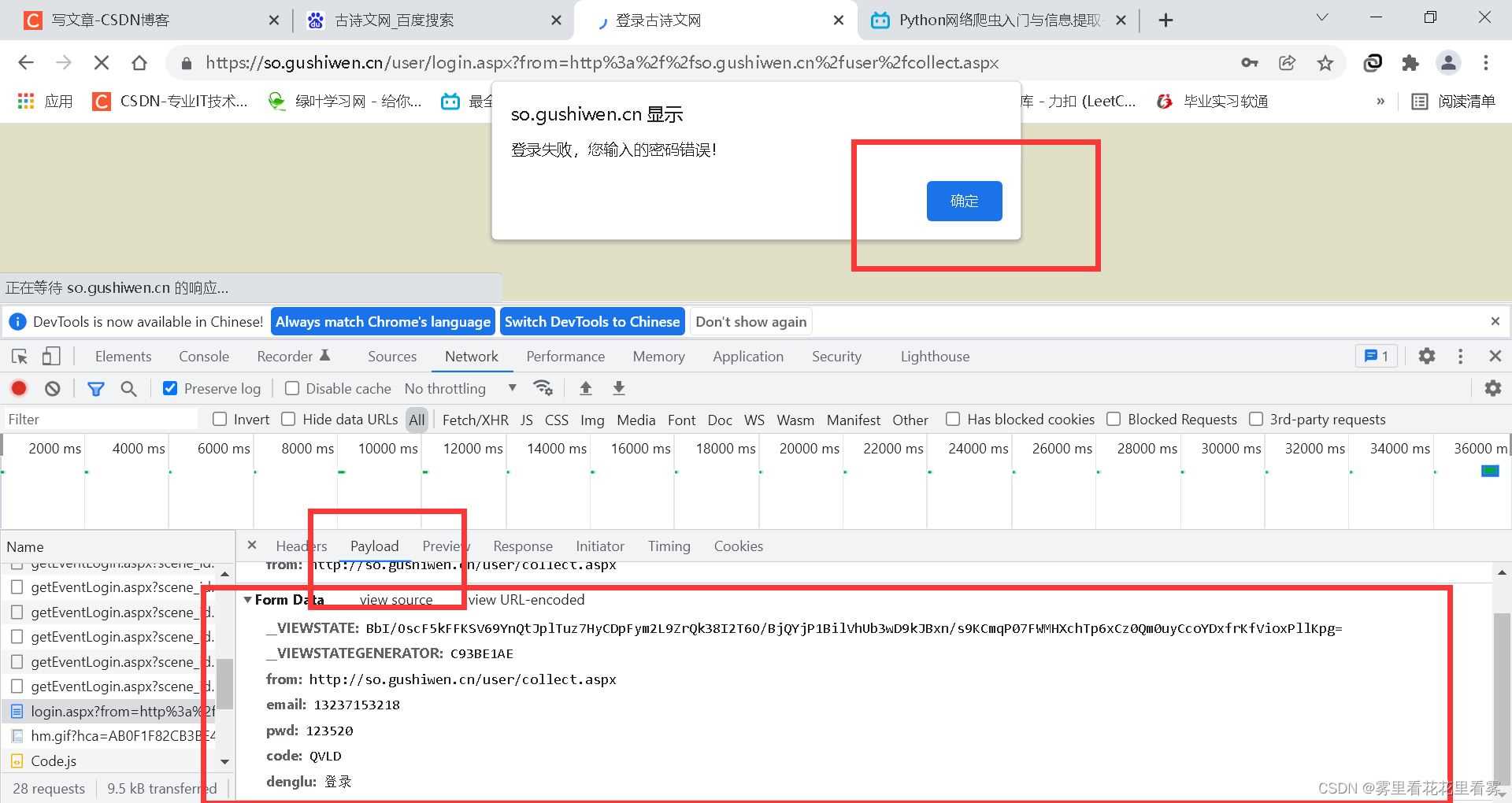
观察参数后,先找到变化的参数,再试图去获取变化的参数,而且一般这种看不见的参数,一般就是在源码中,我们点击查看源码,然后ctrl+F搜索看不见的参数,找到其位置。
然后我们模拟浏览器给服务器发送请求,获取网页源代码后,使用bs4解析源代码,然后相应变化的参数后,再发送请求即可!
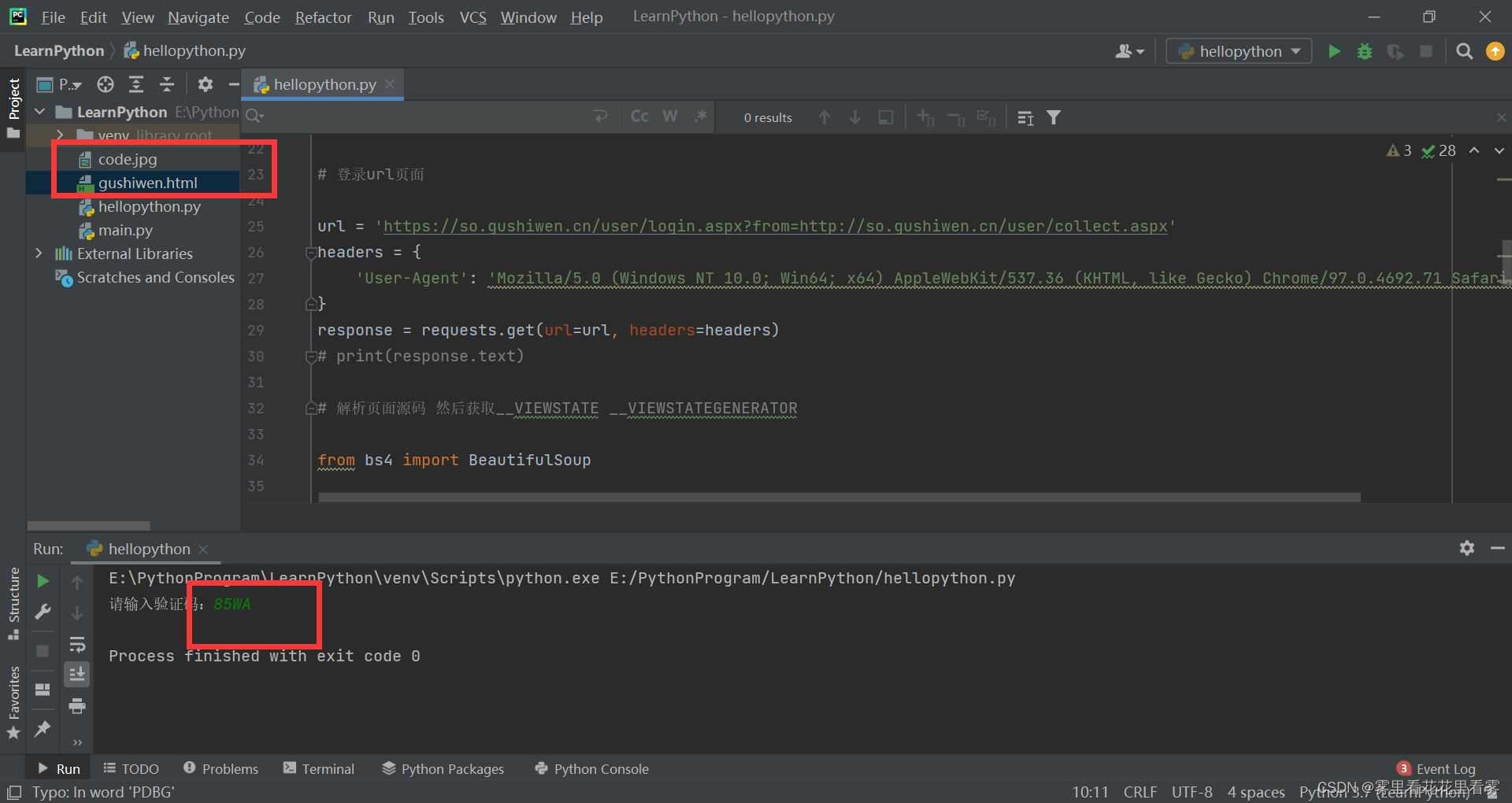
此处会生成两个文件,并且code.jpg,在运行的时候如果加载不出来,那就去项目的文件夹中查找。
自动识别验证码
超级鹰!下载python开发文档,并且将.py和一个图片复制到项目中!
打开后,看一下.py文件,更改用户名和密码上去!
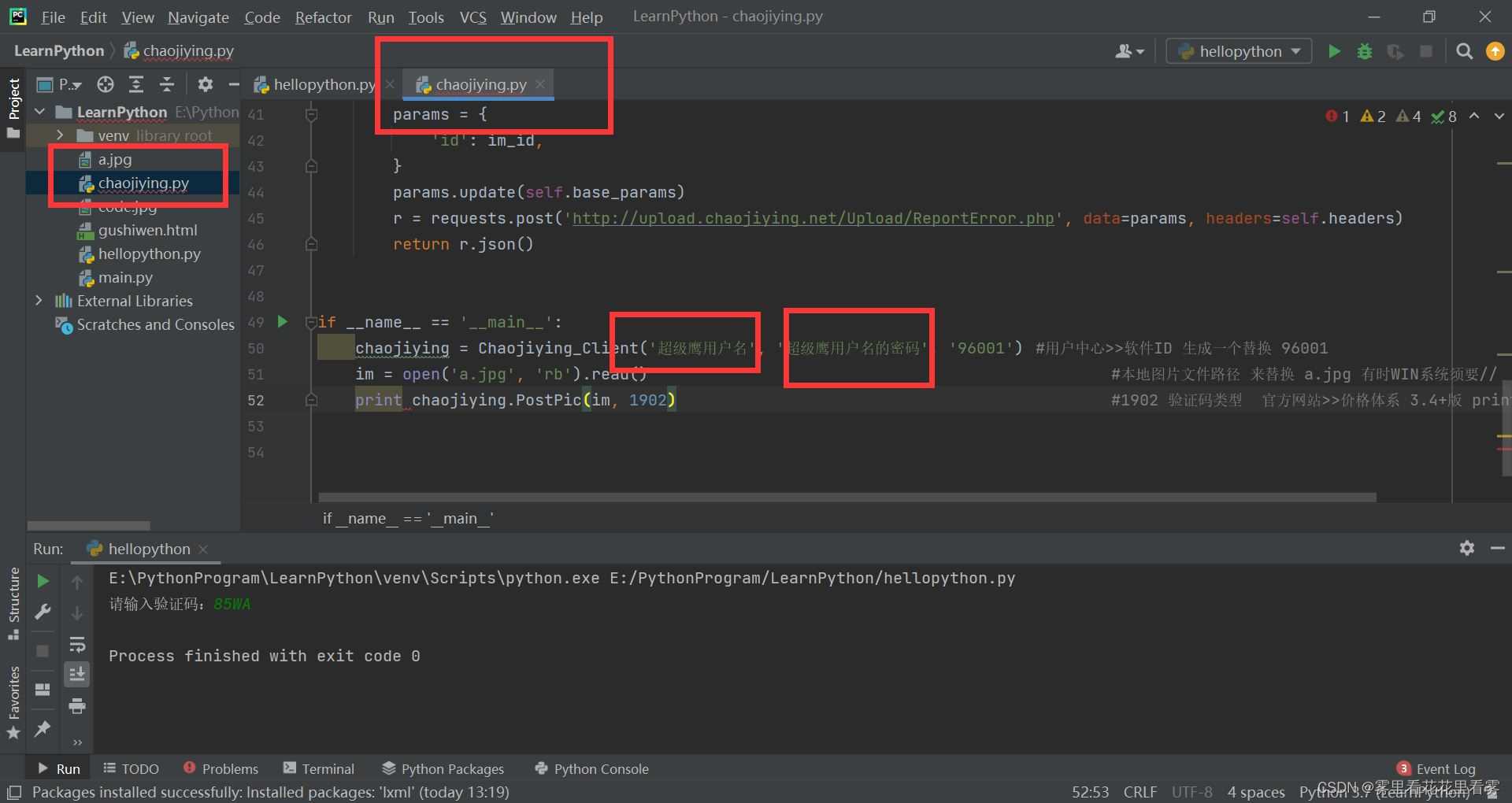
根据其中的提示更改这个用户ID
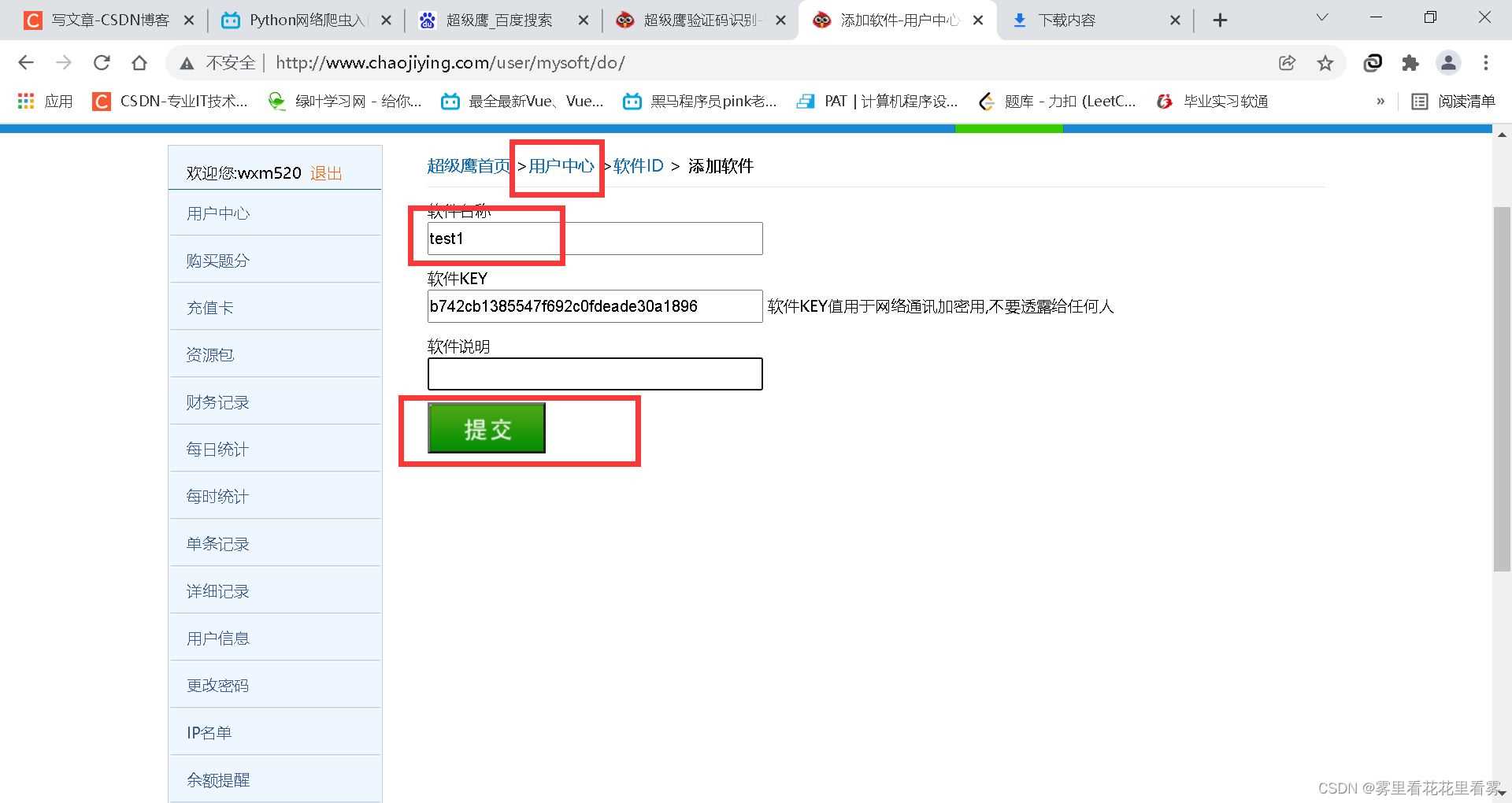
但是由于我没有充钱,没给我返回哈哈哈哈哈!
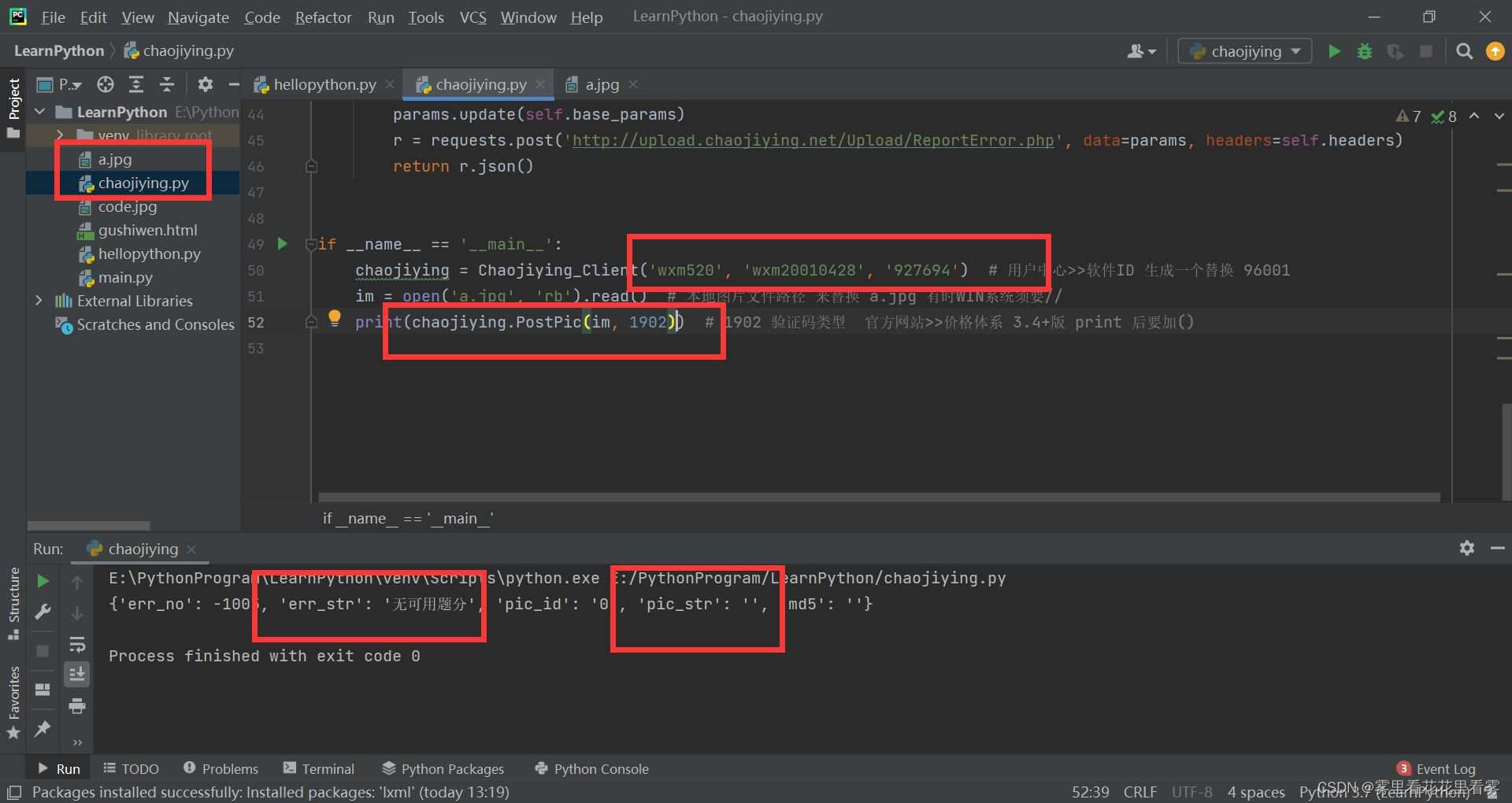
大家可以去第三方平台搞验证码识别平台!!
到此这篇关于详解基于pycharm的requests库使用教程的文章就介绍到这了,更多相关pycharm requests库 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

教你如何在Pycharm中导入requests模块
1.找到python的安装路径: 如果忘记可以在Pycharm运行如下代码: import sys pythonpath = sys.executable print(pythonpath) 路径如下: 2.打开CMD: 转到python路径下的Scripts文件夹下: 3.输入要下载的PiP命令:pip install requests 等待下载,出现Successfully,,,,则下载成功 4.出现错误的解决办法: 如果出现如上图错误,则继续在CMD上运行: 1.输入语句"pip3 ins
-
PyCharm安装第三方库如Requests的图文教程
PyCharm安装第三方库是十分方便的,无需pip或其他工具,平台就自带了这个功能而且操作十分简便.如下: [注]:本人PyCharm已汉化,若是英文版按括号中英文指示操作即可. 1. 打开软件,点击左上角"文件(File)"->"设置(setting)": 2. 选择弹出界面左上角的"项目(Project): PyCharm_Demo"->"project Interpreter": 3. 点击右上方"
-
使用PyCharm安装pytest及requests的问题
电脑环境:windows7 64位 python3.7 问题:在PyCharm中,使用setting下的project Interpreter安装pytest以及requests失败 解决方法:(亲测有效) 1.打开Gitbash,定位到python的安装目录:我的安装目录是 D:\pythonAnZhuang\Python37\Scripts 2.输入:pip install requests,等待安装完成 3.输入:pip install pytest,等待安装完成 4.检测是否安
-
教你Pycharm安装使用requests第三方库的详细教程
request库是python的第三方库,它也是目前公认的爬取网页最好的第三方库,其特点是:简单.简洁,甚至用一行代码就能从网页上获取相关资源. 安装python: 首先进入网站下载:点击打开链接(或自己输入网址https://www.python.org/downloads/),进入之后如下图,选择图中红色圈中区域进行下载. 安装pycharm: 首先从网站下载pycharm:点击打开链接(链接为:http://www.jetbrains.com/pycharm/download/#secti
-
详解基于pycharm的requests库使用教程
目录 requests库安装和导入 requests库的get请求 requests库的post请求 requests库的代理 requests库的cookie 自动识别验证码 requests库安装和导入 第一步:cmd打开命令行,使用如下命令安装requests库. pip install requests 由于我的安装过了,所以如下: 如果提示你pip版本需要更新,按照提示的指令输入即可更新. 第二步:cmd使用如下命令,验证requests库安装完成. pip list 第三步:在pyc
-
详解基于Jupyter notebooks采用sklearn库实现多元回归方程编程
一.导入excel文件和相关库 import pandas; import matplotlib; from pandas.tools.plotting import scatter_matrix; data = pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8') 显示文件大小 data.shape data 二.绘制多个变量两两之间的散点图:scatter_matrix()方法 #绘制多个变量两两之间的
-
详解基于Facecognition+Opencv快速搭建人脸识别及跟踪应用
人脸识别技术已经相当成熟,面对满大街的人脸识别应用,像单位门禁.刷脸打卡.App解锁.刷脸支付.口罩检测........ 作为一个图像处理的爱好者,怎能放过人脸识别这一环呢!调研开搞,发现了超实用的Facecognition!现在和大家分享下~~ Facecognition人脸识别原理大体可分为: 1.通过hog算子定位人脸,也可以用cnn模型,但本文没试过: 2.Dlib有专门的函数和模型,实现人脸68个特征点的定位.通过图像的几何变换(仿射.旋转.缩放),使各个特征点对齐(将眼睛.嘴等部位移
-
mysql数据库详解(基于ubuntu 14.0.4 LTS 64位)
1.mysql数据库的组成与相关概念 首先明白,mysql是关系型数据库,和非关系型数据库中最大的不同就是表的概念不一样. +整个mysql环境可以理解成一个最大的数据库:A +用mysql创建的数据库B是属于A的,是数据的仓库,相当于系统中的文件夹 +数据表C:是存放数据的具体场所,相当于系统中的文件,一个数据库B中包含若干个数据表C(注意此处的数据库B和A不一样) +记录D:数据表中的一行称为一个记录,因此,我们在创建数据表时,一定要创建一个id列,用于标识"这是第几条记录",id
-
详解基于Scrapy的IP代理池搭建
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
基于pycharm的beautifulsoup4库使用方法教程
1.beautifulsoup4库安装 第一步:在控制台输入如下命令,安装beautifulsoup4库. pip install beautifulsoup4 第二步:在控制台输入如下命令,验证是否成功安装beautifulsoup4库. 第三步:在pycharm中,点击file——settings——project——python interpreter——点击+号——搜索beautifulsoup4——install package! 这样就可以在.py文件中导入模块了! 2.beauti
-
详解基于django实现的webssh简单例子
本文介绍了详解基于django实现的webssh简单例子,分享给大家,具体如下: 说明 新建一个 django 程序,本文为 chain. 以下仅为简单例子,实际应用 可根据自己平台情况 进行修改. 打开首页后,需要输入1,后台去登录主机,然后返回登录结果. 正常项目 可以post 主机和登录账户,进行权限判断,然后去后台读取账户密码,进行登录. djang后台 需要安装以下模块 安装后会有一个版本号报错,不影响 channels==2.0.2 channels-redis==2.1.0 amq
-
zabbix 4.04 安装文档教程详解(基于CentOS 7.6)
1 安装前准备: 1.1 安装JDK 卸载openjdk # rpm -qa | grep java # yum remove java-1.8.0-openjdk # yum remove java-1.8.0-openjdk-headless 安装JDK包 # rpm -ivh jdk-8u191-linux-x64.rpm 1.2 安装依赖包 # yum install -y net-snmp net-snmp-devel OpenIPMI-devel libssh2-dev
-
详解基于Spring Data的领域事件发布
领域事件发布是一个领域对象为了让其它对象知道自己已经处理完成某个操作时发出的一个通知,事件发布力求从代码层面让自身对象与外部对象解耦,并减少技术代码入侵. 一. 手动发布事件 // 实体定义 @Entity public class Department implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer departmentId; @Enumerate
-
详解基于Mybatis-plus多租户实现方案
一.引言 小编先解释一下什么叫多租户,什么场景下使用多租户. 多租户是一种软件架构技术,在多用户的环境下,共有同一套系统,并且要注意数据之间的隔离性. 举个实际例子:小编曾经开发过一套支付宝程序,这套程序应用在不同的小程序上,当使用者访问不同,并且进入相对应的小程序页面,小程序则会把用户相关数据传输到小编这里.在传输的时候需要带上小程序标识(租户ID),以便小编将数据进行隔离. 当不同的租户使用同一套程序,这里就需要考虑一个数据隔离的情况. 数据隔离有三种方案: 1.独立数据库:简单来说就是一个